 OpenAI - ChatGPT, Sora
OpenAI - ChatGPT, Sora Google - Gemini, Nano Banana
Google - Gemini, Nano Banana Antrópico - Claude
Antrópico - Claude xAI - Grok
xAI - Grok Búsqueda profunda
Búsqueda profunda Alibaba - Reina
Alibaba - Reina ByteDance - Lo mejor de ByteDance
ByteDance - Lo mejor de ByteDance Todos los modelos
Todos los modelos Planes empresariales
Planes empresariales Desarrollo de aplicaciones de IA
Desarrollo de aplicaciones de IA API de traducción de IA
API de traducción de IA Servicio de SEO/GEO con IA
Servicio de SEO/GEO con IA Servicio de relaciones públicas geooptimizado
Servicio de relaciones públicas geooptimizado Servicio de extracción de datos web
Servicio de extracción de datos web OpenClaw
OpenClaw Las mejores herramientas de IA
Las mejores herramientas de IA Los mejores robots de IA
Los mejores robots de IA
 Acceso
Acceso



const { OpenAI } = require('openai');
const api = new OpenAI({
baseURL: 'https://api.ai.cc/v1',
apiKey: '',
});
const main = async () => {
const result = await api.chat.completions.create({
model: 'x-ai/grok-4-1-fast-non-reasoning',
messages: [
{
role: 'system',
content: 'You are an AI assistant who knows everything.',
},
{
role: 'user',
content: 'Tell me, why is the sky blue?'
}
],
});
const message = result.choices[0].message.content;
console.log(`Assistant: ${message}`);
};
main();
import os
from openai import OpenAI
client = OpenAI(
base_url="https://api.ai.cc/v1",
api_key="",
)
response = client.chat.completions.create(
model="x-ai/grok-4-1-fast-non-reasoning",
messages=[
{
"role": "system",
"content": "You are an AI assistant who knows everything.",
},
{
"role": "user",
"content": "Tell me, why is the sky blue?"
},
],
)
message = response.choices[0].message.content
print(f"Assistant: {message}")


Detalles del producto
🚀 Grok 4.1 API rápida: LLM ultrarrápido y sin razonamiento para flujos de trabajo eficientes
El Grok 4.1 API rápida y sin razonamiento xAI representa un avance significativo en la tecnología de modelos de lenguaje a gran escala, diseñado específicamente para una velocidad sin precedentes y la generación determinista de texto a texto. Este modelo destaca en entornos donde el razonamiento complejo no es el requisito principal, sino que la velocidad de salida y el procesamiento de contexto masivo son primordiales. Su diseño lo convierte en la solución ideal para flujos de trabajo de contenido de alto volumen, tareas por lotes rápidas y aplicaciones que exigen resultados consistentes con una latencia mínima.
🔧 Especificaciones técnicas principales
- Tipo de modelo: LLM (texto a texto) avanzado basado en transformadores
- Modo de funcionamiento: Sin razonamiento (proporciona una salida directa para una mayor velocidad)
- Estado latente: Inferencia instantánea con latencia extremadamente baja.
- Protocolos de seguridad: Utiliza pruebas adversarias y evaluaciones multilingües exhaustivas para garantizar un rendimiento sólido en idiomas como inglés, español, chino, japonés, árabe y ruso.
📊 Aspectos destacados y puntos de referencia de rendimiento
Evaluado según métricas clave, Grok 4.1 Fast Non-Rasoning demuestra consistentemente una precisión, seguridad y eficiencia operativa superiores. Supera a sus predecesores, mostrando una mayor precisión (indicada por puntuaciones más bajas) en pruebas que incluyen 500 preguntas biográficas mejoradas con herramientas de búsqueda web.
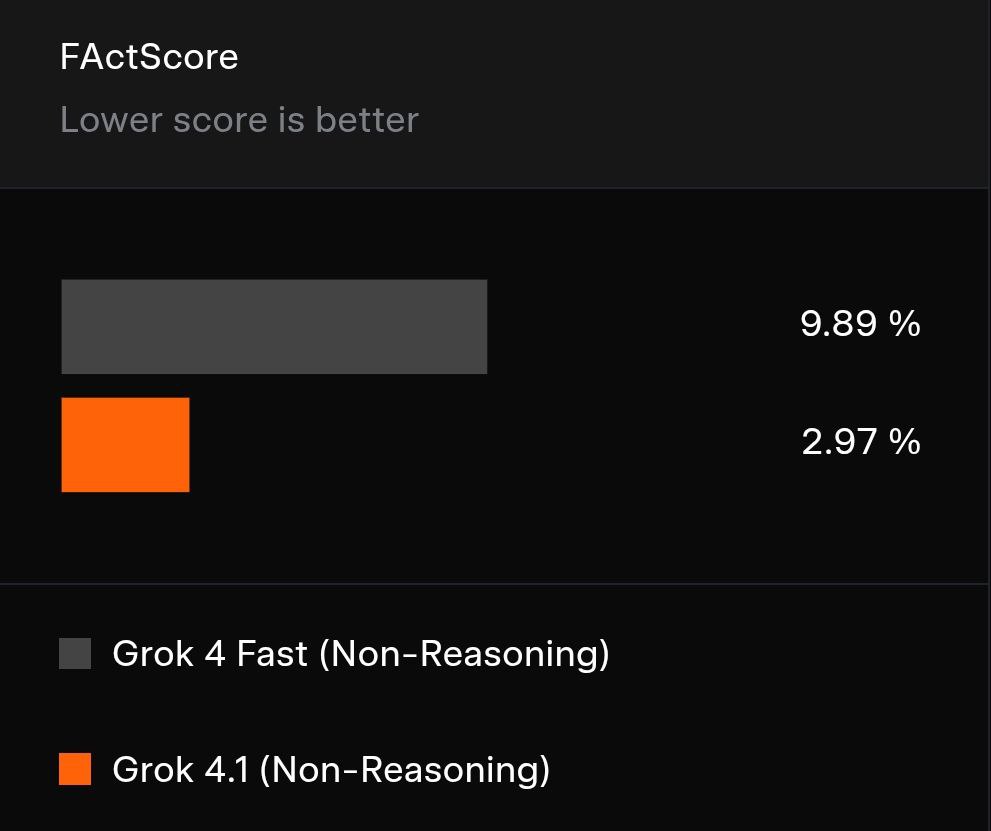
Representación visual de las mejoras en el rendimiento, que muestra una mayor precisión.
✅ Características distintivas
- 📜 Manejo de contextos ultralargos: Procesa sin problemas documentos y conversaciones de gran extensión sin pérdida de coherencia.
- 🔄 Resultados deterministas: Garantiza respuestas estables y predecibles ante indicaciones idénticas.
- 💭 Alta precisión fáctica: Optimizado para minimizar las alucinaciones y lograr la máxima precisión fáctica en consultas sencillas.
- ⚠️ Optimizado para la velocidad: Prioriza el procesamiento rápido y masivo, prescindiendo intencionadamente del uso de herramientas o de capacidades de razonamiento avanzadas.
- 🚨 Seguridad avanzada: Ofrece tasas de rechazo y de desbloqueo extremadamente bajas gracias a sus robustos mecanismos de seguridad.
💸 Estructura de precios de la API
- Tokens de entrada: 0,21 dólares por cada millón de tokens
- Tokens de salida: 0,53 dólares por cada millón de tokens
💡 Aplicaciones y casos de uso ideales
- 📝 Resumen extenso del documento: Resume rápidamente artículos de investigación extensos, documentos legales o informes.
- 💬 Procesamiento del historial conversacional: Anota y procesa de forma eficiente grandes volúmenes de registros de chat y datos conversacionales.
- 🔀 Transformación masiva de texto: Realizar tareas de reformateo, reformulación o extracción de datos de contenido a gran escala.
- 🎤 Transcripción y búsqueda automatizadas de reuniones: Genera transcripciones a partir de audio y permite realizar búsquedas rápidas en vastos archivos.
- 🤖 Chatbots de alto volumen: Potencie los chatbots de atención al cliente para que gestionen de forma eficiente las consultas sencillas y repetitivas.
💻 Ejemplo de código API (Python)
import openai client = openai.OpenAI( base_url="https://api.xai.com/v1", api_key="YOUR_API_KEY", # Reemplazar con tu clave API real ) completion = client.chat.completions.create( model="x-ai/grok-4-1-fast-non-reasoning", messages=[ {"role": "system", "content": "Eres un asistente útil."}, {"role": "user", "content": "Resume las características clave de Grok 4.1 Fast en menos de 50 palabras."} ], max_tokens=100 ) print(completion.choices[0].message.content) 🔍 Grok 4.1 Fast: Una visión general comparativa
Comprender las fortalezas únicas de Grok 4.1 Fast Non-Rasoning resulta más claro al compararlo con otros modelos de lenguaje líderes:
vs. Grok 4.1 Razonamiento: Grok 4.1 Fast prioriza la velocidad extrema y las respuestas deterministas, mientras que la variante "Reasoning" está diseñada para la lógica de varios pasos y una mayor profundidad analítica. Para obtener información más detallada, consulte la Documentación oficial del producto Grok 4.1.
vs. DeepSeek V3.1: Grok 4.1 Fast ofrece una capacidad significativamente mayor. Ventana de contexto de 2 millones de tokens, una enorme ventaja sobre los 128.000 tokens de DeepSeek V3.1, lo que lo hace superior para el procesamiento extenso de documentos.
vs. Claude 4: Grok 4.1 Fast proporciona una ventana de contexto sustancialmente más grande, procesando hasta 2 millones de tokens, mientras que Claude 4 suele operar en un contexto de entre 100.000 y 200.000 tokens.
vs. GPT-4o: GPT-4o es un modelo versátil de propósito general que destaca por su razonamiento robusto, creatividad y resolución avanzada de problemas. Grok 4.1 Fast, por el contrario, limita intencionadamente la complejidad para lograr una velocidad sin precedentes y resultados deterministas, lo que lo convierte en la opción preferida para tareas de alto rendimiento que no requieren razonamiento, donde no se necesitan las capacidades avanzadas de GPT-4o.
❓ Preguntas frecuentes (FAQ)
¿Qué es Grok 4.1 Fast Non-Raisoning?
Grok 4.1 Fast Non-Reasoning es un modelo de lenguaje de gran tamaño desarrollado por xAI, optimizado para la generación de texto ultrarrápida y determinista, así como para el procesamiento de contexto extenso. Está diseñado para tareas donde la velocidad y el alto rendimiento se priorizan sobre el razonamiento interno complejo.
¿Cuál es la ventana de contexto máxima compatible con Grok 4.1 Fast?
Grok 4.1 Fast Non-Rasoning admite una impresionante ventana de contexto de hasta 2 millones de tokens, lo que le permite procesar y comprender documentos y conversaciones extremadamente largos sin perder coherencia.
¿Cómo garantiza Grok 4.1 Fast la seguridad y la precisión?
Integra sólidos mecanismos de seguridad, incluyendo pruebas adversarias y evaluaciones multilingües. Esto garantiza una alta precisión en consultas sencillas y mantiene tasas de rechazo y de vulneración extremadamente bajas.
¿Qué tipos de aplicaciones se benefician más de Grok 4.1 Fast?
Es ideal para tareas como resumir documentos extensos, procesar historiales de chat amplios, transformar textos en masa, transcribir reuniones automáticamente y alimentar chatbots de interacción con el cliente sencillos y de alta rotación.
¿Cuál es el precio de la API para Grok 4.1 Fast?
La API tiene un precio de 0,21 dólares por cada millón de tokens de entrada y de 0,53 dólares por cada millón de tokens de salida, lo que ofrece una solución rentable para las necesidades de generación de texto a gran escala.
Campo de juegos de IA

