 OpenAI - ChatGPT, Sora
OpenAI - ChatGPT, Sora Google - Gemini, Nano Banana
Google - Gemini, Nano Banana Antrópico - Claude
Antrópico - Claude xAI - Grok
xAI - Grok Búsqueda profunda
Búsqueda profunda Alibaba - Reina
Alibaba - Reina ByteDance - Lo mejor de ByteDance
ByteDance - Lo mejor de ByteDance Todos los modelos
Todos los modelos Planes empresariales
Planes empresariales Desarrollo de aplicaciones de IA
Desarrollo de aplicaciones de IA API de traducción de IA
API de traducción de IA Servicio de SEO/GEO con IA
Servicio de SEO/GEO con IA Servicio de relaciones públicas geooptimizado
Servicio de relaciones públicas geooptimizado Servicio de extracción de datos web
Servicio de extracción de datos web OpenClaw
OpenClaw Las mejores herramientas de IA
Las mejores herramientas de IA Los mejores robots de IA
Los mejores robots de IA
 Acceso
Acceso



const axios = require('axios').default;
const api = axios.create({
baseURL: 'https://api.ai.cc/v1',
headers: { Authorization: 'Bearer ' },
});
const main = async () => {
const response = await api.post('/tts', {
model: 'inworld/tts-1-max',
text: 'OpenAI TTS are fast and powerful language models. Use it to convert text to natural sounding spoken text.',
voice: 'coral',
});
console.log('Audio URL:', response.data.audio.url);
console.log('Characters:', response.data.usage.characters);
};
main();
import requests
def main():
url = "https://api.ai.cc/v1/tts"
headers = {
"Authorization": "Bearer ",
}
payload = {
"model": "inworld/tts-1-max",
"text": "OpenAI TTS are fast and powerful language models. Use it to convert text to natural sounding spoken text.",
"voice": "coral"
}
response = requests.post(url, headers=headers, json=payload)
data = response.json()
print("Audio URL:", data["audio"]["url"])
print("Characters:", data["usage"]["characters"])
main()


Detalles del producto
Inworld TTS-1-Max: Revolucionando la conversión de texto a voz
Descubre el API Inworld TTS-1-MaxSe trata de un modelo de conversión de texto a voz (TTS) autorregresivo de última generación basado en Transformer. Diseñado para ofrecer una calidad de voz y una expresividad inigualables, se posiciona como la opción principal para aplicaciones profesionales y comerciales que requieren una síntesis de voz matizada y de alta resolución.
Con una impresionante 8.8 mil millones de parámetrosTTS-1-Max amplía los límites de la generación de lenguaje natural, produciendo voces prácticamente indistinguibles del habla humana.
Especificaciones técnicas y rendimiento
- ⚙️ Arquitectura: Modelo autorregresivo avanzado basado en Transformer
- 🔢 Parámetros: Una enorme 8.8 mil millones (el más grande de la familia Inworld TTS-1)
- 🔊 Salida de audio: Cristalina, de alta resolución 48 kHz discurso
- 🌐 Idiomas compatibles: Apoyo integral para 11 idiomas principales
- ⚡ Velocidad de inferencia: Alcanza aproximadamente 8.000 tokens/segundo por GPU en una configuración de 32 H100, lo que garantiza la eficiencia.
Liderando las clasificaciones de calidad
El modelo TTS-1-Max se clasifica constantemente como un mejor desempeño en clasificaciones de calidad independientes, demostrando su rendimiento superior y su naturalidad en diversas evaluaciones.
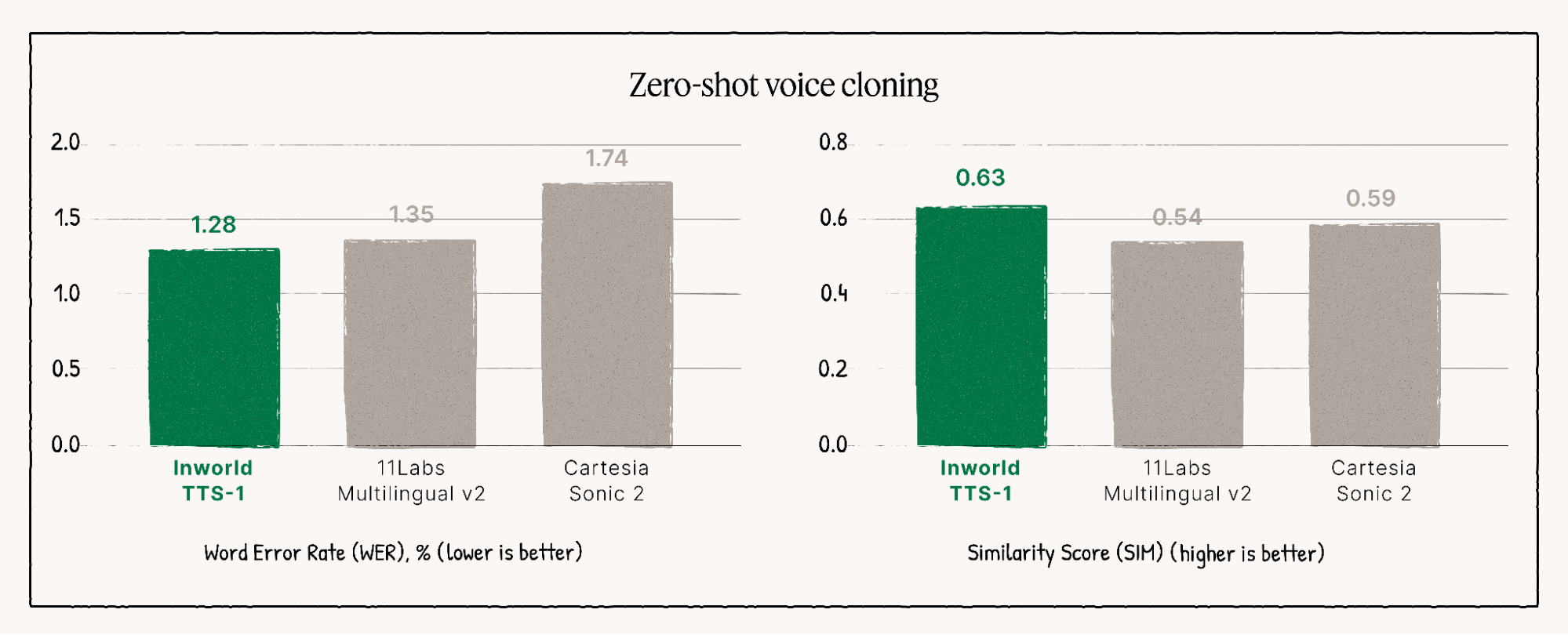
Características clave para una síntesis de voz sin igual
- ✨ Naturalidad y expresividad superiores: Aprovecha la parametrización a gran escala para obtener resultados de voz increíblemente naturales y con gran riqueza emocional.
- 🗣️ Síntesis multilingüe de alta fidelidad: Generar voz con una claridad y precisión excepcionales en todo momento. 11 idiomas diversosIdeal para aplicaciones globales.
- 🎭 Modulación emocional avanzada: Perfecciona los estilos de habla con sólidas capacidades de modulación emocional, añadiendo matices y profundidad a cada enunciado.
- 👂 Sonidos y vocalizaciones no verbales realistas: Mejora el realismo del habla con una compatibilidad perfecta con diversas señales no verbales, lo que hace que las voces de la IA suenen más naturales.
- 👤 Clonación de voz pura en contexto: Logra la clonación de voz sin necesidad de datos de locutores pregrabados, basándose exclusivamente en un sofisticado aprendizaje contextual.
Precios de API transparentes y competitivos
💰 Experimente la síntesis de voz de alta calidad con precios sencillos y transparentes:
- Costo: Solo $10.5 por cada millón de caracteres generados.
- Coste estimado por minuto: Aproximadamente $0.0105 por minuto de habla generada de alta calidad.
Integración sencilla: Ejemplo de código
Integrar Inworld TTS-1-Max en tus aplicaciones es muy sencillo. A continuación, se muestra un fragmento de la API para una integración rápida:
https://docs.ai.cc/api-references/speech-models/text-to-speech/inworld/tts-1-max " snippet data-name="voice.tts-openai" data-model="inworld/tts-1-max"> Para obtener detalles completos sobre la integración, parámetros avanzados y más ejemplos de código, consulte la Documentación oficial de la API de Inworld TTS-1-Max.
Inworld TTS-1-Max: Ventaja competitiva
Comprenda cómo Inworld TTS-1-Max se distingue de otros modelos líderes de conversión de texto a voz en el mercado, ofreciendo ventajas especializadas para diversos casos de uso.
🆚 vs. Inworld TTS-1
TTS-1-Max ofrece superior expresividad y naturalidad gracias a su escala de parámetros significativamente mayor de 8.8 mil millones (en comparación con los 1.6 mil millones de TTS-1), lo que lo hace ideal para contenido premium como audiolibros. En contraste, TTS-1 prioriza velocidad en tiempo real (~153 caracteres/segundo frente a los ~69 caracteres/segundo de TTS-1-Max), lo que lo hace más adecuado para aplicaciones altamente interactivas.
🆚 vs. ElevenLabs Multilingüe V2
En las pruebas de calidad, TTS-1-Max logra un Tasa de victorias en enfrentamientos directos del 59,1%., que ofrece una granularidad emocional más fina y un soporte robusto para sonidos no verbales a través de marcadores. Mientras que ElevenLabs proporciona una clonación multilingüe sólida, TTS-1-Max lidera en resolución de audio sin procesar y la pureza de su enfoque de aprendizaje contextualizado.
🆚 vs. MiniMax-Speech
TTS-1-Max prioriza calidad de voz máxima y fidelidad en sus 11 idiomas compatibles, demostrando liderazgo en naturalidad de referencia y control de la prosodia emocional. MiniMax-Speech, por el contrario, hace hincapié en capacidades de clonación de cero disparos más amplias en 32 idiomas y replicación de voz rápida de un solo disparo.
Preguntas frecuentes (FAQ)
❓ ¿Qué es Inworld TTS-1-Max?
Inworld TTS-1-Max es una API de conversión de texto a voz autorregresiva de vanguardia basada en Transformer, con 8.800 millones de parámetros. Está diseñada para aplicaciones profesionales y comerciales que exigen una calidad de voz y una expresividad superiores.
❓ ¿Cuáles son sus principales características técnicas?
Ofrece una arquitectura Transformer autorregresiva, 8.800 millones de parámetros, audio de alta resolución de 48 kHz, compatibilidad con 11 idiomas principales y una velocidad de inferencia de aproximadamente 8.000 tokens/segundo por GPU.
❓ ¿Cómo logra TTS-1-Max un alto nivel de expresividad?
Su excepcional expresividad y naturalidad provienen de su parametrización a gran escala de 8.800 millones de registros, junto con capacidades de modulación emocional y soporte para sonidos no verbales, lo que crea un habla con gran riqueza de matices.
❓ ¿Cuál es la estructura de precios de la API TTS-1-Max?
La API tiene un precio de 10,5 dólares por cada millón de caracteres, lo que se traduce en un coste estimado de unos 0,0105 dólares por minuto de voz generada.
❓ ¿Cuáles son los casos de uso ideales para Inworld TTS-1-Max?
Es ideal para locuciones profesionales, doblaje, IA conversacional avanzada, producción de contenido multimedia multilingüe, aplicaciones de voz interactivas, audiolibros, videojuegos y entornos virtuales inmersivos donde la calidad y la expresividad de la voz son primordiales.
Campo de juegos de IA

