 OpenAI - ChatGPT, Sora
OpenAI - ChatGPT, Sora Google - Gemini, Nano Banana
Google - Gemini, Nano Banana Antrópico - Claude
Antrópico - Claude xAI - Grok
xAI - Grok Búsqueda profunda
Búsqueda profunda Alibaba - Reina
Alibaba - Reina ByteDance - Lo mejor de ByteDance
ByteDance - Lo mejor de ByteDance Todos los modelos
Todos los modelos Planes empresariales
Planes empresariales Desarrollo de aplicaciones de IA
Desarrollo de aplicaciones de IA API de traducción de IA
API de traducción de IA Servicio de SEO/GEO con IA
Servicio de SEO/GEO con IA Servicio de relaciones públicas geooptimizado
Servicio de relaciones públicas geooptimizado Servicio de extracción de datos web
Servicio de extracción de datos web OpenClaw
OpenClaw Las mejores herramientas de IA
Las mejores herramientas de IA Los mejores robots de IA
Los mejores robots de IA
 Acceso
Acceso



const { OpenAI } = require('openai');
const api = new OpenAI({
baseURL: 'https://api.ai.cc/v1',
apiKey: '',
});
const main = async () => {
const result = await api.chat.completions.create({
model: 'alibaba/qwen3-next-80b-a3b-instruct',
messages: [
{
role: 'system',
content: 'You are an AI assistant who knows everything.',
},
{
role: 'user',
content: 'Tell me, why is the sky blue?'
}
],
});
const message = result.choices[0].message.content;
console.log(`Assistant: ${message}`);
};
main();
import os
from openai import OpenAI
client = OpenAI(
base_url="https://api.ai.cc/v1",
api_key="",
)
response = client.chat.completions.create(
model="alibaba/qwen3-next-80b-a3b-instruct",
messages=[
{
"role": "system",
"content": "You are an AI assistant who knows everything.",
},
{
"role": "user",
"content": "Tell me, why is the sky blue?"
},
],
)
message = response.choices[0].message.content
print(f"Assistant: {message}")

-p-130x130q80-p-130x130q80.png)
Detalles del producto
Qwen3-Siguiente-80B-A3B Instrucciones Es un modelo de lenguaje grande, altamente avanzado y optimizado para instrucciones, diseñado para ofrecer una velocidad, estabilidad y manejo de contextos ultralargos excepcionales con un alto rendimiento. Logra mejoras significativas en velocidad y rentabilidad al activar solo una pequeña parte de sus 80 mil millones de parámetros, sin comprometer el rendimiento en áreas críticas como el razonamiento complejo y la generación de código.
⚙️ Especificaciones técnicas
Qwen3-Next-80B-A3B Instruct optimiza sus operaciones mediante Activando solo unos 3 mil millones de parámetros de 80 mil millones durante la inferencia.Este mecanismo de activación dispersa proporciona ventajas sustanciales:
- Rapidez y rentabilidad: Funciona aproximadamente 10 veces más rápido y de forma más rentable en comparación con el modelo anterior Qwen3-32B.
- Rendimiento: Ofrece un rendimiento más de 10 veces superior al procesar contextos largos de 32.000 tokens o más.
- Despliegue flexible: Ofrece opciones de implementación versátiles, que incluyen alojamiento sin servidor, dedicado bajo demanda y alojamiento reservado mensualmente.
- Compatibilidad de implementación: Compatible con SGLang y vLLM para un uso eficiente y escalable, e incorpora capacidades avanzadas de predicción de múltiples tokens.
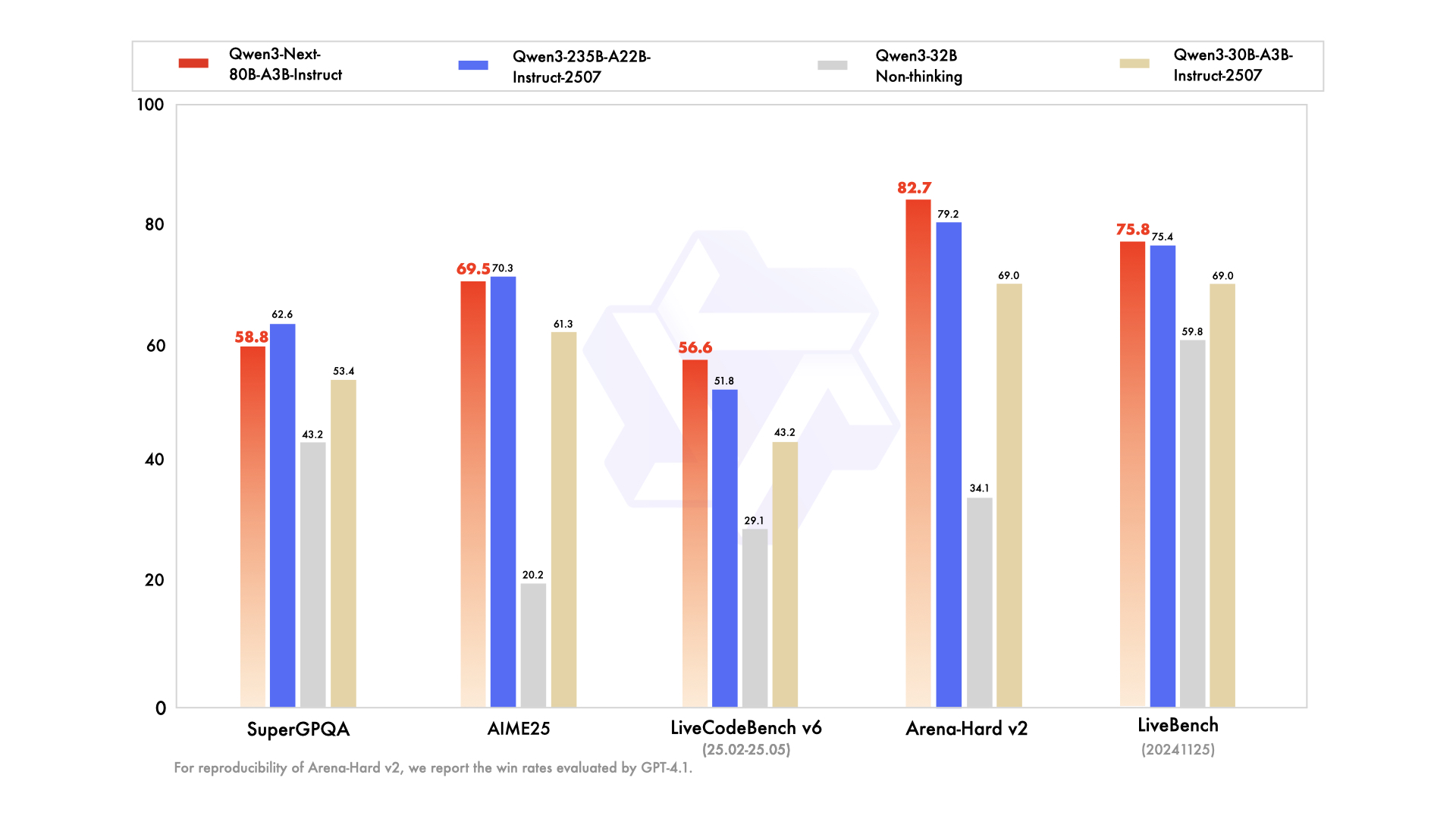
📊 Indicadores de rendimiento
- ✅ Rendimiento de primer nivel: Su rendimiento iguala o se aproxima mucho al del modelo insignia Qwen3-235B en diversas tareas de razonamiento, autocompletado de código y seguimiento de instrucciones.
- ✅ Manejo inquebrantable de contextos extensos: Proporciona respuestas estables y deterministas de forma consistente, destacando especialmente en tareas que requieren una amplia comprensión del contexto.
- ✅ Eficiente en el uso de recursos: Supera en eficiencia a los modelos anteriores de tamaño medio optimizados para instrucciones, logrando un alto rendimiento con menos recursos computacionales.
- ✅ Integración versátil: Muy adecuado para la integración de herramientas, la generación aumentada por recuperación (RAG) y flujos de trabajo de agentes sofisticados que requieren resultados coherentes en la cadena de pensamiento.
💰 Precios de API
Aporte: $0.1575
Producción: $1.6
✨ Capacidades clave
- 🚀 Inferencia ultraeficiente: Emplea una arquitectura de mezcla de expertos (MoE) dispersa, que activa dinámicamente solo 3.000 millones de parámetros de un total de 80.000 millones para lograr una inferencia significativamente más rápida y rentable.
- 🧠 Rendimiento excepcional en las tareas: Destaca en una amplia gama de tareas complejas, que incluyen razonamiento avanzado, generación de código robusta, respuesta precisa a preguntas de conocimiento y aplicaciones multilingües versátiles.
- ⚡️ Respuestas estables y rápidas: Optimizado para el modo de instrucción, lo que garantiza respuestas rápidas y consistentes sin pasos intermedios de "pensamiento".
- 📖 Manejo de contexto ultralargo: Cuenta con una longitud de contexto nativa de 262.000 tokens, ampliable hasta un impresionante millón de tokens mediante tecnología de escalado avanzada.
- 📈 Alto rendimiento: Logra una mejora de 10 veces en el rendimiento para el procesamiento de contextos extensos y largos en comparación con los modelos anteriores.
- 💬 Diálogo y respuestas coherentes: Ideal para diálogos de varios turnos y tareas que exigen respuestas finales deterministas y consistentes.
- 🛠️ Flujos de trabajo agenciales avanzados: Sólidas capacidades para la llamada a herramientas, la ejecución de tareas en varios pasos y flujos de trabajo automatizados sofisticados con herramientas perfectamente integradas.
💡 Casos de uso
- Generación de código: Acelera el desarrollo de software mediante sugerencias de código inteligentes y la generación completa de bloques de código.
- Creación y edición de contenido: Generar contenido diverso, desde artículos hasta textos de marketing, y realizar ediciones minuciosas siguiendo instrucciones detalladas.
- Análisis de datos: Facilita la interpretación de datos complejos, el análisis estadístico y la generación de informes completos.
- Automatización del servicio al cliente: Mejore la eficiencia de la atención al cliente con un manejo preciso de las instrucciones y respuestas automatizadas.
- Documentación técnica: Optimice la creación de documentos técnicos, manuales y resultados con formatos específicos.
- Automatización de procesos: Ejecuta tareas de varios pasos e integra la llamada a herramientas para automatizar y optimizar diversos flujos de trabajo.
- Conversaciones largas y manejo de documentos: Gestiona de forma eficiente diálogos extensos, resume documentos grandes y extrae información clave de textos extensos.
💻 Ejemplo de código
import openai client = openai.OpenAI( base_url="https://api.perplexity.ai", # Ejemplo de URL base, reemplazar con el endpoint real api_key="YOUR_API_KEY", # Reemplazar con tu clave API real ) messages = [ { "role": "system", "content": "Eres Qwen3-Next-80B-A3B Instruct, un útil asistente de IA." }, { "role": "user", "content": "Explica el concepto de entrelazamiento cuántico en términos sencillos para un estudiante de secundaria." }, ] response = client.chat.completions.create( model="alibaba/qwen3-next-80b-a3b-instruct", messages=messages, max_tokens=500, temperature=0.7, top_p=0.9, frequency_penalty=0, presence_penalty=0, ) print(response.choices[0].message.content) Nota: Los campos `base_url` y `api_key` del ejemplo anterior son marcadores de posición. Para obtener información específica sobre la integración, consulte la documentación oficial de la API.
🆚 Comparación con otros modelos
El modelo 80B A3B ofrece un rendimiento que iguala o se aproxima mucho al del modelo insignia 235B en tareas de razonamiento y codificación, a la vez que es significativamente más eficiente al activar menos parámetros para una inferencia más rápida y rentable.
Qwen3-Next ofrece capacidades comparables de seguimiento de instrucciones y de contexto extenso, distinguiéndose por una ventaja en el rendimiento y un tamaño de ventana de tokens mayor, lo que lo hace particularmente adecuado para tareas extensas de comprensión de documentos.
Qwen3-Next muestra un rendimiento superior en diálogos de varios turnos y flujos de trabajo con agentes, proporcionando resultados más deterministas en contextos muy largos en comparación con las fortalezas conversacionales de Claude.
Qwen3-Next muestra una mejor escalabilidad en el manejo de contextos ultralargos y una eficiencia superior en la predicción de múltiples tokens, lo que le otorga una clara ventaja en el procesamiento de tareas de razonamiento complejas y de múltiples pasos.
❓ Preguntas frecuentes
P1: ¿Qué hace que Qwen3-Next-80B-A3B Instruct sea excepcionalmente eficiente?
El modelo utiliza una arquitectura de mezcla de expertos (MoE) dispersa, activando solo aproximadamente 3 mil millones de sus 80 mil millones de parámetros durante la inferencia. Este enfoque innovador permite un procesamiento significativamente más rápido y menores costos operativos, logrando una eficiencia hasta 10 veces mayor que la de los modelos anteriores.
P2: ¿Cómo se comporta con contextos ultralargos?
Qwen3-Next-80B-A3B Instruct admite una longitud de contexto nativa de 262 000 tokens, y gracias a su avanzada tecnología de escalado, puede extenderse hasta un impresionante millón de tokens. Esta capacidad lo hace ideal para tareas que requieren una comprensión profunda de documentos extensos y conversaciones largas.
P3: ¿Cómo se compara su rendimiento con el de otros modelos de lenguaje líderes?
Si bien es altamente eficiente, Qwen3-Next-80B-A3B Instruct iguala o se acerca mucho al rendimiento de modelos emblemáticos como Qwen3-235B en tareas complejas de razonamiento y generación de código. También ofrece capacidades comparables o superiores en rendimiento, manejo de contextos extensos y resultados deterministas en comparación con modelos como GPT-4.1, Claude 4.1 Opus y Gemini 2.5 Flash.
P4: ¿Cuáles son los principales casos de uso de Qwen3-Next-80B-A3B Instruct?
Este modelo es excepcionalmente adecuado para aplicaciones que requieren un alto rendimiento, un seguimiento preciso de instrucciones y un procesamiento de contexto exhaustivo. Entre sus principales casos de uso se incluyen la generación avanzada de código, la creación de contenido sofisticado, el análisis detallado de datos, la automatización del servicio al cliente, la documentación técnica y flujos de trabajo complejos basados en agentes.
P5: ¿Es compatible Qwen3-Next-80B-A3B Instruct con las infraestructuras de implementación existentes?
Sí, el modelo está diseñado para una integración perfecta con herramientas de implementación existentes como SGLang y vLLM, y admite capacidades avanzadas de predicción de múltiples tokens. Además, ofrece opciones de implementación flexibles, que incluyen alojamiento sin servidor, dedicado bajo demanda y con reserva mensual, para adaptarse a diversas necesidades operativas.
Campo de juegos de IA

