 OpenAI - ChatGPT, Sora
OpenAI - ChatGPT, Sora Google - Gemini, Nano Banana
Google - Gemini, Nano Banana Antrópico - Claude
Antrópico - Claude xAI - Grok
xAI - Grok Búsqueda profunda
Búsqueda profunda Alibaba - Reina
Alibaba - Reina ByteDance - Lo mejor de ByteDance
ByteDance - Lo mejor de ByteDance Todos los modelos
Todos los modelos Planes empresariales
Planes empresariales Desarrollo de aplicaciones de IA
Desarrollo de aplicaciones de IA API de traducción de IA
API de traducción de IA Servicio de SEO/GEO con IA
Servicio de SEO/GEO con IA Servicio de relaciones públicas geooptimizado
Servicio de relaciones públicas geooptimizado Servicio de extracción de datos web
Servicio de extracción de datos web OpenClaw
OpenClaw Las mejores herramientas de IA
Las mejores herramientas de IA Los mejores robots de IA
Los mejores robots de IA
 Acceso
Acceso



const { OpenAI } = require('openai');
const api = new OpenAI({
baseURL: 'https://api.ai.cc/v1',
apiKey: '',
});
const main = async () => {
const result = await api.chat.completions.create({
model: 'alibaba/qwen3-vl-32b-instruct',
messages: [
{
role: 'system',
content: 'You are an AI assistant who knows everything.',
},
{
role: 'user',
content: 'Tell me, why is the sky blue?'
}
],
});
const message = result.choices[0].message.content;
console.log(`Assistant: ${message}`);
};
main();
import os
from openai import OpenAI
client = OpenAI(
base_url="https://api.ai.cc/v1",
api_key="",
)
response = client.chat.completions.create(
model="alibaba/qwen3-vl-32b-instruct",
messages=[
{
"role": "system",
"content": "You are an AI assistant who knows everything.",
},
{
"role": "user",
"content": "Tell me, why is the sky blue?"
},
],
)
message = response.choices[0].message.content
print(f"Assistant: {message}")


Detalles del producto
✨ Descubre Qwen3 VL 32B Instruct: Tu IA avanzada de visión y lenguaje
El Instrucciones Qwen3 VL 32B Es un modelo de lenguaje visual de vanguardia (VL, por sus siglas en inglés) diseñado específicamente para seguir instrucciones con precisión en una amplia gama de tareas visuales. Destaca por su capacidad para interpretar entradas visuales complejas y generar salidas textuales altamente coherentes y contextualizadas. Este modelo está meticulosamente optimizado para sobresalir en la descripción de imágenes, el diálogo visual atractivo y la generación de contenido versátil, lo que lo convierte en una herramienta poderosa para aplicaciones de IA multimodal.
Como se detalla en su Descripción general oficial del Qwen3 VL 32BLa Qwen3 VL 32B Instruct es una versión "sin capacidad de razonamiento", lo que significa que está optimizada para la ejecución directa y eficiente de tareas visuales en lugar de un razonamiento general más amplio, lo que garantiza un rendimiento superior en su dominio especializado.
⚙️ Especificaciones técnicas de un vistazo
- Tipo de modelo: Modelo a gran escala (VL) de visión y lenguaje
- Recuento de parámetros: 32 mil millones de parámetros
- Arquitectura: Arquitectura multimodal basada en transformadores, que integra un codificador visual robusto con un decodificador de texto sofisticado.
- Modalidades de entrada: Permite la integración perfecta de imágenes e instrucciones/mensajes de texto.
- Modalidades de salida: Especializados en la generación de textos de alta calidad (descripciones, diálogos, contenido creativo).
- Datos de entrenamiento: Entrenado con un vasto conjunto de datos multimodales a gran escala que comprende imágenes meticulosamente anotadas junto con textos descriptivos y conversacionales detallados.
- Capacidades de inferencia: Ofrece una sólida instrucción inicial, con cero o pocos disparos, eliminando la necesidad de un extenso reentrenamiento.
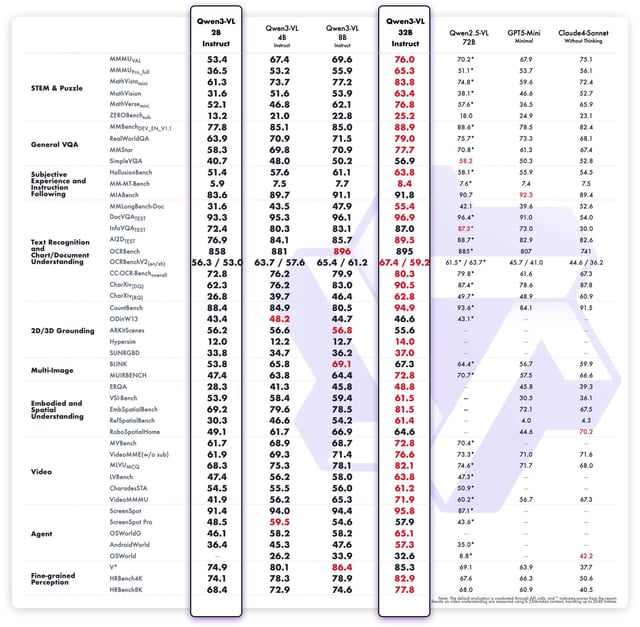
🚀 Rendimiento y estándares inigualables
- 🎯 Logros precisión de vanguardia En los principales conjuntos de datos de descripción visual, sometidos a rigurosas pruebas comparativas con las tareas de COCO Caption y VQA.
- 📈 Demuestra Capacidad superior para seguir instrucciones, validado mediante evaluaciones humanas por su excepcional relevancia y coherencia.
- 💡 Supera en rendimiento a las versiones anteriores de Qwen VL. en la calidad de la generación de contenido multimodal y la alineación precisa de las instrucciones.
- 🔒 Exposiciones rendimiento de disparo cero robusto en tareas de diálogo visual complejas en comparación con los modelos de referencia.
🌟 Características y ventajas principales
- ✨ Descripciones precisas de las imágenes: Optimizado para generar descripciones de imágenes excepcionalmente claras y precisas a partir de las instrucciones del usuario.
- 💬 Diálogos visuales atractivos: Capaz de comprender contextos visuales complejos y participar en diálogos visuales dinámicos.
- 🎨 Generación de contenido creativo: Genera contenido visual altamente relevante e innovador directamente a partir de indicaciones textuales.
- ✔️ Alta alineación de las instrucciones: Minimiza el contenido irrelevante o alucinatorio al garantizar una estricta concordancia con las instrucciones del usuario.
- 🖼️ Procesamiento eficiente de alta resolución: Maneja imágenes grandes y de alta resolución de manera eficiente con una comprensión visual precisa.
- 🌍 Salida multilingüe: Admite la salida de texto multilingüe, demostrando una gran fluidez lingüística en varios idiomas.
- 🔌 Fácil integración: Diseñado para una fácil integración en flujos de trabajo de creación de contenido basados en IA y asistentes visuales interactivos.
💰 Precios de la API Qwen3 VL 32B
- ➡️ Aporte: 0,735 dólares / 1 millón de tokens
- ⬅️ Producción: $2,94 / 1 millón de tokens
💡 Casos de uso versátiles
- 📸 Generación automática de subtítulos para imágenes: Ideal para sistemas de gestión de activos digitales, ya que proporciona descripciones instantáneas y precisas.
- 🗣️ Control de calidad visual y atención al cliente: Mejora los bots de atención al cliente con capacidades interactivas de respuesta a preguntas visuales.
- ✍️ Marketing y creación de contenido: Permite generar contenido para campañas de marketing, redes sociales y narración creativa mediante imágenes.
- 🚶♀️ Asistencia para personas con discapacidad visual: Describe las escenas visuales con gran detalle, ofreciendo un apoyo inestimable.
- 🔍 Búsqueda multimedia mejorada: Mejora las capacidades del motor de búsqueda mediante una comprensión avanzada del contexto basada en imágenes.
- 📚 Aplicaciones educativas: Permite incluir explicaciones visuales interactivas y tutoriales, lo que hace que el aprendizaje sea más atractivo.
💻 Ejemplo de código para la integración
A continuación se muestra un fragmento de código típico que demuestra cómo interactuar con la API de instrucciones Qwen3 VL 32B.
import openai client = openai.OpenAI( api_key="YOUR_API_KEY", # Reemplazar con tu clave API real base_url="https://api.your-provider.com/v1" # Reemplazar con tu endpoint de API ) response = client.chat.completions.create( model="alibaba/qwen3-vl-32b-instruct", messages=[ {"role": "system", "content": "Eres un asistente útil que puede describir imágenes."}, {"role": "user", "content": [ {"type": "text", "text": "¿Qué hay en esta imagen?"}, {"type": "image_url", "image_url": {"url": "https://example.com/image.jpg"}} ]} ], max_tokens=500 ) print(response.choices[0].message.content) 🆚 Qwen3 VL 32B Instruct frente a otros modelos líderes
vs. Qwen3 VL 32B Base:
El Versión instructiva Está meticulosamente ajustado para una adherencia superior a las instrucciones, lo que produce descripciones más precisas y relevantes para el contexto. En cambio, el modelo Base se centra principalmente en la comprensión multimodal general.
vs. OpenAI GPT-4 (con visión):
Qwen3 VL 32B Instruct está diseñado y optimizado específicamente para seguir instrucciones especializadas y generar contenido visual, lo que se traduce en menos errores de interpretación en las entradas visuales. Si bien GPT-4 ofrece capacidades de IA más generales, puede ser menos especializado en la correcta ejecución de instrucciones visuales.
vs. Claude 4.5 Visual:
Qwen3 VL 32B Instruct ofrece una descripción de imágenes y una calidad de diálogo superiores, con especial énfasis en las instrucciones visuales. Claude, si bien destaca en el razonamiento basado en texto y en la gestión de contextos más amplios, suele ofrecer una especialización visual ligeramente menor.
vs. DeepSeek V3.1:
Qwen3 VL 32B Instruct destaca en la generación de contenido detallado y en tareas de visualización sofisticadas. DeepSeek, por otro lado, está más orientado a la búsqueda semántica de imágenes y a las funcionalidades de recuperación.
❓ Preguntas frecuentes (FAQ)
P: ¿Para qué se diseñó principalmente Qwen3 VL 32B Instruct?
A: Se trata de un modelo especializado de visión y lenguaje, optimizado para seguir instrucciones en tareas como la descripción precisa de imágenes, el diálogo visual atractivo y la generación inteligente de contenido a partir de entradas visuales e indicaciones textuales.
P: ¿Cómo se compara Qwen3 VL 32B Instruct con su versión Base?
A: La versión Instruct está específicamente optimizada para mejorar la adherencia a las instrucciones, lo que da como resultado descripciones más precisas y relevantes para el contexto, a diferencia del modelo Base, que proporciona una comprensión multimodal general.
P: ¿Cuáles son las principales ventajas de usar Qwen3 VL 32B Instruct?
A: Entre las principales ventajas se incluyen una descripción precisa de las imágenes, sólidas capacidades de diálogo visual, generación de contenido creativo con alta alineación con las instrucciones, manejo eficiente de imágenes de alta resolución y salida de texto multilingüe.
P: ¿Se puede utilizar Qwen3 VL 32B Instruct en aplicaciones del mundo real?
R: Por supuesto. Es ideal para la generación automática de subtítulos para imágenes, preguntas y respuestas visuales en atención al cliente, creación de contenido mediante inteligencia artificial, asistencia a usuarios con discapacidad visual, mejora de la búsqueda multimedia y herramientas educativas interactivas.
P: ¿Cuál es la estructura de precios para la API Qwen3 VL 32B?
A: El precio es escalonado: la entrada cuesta 0,735 dólares por cada millón de tokens, y la salida cuesta 2,94 dólares por cada millón de tokens.
Campo de juegos de IA

