 OpenAI - ChatGPT, Sora
OpenAI - ChatGPT, Sora Google - Gemini, Nano Banana
Google - Gemini, Nano Banana Antrópico - Claude
Antrópico - Claude xAI - Grok
xAI - Grok Búsqueda profunda
Búsqueda profunda Alibaba - Reina
Alibaba - Reina ByteDance - Lo mejor de ByteDance
ByteDance - Lo mejor de ByteDance Todos los modelos
Todos los modelos Planes empresariales
Planes empresariales Desarrollo de aplicaciones de IA
Desarrollo de aplicaciones de IA API de traducción de IA
API de traducción de IA Servicio de SEO/GEO con IA
Servicio de SEO/GEO con IA Servicio de relaciones públicas geooptimizado
Servicio de relaciones públicas geooptimizado Servicio de extracción de datos web
Servicio de extracción de datos web OpenClaw
OpenClaw Las mejores herramientas de IA
Las mejores herramientas de IA Los mejores robots de IA
Los mejores robots de IA
 Acceso
Acceso



const { OpenAI } = require('openai');
const api = new OpenAI({
baseURL: 'https://api.ai.cc/v1',
apiKey: '',
});
const main = async () => {
const result = await api.chat.completions.create({
model: 'x-ai/grok-4-1-fast-reasoning',
messages: [
{
role: 'system',
content: 'You are an AI assistant who knows everything.',
},
{
role: 'user',
content: 'Tell me, why is the sky blue?'
}
],
});
const message = result.choices[0].message.content;
console.log(`Assistant: ${message}`);
};
main();
import os
from openai import OpenAI
client = OpenAI(
base_url="https://api.ai.cc/v1",
api_key="",
)
response = client.chat.completions.create(
model="x-ai/grok-4-1-fast-reasoning",
messages=[
{
"role": "system",
"content": "You are an AI assistant who knows everything.",
},
{
"role": "user",
"content": "Tell me, why is the sky blue?"
},
],
)
message = response.choices[0].message.content
print(f"Assistant: {message}")


Detalles del producto
Grok 4.1 Razonamiento rápido xAI representa un avance significativo en las capacidades de los modelos de IA, diseñados específicamente para tareas analíticas rápidas y de múltiples pasos, así como para el manejo integral del contexto. Este modelo avanzado es ideal para aplicaciones complejas en tiempo real, ofreciendo una eficiencia y precisión sin precedentes. Entre sus características distintivas se incluyen un funcionamiento único de modo dual, puntuaciones de razonamiento de primer nivel en pruebas comparativas y una arquitectura diseñada para impulsar tanto interfaces conversacionales rápidas como flujos de trabajo de agentes complejos.
Especificaciones técnicas: Impulsando la IA avanzada
- 🚀 Arquitectura: Basado en transformadores con capacidades avanzadas de razonamiento automatizado, lo que garantiza un procesamiento robusto e inteligente.
- 📚 Ventana de contexto: Un extenso hasta 2.000.000 de tokens, lo que permite un análisis profundo de documentos extensos y discursos complejos.
- ✍️ Longitud de salida: Capaz de generar hasta 30.000 tokens por salida, ideal para respuestas detalladas.
- 🛡️ Reducción de alucinaciones: Logros tres veces menos alucinaciones en consultas de búsqueda de información en comparación con versiones anteriores, reforzadas por una mejor integración web a través de activadores de búsqueda.
Referencias de rendimiento inigualables
Grok 4.1 muestra mejoras significativas Grok 4.1 supera a su predecesor, destacando especialmente en inteligencia emocional, escritura creativa y reduciendo drásticamente las alucinaciones. Domina constantemente las clasificaciones, demostrando avances sustanciales en razonamiento, creatividad y fiabilidad general. Evaluado rigurosamente mediante preferencias de usuario a ciegas y pruebas estandarizadas, Grok 4.1 es consistentemente superior a su predecesor, especialmente en inteligencia emocional, escritura creativa y reducción drástica de alucinaciones. Domina consistentemente las clasificaciones, demostrando avances sustanciales en razonamiento, creatividad y fiabilidad general. Evaluado rigurosamente mediante preferencias de usuario a ciegas y pruebas estandarizadas, Grok 4.1 es consistentemente superior. supera tanto a las versiones anteriores como a los modelos de la competencia..
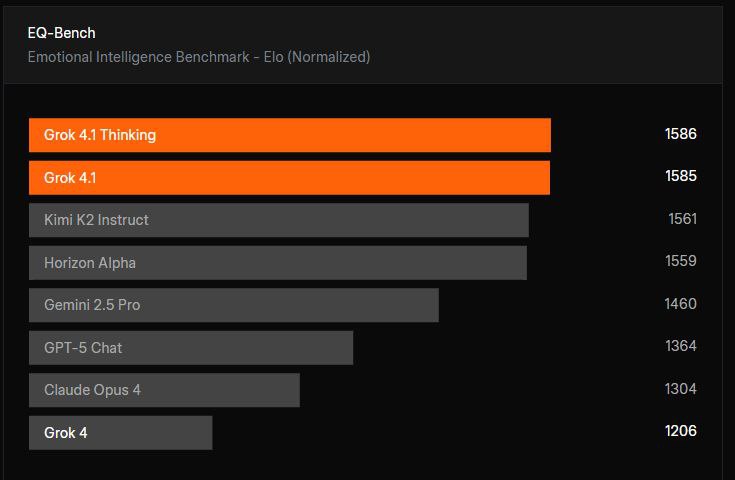
Características principales: ¿Qué hace que Grok 4.1 destaque?
- 💖 Capacidades emocionales y creativas mejoradas: Más en sintonía con la intención del usuario, proporcionando respuestas empáticas y basadas en la personalidad En juegos de rol y tareas creativas, optimizadas mediante aprendizaje por refuerzo para lograr un estilo y una alineación superiores.
- ✔️ Mejoras en la precisión de los datos: Los esfuerzos posteriores al entrenamiento minimizan significativamente las alucinaciones, especialmente en escenarios de búsqueda de información con herramientas de búsqueda integradas, lo que garantiza Resultados altamente fiables.
- 🔒 Capas de seguridad robustas: Incorpora políticas de rechazo exhaustivas para intenciones ilegales, filtros de entrada para temas restringidos y medidas de mitigación avanzadas contra el engaño (tasa de deshonestidad de alrededor del 0,46-0,49%) y la adulación (0,19-0,23%).
- 🌐 Resiliencia multilingüe y ante la adversidad: Evaluado exhaustivamente en varios idiomas, incluidos inglés, español y árabe; entrenado específicamente para resistir inyecciones rápidas y diversos daños causados por agentes químicos, lo que garantiza su aplicabilidad y seguridad a nivel mundial.
Precios de API: Rendimiento rentable
- 💲 Tokens de entrada: 0,21 dólares por cada millón de tokens – Altamente competitivo para el procesamiento de datos a gran escala.
- 💲 Tokens de salida: 0,53 dólares por cada millón de tokens – Precios eficientes para generar respuestas completas y detalladas.
Casos de uso versátiles para Grok 4.1
- 💡 Generación de contenido creativo: Crea sin esfuerzo publicaciones virales atractivas o relatos cortos cautivadores, inyectando una personalidad vibrante y estilo a narrativas como el "despertar" de Grok.
- 💡 Interacciones de apoyo emocional: Ofrecer una empatía matizada a las consultas personales, como respuestas reconfortantes ante el duelo por la pérdida de una mascota, fomentando así una conexión más profunda con los usuarios.
- 💡 Recuperación precisa de información: Ofrezca recomendaciones de viaje precisas (por ejemplo, los mejores lugares de San Francisco) con un mínimo de errores, utilizando la búsqueda integrada para obtener la información más actualizada.
- 💡 Juego de rol colaborativo: Mejore las sesiones de lluvia de ideas en equipo o las simulaciones educativas mediante interacciones de múltiples turnos impulsadas por una inteligencia emocional avanzada.
- 💡 Tareas de agente sofisticadas: Aborda desafíos complejos como el análisis de ciberseguridad o la resolución de problemas basada en protocolos con enfoques razonados y paso a paso, siempre dentro de los límites éticos.
- 💡 Asistencia multilingüe: Brindar soporte a una base de usuarios global en debates delicados, garantizando que se rechace el contenido dañino en todos los idiomas compatibles.
Integración de ejemplos de código
Grok 4.1 frente a los principales modelos de IA
Vs. Grok 4: Grok 4.1 logra una Reducción de casi 3 veces en la tasa de alucinaciones y un impresionante Aumento de 600 puntos en las calificaciones de escritura creativaAdemás, cuenta con una ventana de contexto más amplia y una inteligencia emocional significativamente mejorada en comparación con su predecesor.
Vs. GPT-4: Grok 4.1 ofrece una ventana de contexto mucho más grande y un modo de razonamiento especializado, lo que lo hace superior para tareas que exigen un contexto extenso y procesos de pensamiento transparentes. También demuestra mayor inteligencia emocional puntos de referencia.
Vs. Gemini 2.5 Pro: Grok 4.1 se diferencia por menores tasas de alucinaciones y una optimización superior para aplicaciones creativas y con gran carga emocional, mientras que Gemini 2.5 Pro podría conservar ventajas en pruebas de rendimiento específicas centradas en dominios concretos.
Vs. Claude 4 Opus: Grok 4.1 logra puntuaciones más altas en creatividad y compromiso emocional.Su opción de interacción en modo instantáneo proporciona tiempos de respuesta más rápidos en comparación con el énfasis de Claude en la seguridad y las salidas controladas.
Preguntas frecuentes (FAQ)
P: ¿Cuál es la principal ventaja de la capacidad de "Razonamiento rápido" de Grok 4.1?
A: La función de "Razonamiento rápido" permite a Grok 4.1 realizar razonamientos de varios pasos con baja latencia, lo que lo hace ideal para aplicaciones en tiempo real y tareas analíticas complejas donde las respuestas rápidas y precisas son fundamentales.
P: ¿Cómo maneja Grok 4.1 grandes cantidades de información?
A: Grok 4.1 está equipado con una ventana de contexto masiva de hasta 2.000.000 de tokens, lo que le permite procesar y analizar documentos extremadamente grandes y discursos extensos de manera eficaz.
P: ¿Cuáles son las principales mejoras de Grok 4.1 en cuanto a la precisión de los datos?
A: Grok 4.1 presenta tres veces menos alucinaciones en las consultas de búsqueda de información en comparación con las versiones anteriores y se beneficia de una mejor contextualización web mediante activadores de búsqueda, lo que da como resultado resultados altamente fiables.
P: ¿Se puede utilizar Grok 4.1 para la escritura creativa y las interacciones emocionales?
A: Por supuesto. Grok 4.1 destaca en inteligencia emocional y escritura creativa, ofreciendo respuestas empáticas y basadas en la personalidad, así como la capacidad de crear narrativas convincentes, optimizadas mediante el aprendizaje por refuerzo.
P: ¿Es Grok 4.1 adecuado para usuarios globales y temas delicados?
R: Sí, Grok 4.1 es multilingüe, se ha evaluado en idiomas como inglés, español y árabe, e incluye sólidas capas de seguridad con políticas de rechazo para intenciones ilegales y medidas de mitigación contra el engaño, lo que garantiza una asistencia global segura y responsable.
Campo de juegos de IA

