 OpenAI - ChatGPT, Sora
OpenAI - ChatGPT, Sora Google - Gemini, Nano Banana
Google - Gemini, Nano Banana Antrópico - Claude
Antrópico - Claude xAI - Grok
xAI - Grok Búsqueda profunda
Búsqueda profunda Alibaba - Reina
Alibaba - Reina ByteDance - Lo mejor de ByteDance
ByteDance - Lo mejor de ByteDance Todos los modelos
Todos los modelos Planes empresariales
Planes empresariales Desarrollo de aplicaciones de IA
Desarrollo de aplicaciones de IA API de traducción de IA
API de traducción de IA Servicio de SEO/GEO con IA
Servicio de SEO/GEO con IA Servicio de relaciones públicas geooptimizado
Servicio de relaciones públicas geooptimizado Servicio de extracción de datos web
Servicio de extracción de datos web OpenClaw
OpenClaw Las mejores herramientas de IA
Las mejores herramientas de IA Los mejores robots de IA
Los mejores robots de IA
 Acceso
Acceso



const main = async () => {
const response = await fetch('https://api.ai.cc/v2/generate/video/alibaba/generation', {
method: 'POST',
headers: {
Authorization: 'Bearer ',
'Content-Type': 'application/json',
},
body: JSON.stringify({
model: 'alibaba/wan2.1-t2v-turbo',
prompt: 'A DJ on the stand is playing, around a World War II battlefield, lots of explosions, thousands of dancing soldiers, between tanks shooting, barbed wire fences, lots of smoke and fire, black and white old video: hyper realistic, photorealistic, photography, super detailed, very sharp, on a very white background',
aspect_ratio: '16:9',
}),
}).then((res) => res.json());
console.log('Generation:', response);
};
main()
import requests
def main():
url = "https://api.ai.cc/v2/generate/video/alibaba/generation"
payload = {
"model": "alibaba/wan2.1-t2v-turbo",
"prompt": "A DJ on the stand is playing, around a World War II battlefield, lots of explosions, thousands of dancing soldiers, between tanks shooting, barbed wire fences, lots of smoke and fire, black and white old video: hyper realistic, photorealistic, photography, super detailed, very sharp, on a very white background",
"aspect_ratio": "16:9",
}
headers = {"Authorization": "Bearer ", "Content-Type": "application/json"}
response = requests.post(url, json=payload, headers=headers)
print("Generation:", response.json())
if __name__ == "__main__":
main()

.webp)
Detalles del producto
Wan2.1 Turbo de Alibaba es un modelo de IA de texto a video de vanguardia, diseñado específicamente para generación eficiente equilibra un rendimiento superior y una velocidad. Procesa entradas de contexto extensas y sobresale en la producción. vídeos de alta calidad, que presenta una dinámica temporal fluida y una alineación semántica precisa entre las descripciones textuales y las salidas visuales.
✨ Especificaciones técnicas
Indicadores de rendimiento
- ✅ VQA-bench: Logra una mayor eficiencia del turbocompresor; las cifras específicas están disponibles bajo petición.
- ✅ Razonamiento multimodal: Demuestra una gran capacidad de razonamiento tanto en formato de vídeo como de texto.
- ✅ Recuperación multimodal: Garantiza una precisión de recuperación sólida, optimizada para tareas de visión y lenguaje a gran escala.
Métricas de rendimiento
Wan2.1 Turbo ofrece excelente calidad de generación de vídeo al tiempo que reduce significativamente el tiempo de inferencia y los recursos computacionales en comparación con modelos más grandes. Esto lo hace excepcionalmente adecuado para aplicaciones en tiempo real o sensibles al costoEl modelo conserva las características distintivas de Alibaba en cuanto a movimiento dinámico, relaciones espaciales y precisión compositiva.
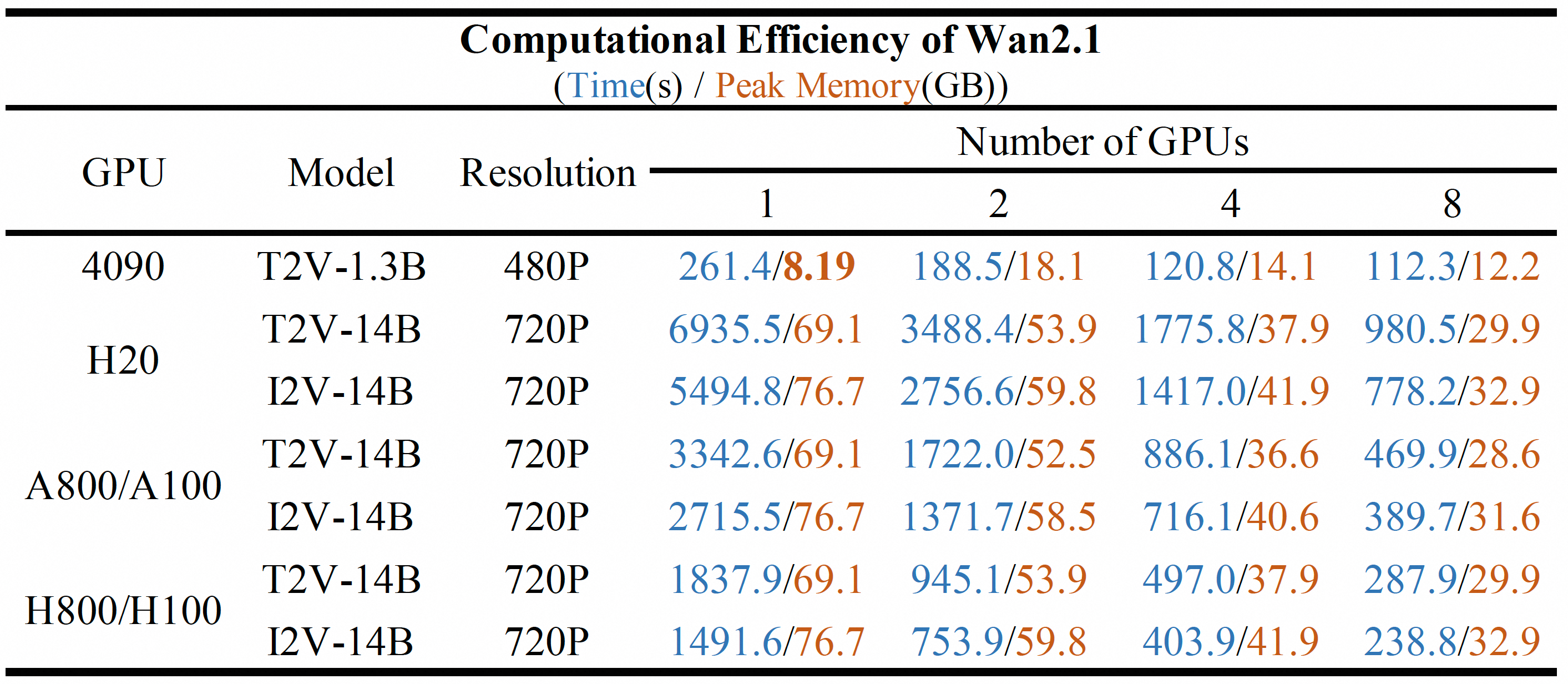
Capacidades clave
- 💡 Fusión de visión y lenguaje: Integra y genera contenido de vídeo a la perfección a partir de descripciones textuales detalladas.
- 🚀 Generación en tiempo real: Cuenta con una velocidad de inferencia turboalimentada, lo que permite obtener salidas de vídeo más rápidas sin comprometer sustancialmente la calidad.
- 🧠 Comprensión del contexto: Mantiene un razonamiento sólido de múltiples pasos y garantiza la coherencia narrativa en todos los vídeos generados.
Precios de API
💰 Justo $0.189 por video
🎯 Casos de uso óptimos
- 🎥 Generación de texto a vídeo: Ideal para la síntesis de vídeo rápida y de alta calidad directamente a partir de texto.
- ⚡ Creación de contenido en tiempo real: Ideal para aplicaciones que requieren tiempos de respuesta de vídeo rápidos y entrega de contenido dinámico.
- 🔗 Flujos de trabajo multimodales: Apoya proyectos que integran datos de visión y lenguaje para inteligencia empresarial, entretenimiento y producción de medios creativos.
💻 Ejemplo de código
📊 Comparación con otros modelos
Vs. Wan2.2-T2V: Wan2.1 Turbo ofrece una inferencia significativamente más rápida y una mayor rentabilidad, aunque con una resolución máxima de generación y un tamaño de modelo ligeramente inferiores.
Vs. Géminis 2.5 Flash: Ofrece una precisión multimodal competitiva, además de estar altamente optimizada para la velocidad.
Vs. OpenAI GPT-4 Vision: Presenta una ventana de contexto más pequeña, pero resulta más rentable para tareas específicas de generación de vídeo.
Vs. Qwen3-235B-A22B: Se centra en la eficiencia turbo, mientras que Wan2.1 Turbo ofrece una precisión de recuperación ligeramente mejor en contextos específicos.
⚠️ Limitaciones
Algunas salidas generadas pueden incluir ocasionalmente artefactos menores o presentar texturas menos detalladas en comparación con los modelos Wan2.2 más grandes. Sin embargo, estos problemas a menudo se pueden minimizar eficazmente mediante ingeniería rápida o técnicas de postprocesamiento.
❓ Preguntas frecuentes
P: ¿Qué arquitectura computacional permite la excepcional velocidad de inferencia de Wan2.1 Turbo?
A: Wan2.1 Turbo emplea una arquitectura híbrida revolucionaria que combina redes expertas dispersas con rutas computacionales dinámicas. Esto permite que el modelo active solo los subconjuntos de parámetros relevantes, reduciendo la sobrecarga computacional en un 67 % en comparación con los modelos densos. Además, integra mecanismos avanzados de cuantización y atención de bajo consumo de memoria, junto con un novedoso mecanismo de omisión de tokens para el procesamiento en tiempo real de tokens semánticamente críticos.
P: ¿Cómo mantiene Wan2.1 Turbo la calidad a pesar de la optimización agresiva?
A: El modelo mantiene una calidad excepcional mediante una sofisticada extracción de conocimiento de arquitecturas WAN más amplias, preservando patrones de razonamiento críticos. Incorpora procesos de refinamiento en varias etapas que ajustan dinámicamente la profundidad de procesamiento según la complejidad de la tarea, lo que garantiza respuestas rápidas para consultas sencillas y un análisis más profundo para las complejas. Además, la monitorización continua del espacio latente detecta y corrige posibles degradaciones de la calidad en tiempo real.
P: ¿Qué aplicaciones en tiempo real se benefician más de las optimizaciones de latencia de Wan2.1 Turbo?
A: Wan2.1 Turbo destaca en ámbitos donde la latencia es crucial, como el análisis de operaciones de alta frecuencia (con requisitos inferiores a 10 ms), las plataformas educativas interactivas que admiten miles de usuarios simultáneos, la traducción multilingüe en tiempo real en conversaciones en directo, los sistemas de toma de decisiones para vehículos autónomos que requieren una interpretación ambiental instantánea y las operaciones de atención al cliente a gran escala, donde la coherencia y la velocidad de respuesta influyen directamente en la satisfacción del usuario y la eficiencia operativa.
P: ¿Cómo se compara la eficiencia energética de este modelo con la de las arquitecturas convencionales?
A: Wan2.1 Turbo logra una eficiencia energética sin precedentes gracias a la gestión de energía sensible al contexto, la aritmética de precisión adaptativa y la sofisticada optimización de la jerarquía de caché. Los resultados de las pruebas de rendimiento demuestran una reducción del 58 % en el consumo de energía por inferencia, manteniendo el 94 % de las métricas de calidad de los modelos sin comprometer, lo que lo hace excepcionalmente adecuado para implementaciones en el borde de la red e iniciativas de computación respetuosas con el medio ambiente.
P: ¿Qué flexibilidad de implementación ofrece Wan2.1 Turbo en diferentes plataformas de hardware?
A: El modelo ofrece una adaptabilidad de hardware excepcional gracias a su arquitectura modular, que permite la reconfiguración dinámica de diversas unidades de procesamiento. Incluye optimización especializada para clústeres de GPU con paralelismo tensorial eficiente, implementación de CPU con utilización avanzada del conjunto de instrucciones y compatibilidad con hardware neuromórfico emergente. El marco de implementación incluye detección y configuración automáticas de hardware, lo que permite transiciones fluidas entre infraestructura en la nube, dispositivos periféricos y plataformas móviles, manteniendo características de rendimiento consistentes.
Campo de juegos de IA

