 OpenAI - ChatGPT, Sora
OpenAI - ChatGPT, Sora Google - Gemini, Nano Banana
Google - Gemini, Nano Banana Antrópico - Claude
Antrópico - Claude xAI - Grok
xAI - Grok Búsqueda profunda
Búsqueda profunda Alibaba - Reina
Alibaba - Reina ByteDance - Lo mejor de ByteDance
ByteDance - Lo mejor de ByteDance Todos los modelos
Todos los modelos Planes empresariales
Planes empresariales Desarrollo de aplicaciones de IA
Desarrollo de aplicaciones de IA API de traducción de IA
API de traducción de IA Servicio de SEO/GEO con IA
Servicio de SEO/GEO con IA Servicio de relaciones públicas geooptimizado
Servicio de relaciones públicas geooptimizado Servicio de extracción de datos web
Servicio de extracción de datos web OpenClaw
OpenClaw Las mejores herramientas de IA
Las mejores herramientas de IA Los mejores robots de IA
Los mejores robots de IA
 Acceso
Acceso



const { OpenAI } = require('openai');
const api = new OpenAI({
baseURL: 'https://api.ai.cc/v1',
apiKey: '',
});
const main = async () => {
const result = await api.chat.completions.create({
model: 'alibaba/qwen3-max-instruct',
messages: [
{
role: 'system',
content: 'You are an AI assistant who knows everything.',
},
{
role: 'user',
content: 'Tell me, why is the sky blue?'
}
],
});
const message = result.choices[0].message.content;
console.log(`Assistant: ${message}`);
};
main();
import os
from openai import OpenAI
client = OpenAI(
base_url="https://api.ai.cc/v1",
api_key="",
)
response = client.chat.completions.create(
model="alibaba/qwen3-max-instruct",
messages=[
{
"role": "system",
"content": "You are an AI assistant who knows everything.",
},
{
"role": "user",
"content": "Tell me, why is the sky blue?"
},
],
)
message = response.choices[0].message.content
print(f"Assistant: {message}")


Detalles del producto
Descubrir Instrucciones de Qwen3-Max, el innovador modelo de lenguaje a gran escala (LLM) de Alibaba, presentado oficialmente a principios de 2025. Este modelo insignia de IA cuenta con más de 1 billón de parámetros, lo que supone un salto significativo en la inteligencia artificial a gran escala. Entrenado con conjuntos de datos masivos y una arquitectura avanzada, Qwen3-Max Instruct demuestra capacidades excepcionales, en particular en tareas técnicas, de codificación y matemáticasEsta variante ajustada a las instrucciones está específicamente optimizada para Instrucciones rápidas y directaseliminando la necesidad de razonamientos paso a paso y proporcionando respuestas rápidas y precisas.
✨ Especificaciones técnicas: Potencia inigualable
- 🚀 Escala de parámetros: Más de 1 billón de parámetros (escala de nivel de billón)
- 💾 Datos de entrenamiento: 36 billones de tokens de datos de preentrenamiento
- 🧠 Arquitectura del modelo: Transformador Mixture of Experts (MoE) con balanceo de carga global por lotes para mayor eficiencia.
- 📚 Longitud del contexto: Hasta 262.144 tokens (admitiendo más de 258.000 tokens de entrada + 65.000 tokens de salida)
- ⚡ Eficiencia del entrenamiento: Mejora del 30 % en la MFU con respecto a los modelos Qwen 2.5 Max de la generación anterior.
- 🗣️ Idiomas compatibles: Más de 100 idiomas, con mejoras específicas para contextos mixtos chino-inglés.
- 💡 Modo de inferencia: Modo sin pensamiento, que prioriza las respuestas rápidas y directas a las instrucciones (versión con pensamiento en desarrollo).
- 🔄 Almacenamiento en caché de contexto: Permite la reutilización de teclas de contexto para mejorar significativamente el rendimiento en conversaciones de varios turnos.
📊 Indicadores de rendimiento y aspectos destacados: Estableciendo nuevos estándares
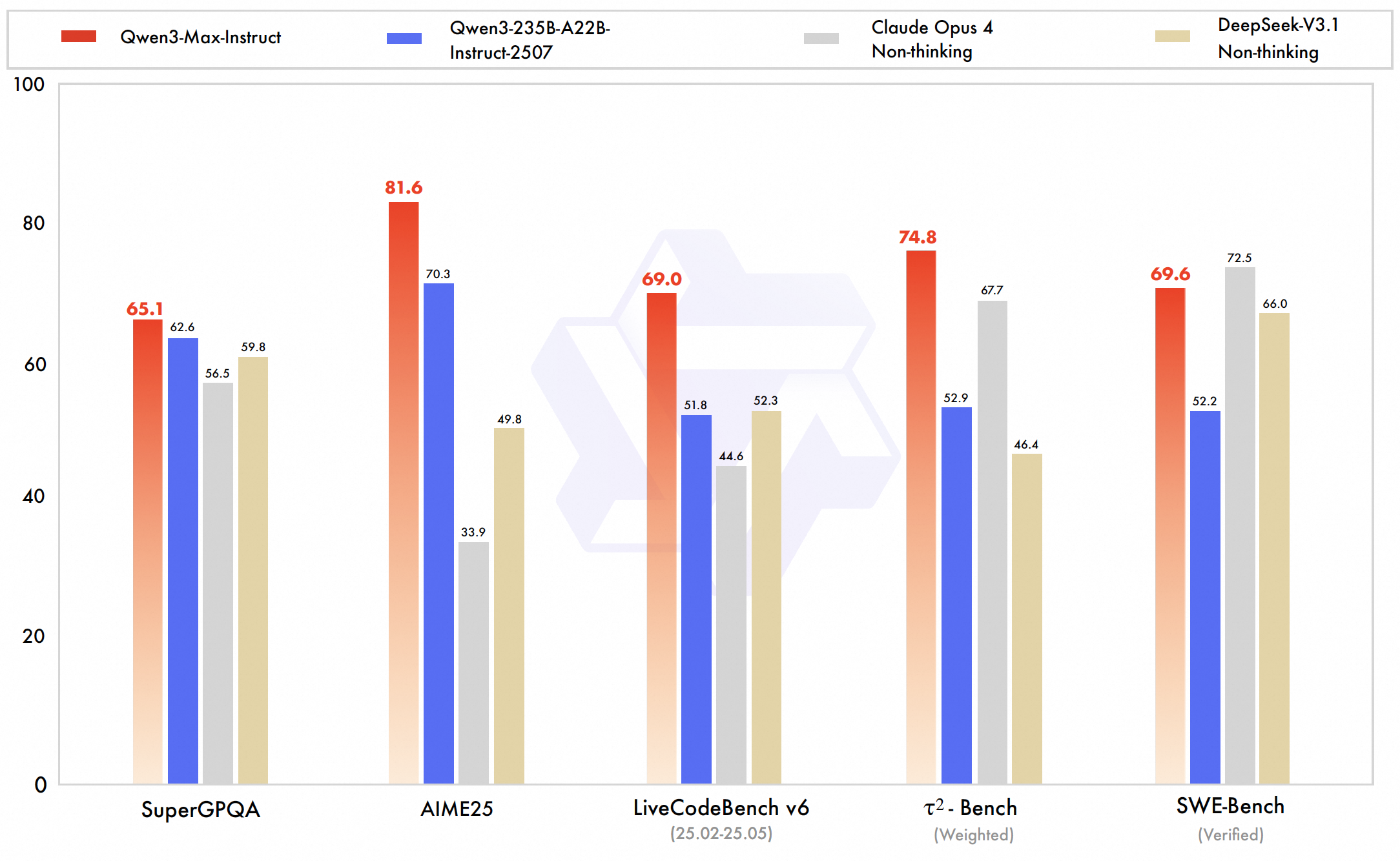
Qwen3-Max logra un rendimiento de clase mundial, destacando particularmente en código, razonamiento matemático y dominios técnicosLas pruebas internas de Alibaba y los resultados de su clasificación confirman su superioridad o equivalencia con modelos de IA de primer nivel como GPT-5-Chat, Claude Opus 4 y DeepSeek V3.1 en múltiples pruebas comparativas.
- 💻 SWE-Bench verificado: 69.6 (Demuestra una gran capacidad para resolver problemas de programación en el mundo real)
- 🔬 Banco de pruebas Tau2: 74.8 (supera a Claude Opus 4 y DeepSeek V3.1)
- ❓ SuperGPQA: 81.4 (Rendimiento en la respuesta a preguntas clave)
- ✍️ LiveCodeBench: Excelentes resultados en el desafío de código real.
- 🧮 AIME25 (Razonamiento Matemático): 80.6 (superando a muchos competidores)
- 🏆 Arena-Difícil v2: 86.1 (Excelente desempeño en tareas difíciles)
- 🏅 Clasificación de la Arena LM: #6 en la clasificación general, superando a muchos modelos de última generación, excepto a los mejores modelos conversacionales como GPT-40.
💰 Precios de API: IA a gran escala rentable
- Precio de entrada: $1.26 por millón de tokens
- Precio de salida: $6.30 por millón de tokens
💡 Casos de uso clave: Impulsando la innovación empresarial
- 🏢 Aplicaciones empresariales: Ideal para dominios técnicos que requieren un procesamiento de contexto extenso, como por ejemplo: generación de código, modelado matemático y asistencia en investigación.
- 🌍 Soporte multilingüe: Aplicaciones bilingües e internacionales robustas con Sólida capacidad para manejar la mezcla de idiomas chino e inglés..
- 📜 Ventanas de contexto enormes: Permite la comprensión de documentos extremadamente largos y diálogos de varias rondas con persistencia.
- 🛠️ Listo para usar la herramienta: Optimizado para la generación con recuperación mejorada y la integración con herramientas externas.
- 🚀 Respuestas rápidas: Prioriza la ejecución rápida de instrucciones sin la sobrecarga que supone la cadena de pensamiento.
- 🔗 Integración del ecosistema: Forma parte de la familia Qwen3 de Alibaba, que incluye variantes de visión y razonamiento (Qwen-VL-Max y Qwen3-Max-Thinking).
💻 Ejemplo de código: Primeros pasos
importar openai
cliente = openai. OpenAI (
base_url= "https://api.ai.cc/v1" ,
api_key= "TU_CLAVE_API" ,
)
chat_complete = client.chat.completes.create (
modelo= "alibaba/qwen3-max-instruct" ,
mensajes=[
{
"rol" : "sistema" ,
"contenido" : "Eres un asistente de IA muy útil."
},
{
"rol" : "usuario" ,
"Contenido" : "Explicar el concepto de entrelazamiento cuántico en términos sencillos."
},
],
tokens_máximos=500,
temperatura=0,7,
)
print(chat_completion.choices[0].message.content) 🆚 Comparación con otros modelos líderes
vs GPT-5-Chat: Qwen3-Max Instruct toma la delantera en puntos de referencia de codificación y capacidades de los agentes, demostrando un sólido desempeño en tareas complejas de ingeniería de software. Sin embargo, GPT-5-Chat se beneficia de un ecosistema más maduro con funciones multimodales más amplias e integraciones comerciales más extensas. Cabe destacar que Qwen ofrece una ventana de contexto mucho mayor (~262k tokens) en comparación con los ~100k tokens de GPT-5.
vs Claude Opus 4: Qwen3-Max supera a Claude Opus 4 en las pruebas de rendimiento de agentes y codificación, además de admitir un tamaño de contexto significativamente mayor. Claude destaca en flujos de trabajo de agentes de larga duración y comportamientos centrados en la seguridad, lo que lo convierte en un fuerte competidor en áreas específicas. Ambos modelos presentan un rendimiento general muy similar, aunque Claude mantiene una ligera ventaja en tareas de edición de código conservadoras.
vs DeepSeek V3.1: Qwen3-Max supera a DeepSeek V3.1 en pruebas de rendimiento clave para agentes, como Tau2-Bench, y en diversos desafíos de codificación, demostrando una mayor capacidad de razonamiento y uso de herramientas. Si bien DeepSeek admite entradas multimodales, se queda atrás de Qwen en el procesamiento de contexto extendido. Las innovaciones de Qwen en entrenamiento avanzado y escalabilidad confirman su liderazgo en tareas complejas y de gran escala.
🔌 Integración de API: Acceso sin interrupciones
Qwen3-Max Instruct es fácilmente accesible a través de la API de IA/ML. La documentación completa está disponible. disponible aquí Para desarrolladores que buscan una integración perfecta.
❓ Preguntas frecuentes (FAQ)
P: ¿Qué avances arquitectónicos distinguen las capacidades de seguimiento de instrucciones de Qwen3-Max Instruct?
A: Qwen3-Max Instruct emplea un revolucionario marco de ajuste de instrucciones que combina el ajuste fino supervisado con el aprendizaje por refuerzo a partir de la retroalimentación humana a una escala sin precedentes. Su arquitectura presenta una comprensión de instrucciones multigranular, analizando directivas complejas con restricciones matizadas y lógica condicional. Mecanismos de atención avanzados ponderan dinámicamente los componentes de la instrucción, mientras que vías de razonamiento especializadas se activan según el tipo de instrucción, lo que garantiza una adhesión precisa a la intención del usuario.
P: ¿Cómo logra Qwen3-Max Instruct su rendimiento excepcional en instrucciones complejas y multimodales?
A: El modelo integra el procesamiento de instrucciones multimodales, comprendiendo y ejecutando directivas en texto, código, notación matemática y diagramas conceptuales mediante el aprendizaje de representaciones unificadas. Emplea la descomposición jerárquica de instrucciones, dividiendo las solicitudes complejas en subtareas ejecutables con seguimiento de dependencias. Los algoritmos avanzados de satisfacción de restricciones garantizan el cumplimiento de todos los requisitos, mientras que la adaptación dinámica del estilo se ajusta a los tonos y formatos solicitados.
P: ¿Qué capacidades especializadas de seguimiento de instrucciones hacen que este modelo sea excepcional para aplicaciones empresariales?
A: Qwen3-Max Instruct ofrece capacidades de instrucción de nivel empresarial, incluyendo una adhesión precisa a los estándares de formato empresarial, la aplicación consistente de las directrices de identidad de marca, la ejecución precisa de las especificaciones técnicas y el cumplimiento fiable de los requisitos normativos. Destaca por procesar instrucciones específicas del sector con interpretación adaptada al dominio, manteniendo el contexto a lo largo de secuencias extensas y proporcionando trazas de ejecución transparentes para su verificación.
P: ¿Cómo maneja el modelo las instrucciones ambiguas o contradictorias sin perder su utilidad?
A: La arquitectura incorpora sofisticados mecanismos de resolución de instrucciones que identifican ambigüedades, posibles conflictos y elementos insuficientemente especificados mediante razonamiento probabilístico y análisis de contexto. Ante instrucciones ambiguas, el modelo emplea protocolos de aclaración, sugiriendo interpretaciones y manteniendo la flexibilidad. Para directivas conflictivas, implementa una resolución basada en prioridades utilizando jerarquías aprendidas de la intención del usuario, lo que garantiza tanto la fidelidad de las instrucciones como su utilidad práctica.
P: ¿Qué características de seguridad y alineación garantizan una ejecución responsable de las instrucciones?
A: Qwen3-Max Instruct incorpora una verificación de seguridad multicapa, evaluando las instrucciones según directrices éticas y posibles riesgos antes de su ejecución. El modelo incluye la depuración de instrucciones para neutralizar reinterpretaciones perjudiciales, una ejecución que preserva los valores y mantiene las restricciones éticas, y un razonamiento transparente sobre las decisiones relacionadas con la seguridad. Estas salvaguardas garantizan que el modelo siga siendo útil, inocuo y honesto al ejecutar instrucciones complejas y abiertas.
Campo de juegos de IA

