 OpenAI - ChatGPT, Sora
OpenAI - ChatGPT, Sora Google - Gemini, Nano Banana
Google - Gemini, Nano Banana Antrópico - Claude
Antrópico - Claude xAI - Grok
xAI - Grok Búsqueda profunda
Búsqueda profunda Alibaba - Reina
Alibaba - Reina ByteDance - Lo mejor de ByteDance
ByteDance - Lo mejor de ByteDance Todos los modelos
Todos los modelos Planes empresariales
Planes empresariales Desarrollo de aplicaciones de IA
Desarrollo de aplicaciones de IA API de traducción de IA
API de traducción de IA Servicio de SEO/GEO con IA
Servicio de SEO/GEO con IA Servicio de relaciones públicas geooptimizado
Servicio de relaciones públicas geooptimizado Servicio de extracción de datos web
Servicio de extracción de datos web OpenClaw
OpenClaw Las mejores herramientas de IA
Las mejores herramientas de IA Los mejores robots de IA
Los mejores robots de IA
 Acceso
Acceso



const main = async () => {
const response = await fetch('https://api.ai.cc/v2/generate/video/alibaba/generation', {
method: 'POST',
headers: {
Authorization: 'Bearer ',
'Content-Type': 'application/json',
},
body: JSON.stringify({
model: 'alibaba/wan2.2-t2v-plus',
prompt: 'A DJ on the stand is playing, around a World War II battlefield, lots of explosions, thousands of dancing soldiers, between tanks shooting, barbed wire fences, lots of smoke and fire, black and white old video: hyper realistic, photorealistic, photography, super detailed, very sharp, on a very white background',
aspect_ratio: '16:9',
}),
}).then((res) => res.json());
console.log('Generation:', response);
};
main()
import requests
def main():
url = "https://api.ai.cc/v2/generate/video/alibaba/generation"
payload = {
"model": "alibaba/wan2.2-t2v-plus",
"prompt": "A DJ on the stand is playing, around a World War II battlefield, lots of explosions, thousands of dancing soldiers, between tanks shooting, barbed wire fences, lots of smoke and fire, black and white old video: hyper realistic, photorealistic, photography, super detailed, very sharp, on a very white background",
"aspect_ratio": "16:9",
}
headers = {"Authorization": "Bearer ", "Content-Type": "application/json"}
response = requests.post(url, json=payload, headers=headers)
print("Generation:", response.json())
if __name__ == "__main__":
main()

.webp)
Detalles del producto
Alibaba Wan2.2 es un sistema de última generación modelo de IA Diseñado meticulosamente para aplicaciones avanzadas comprensión multimodalIntegra a la perfección entradas de texto y de visión, ofreciendo sólidas capacidades para el procesamiento de contextos amplios y proporcionando una precisión superior en tareas complejas de conversión de texto a visión y en intrincados desafíos de razonamiento.
✨ Especificaciones técnicas
Indicadores de rendimiento
- ✅ VQA-bench: 78,3%
- ✅ Razonamiento multimodal: 52,7%
- ✅ Recuperación multimodal: 81,9%
Métricas de rendimiento (Wan2.1)
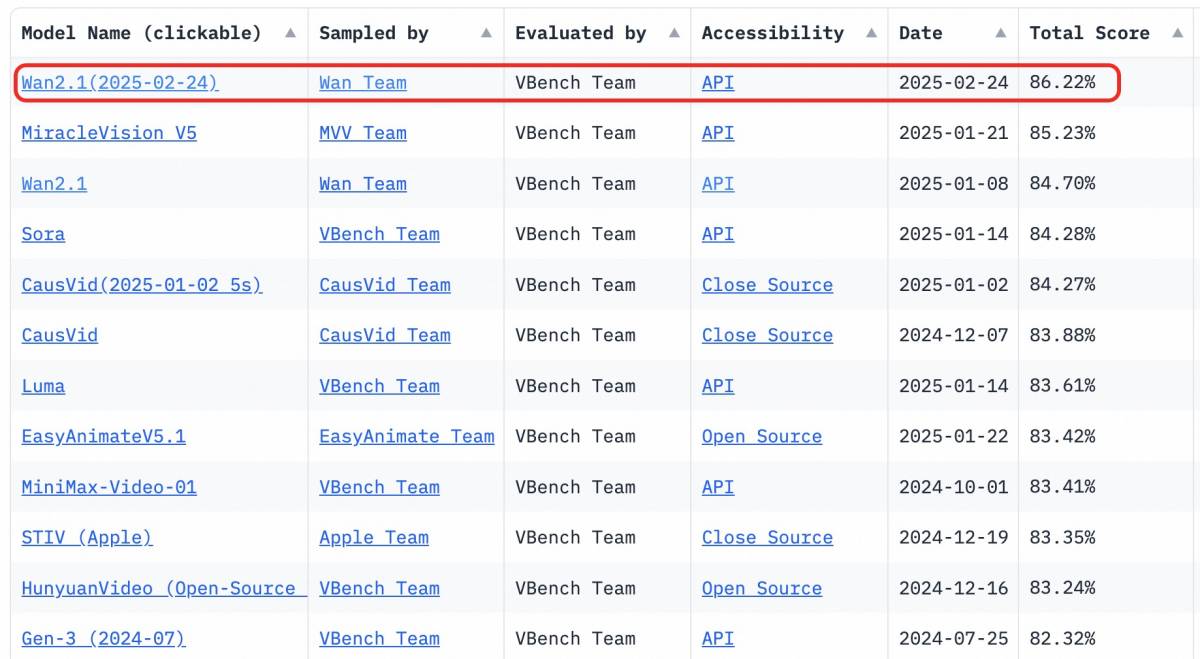
Wan2.1 lidera con una impresionante puntuación general. Puntuación VBench de 86,22%Demuestra un rendimiento excepcional en movimiento dinámico, relaciones espaciales, precisión cromática e interacción entre múltiples objetos. El entrenamiento de modelos de vídeo fundamentales requiere una gran capacidad de procesamiento y acceso a conjuntos de datos amplios y de alta calidad. El acceso abierto a estos modelos avanzados reduce drásticamente las barreras, lo que permite a más empresas crear contenido visual personalizado y de alta calidad de forma rentable.
Capacidades clave
- 💡 Fusión visión-lenguaje: Destaca por su capacidad para interpretar y generar respuestas precisas mediante la combinación perfecta de datos de imagen y texto.
- 💡 Razonamiento avanzado: Demuestra una gran capacidad de razonamiento en múltiples pasos a través de diversas modalidades para un análisis profundo y una comprensión compleja.
💲 Precios de API
- 🎥 480P: $0.105/video
- 🎥 1080P: $0.525/video
🚀 Casos de uso óptimos
- ✅ Análisis multimodal: Mejorar la comprensión mediante la combinación experta de imágenes y texto.
- ✅ Sistema de respuesta a preguntas visuales (VQA): Proporcionar respuestas precisas y contextualizadas basadas en la integración de imágenes y texto.
- ✅ Recuperación multimodal: Permite la búsqueda y recuperación eficiente de información tanto en el ámbito de la visión como en el del lenguaje.
- ✅ Inteligencia empresarial: Facilitamos la interpretación de datos complejos mediante la integración de contenido visual con análisis textuales para obtener información más detallada.
💻 Ejemplo de código
📊 Comparación con otros modelos líderes
- Vs. Géminis 2.5 Flash: Alibaba Wan2.2 ofrece una mayor precisión multimodal (78,3% frente al 70,8 % de VQA-bench), lo que la convierte en una opción superior para tareas integradas de visión y lenguaje.
- Vs. OpenAI GPT-4 Vision: Wan2.2 proporciona una ventana de contexto significativamente más grande (65 mil vs. 32K tokens de texto), lo que permite conversaciones más extensas y coherentes con imágenes integradas.
- Vs. Qwen3-235B-A22B: Alibaba Wan2.2 demuestra una precisión de recuperación multimodal superior (81,9% frente a un ~78% estimado), optimizándolo para flujos de trabajo exigentes de lenguaje de visión a gran escala.
⚠️ Limitaciones
En ocasiones, los vídeos generados pueden contener elementos no deseados, como artefactos de texto o marcas de agua. Si bien el uso de mensajes negativos puede ayudar a mitigar estos problemas, no los elimina por completo.
🔗 Integración de API
Alibaba Wan2.2 es fácilmente accesible a través de la API de IA/MLSe dispone de documentación completa para facilitar un proceso de integración fluido y eficiente.
❓ Preguntas frecuentes (FAQ)
A: Alibaba Wan2.2 es un modelo de IA avanzado diseñado para la comprensión multimodal, que integra específicamente entradas de texto y visión para el razonamiento complejo y tareas de conversión de texto a visión de alta precisión.
A: Wan2.2 demuestra una mayor precisión multimodal (78,3 % VQA-bench) en comparación con Gemini 2.5 Flash (70,8 %), lo que lo hace particularmente eficaz para tareas integradas de visión y lenguaje.
A: Sus capacidades principales incluyen una sólida fusión de visión y lenguaje para interpretar y generar contenido a partir de datos combinados de imagen y texto, y un razonamiento avanzado de múltiples pasos en diferentes modalidades.
A: En ocasiones, los vídeos generados pueden contener elementos no deseados, como artefactos de texto o marcas de agua. Si bien las advertencias negativas pueden mitigar estos problemas, no los eliminan por completo.
A: Alibaba Wan2.2 es fácilmente accesible a través de la API de IA/ML, y se proporciona documentación completa para guiar el proceso de integración.
Campo de juegos de IA

