 OpenAI - ChatGPT, Sora
OpenAI - ChatGPT, Sora Google - Gemini, Nano Banana
Google - Gemini, Nano Banana Anthropique - Claude
Anthropique - Claude xAI - Grok
xAI - Grok Recherche profonde
Recherche profonde Alibaba - Qwen
Alibaba - Qwen ByteDance - Le meilleur de ByteDance
ByteDance - Le meilleur de ByteDance Tous les modèles
Tous les modèles Plans d'entreprise
Plans d'entreprise Développement d'applications d'IA
Développement d'applications d'IA API de traduction IA
API de traduction IA Service SEO/GEO IA
Service SEO/GEO IA Service de relations publiques géo-optimisé
Service de relations publiques géo-optimisé Service de web scraping
Service de web scraping OpenClaw
OpenClaw Meilleurs outils d'IA
Meilleurs outils d'IA Les meilleurs robots IA
Les meilleurs robots IA
 Se connecter
Se connecter



const { OpenAI } = require('openai');
const api = new OpenAI({
baseURL: 'https://api.ai.cc/v1',
apiKey: '',
});
const main = async () => {
const result = await api.chat.completions.create({
model: 'deepseek/deepseek-reasoner-v3.1-terminus',
messages: [
{
role: 'system',
content: 'You are an AI assistant who knows everything.',
},
{
role: 'user',
content: 'Tell me, why is the sky blue?'
}
],
});
const message = result.choices[0].message.content;
console.log(`Assistant: ${message}`);
};
main();
import os
from openai import OpenAI
client = OpenAI(
base_url="https://api.ai.cc/v1",
api_key="",
)
response = client.chat.completions.create(
model="deepseek/deepseek-reasoner-v3.1-terminus",
messages=[
{
"role": "system",
"content": "You are an AI assistant who knows everything.",
},
{
"role": "user",
"content": "Tell me, why is the sky blue?"
},
],
)
message = response.choices[0].message.content
print(f"Assistant: {message}")


Détails du produit
✨ DeepSeek V3.1 Terminus : IA de raisonnement hybride avancée
Le Terminus DeepSeek V3.1 représente une évolution significative des modèles d'IA de raisonnement hybride à grande échelle, conçus avec une précision méticuleuse pour les tâches de raisonnement les plus exigeantes. Cette mise à jour de la série DeepSeek V3 vise à offrir des performances inégalées. stabilité, rationalisé flux de travail agent/outilet robuste capacités de raisonnement multi-étapesC'est une solution idéale pour les applications complexes telles que le codage avancé, la navigation Web intuitive et l'automatisation en ligne de commande, alliant harmonieusement une puissante capacité de modélisation à des modes d'inférence flexibles.
⚙️ Spécifications techniques
- Type de modèle : Modèle de langage à grande échelle hybride de type mélange d'experts (MoE)
- Paramètres totaux : 671 milliards
- Paramètres actifs par passe avant : 37 milliards
- Modes de raisonnement hybrides : Prend en charge les deux mode « réflexion » (raisonnement interne complexe, planification des outils) et mode « non-pensée » (Réponses directes plus rapides) au sein du même réseau.
- Taille de la fenêtre contextuelle : Jusqu'à 128 000 jetons, facilitant un traitement contextuel approfondi et un raisonnement en chaîne prolongé.
- Capacités de l'agent : Comprend des agents intégrés spécialisés, notamment Code Agent, Search Agent, Browse Agent et Terminal Agent.
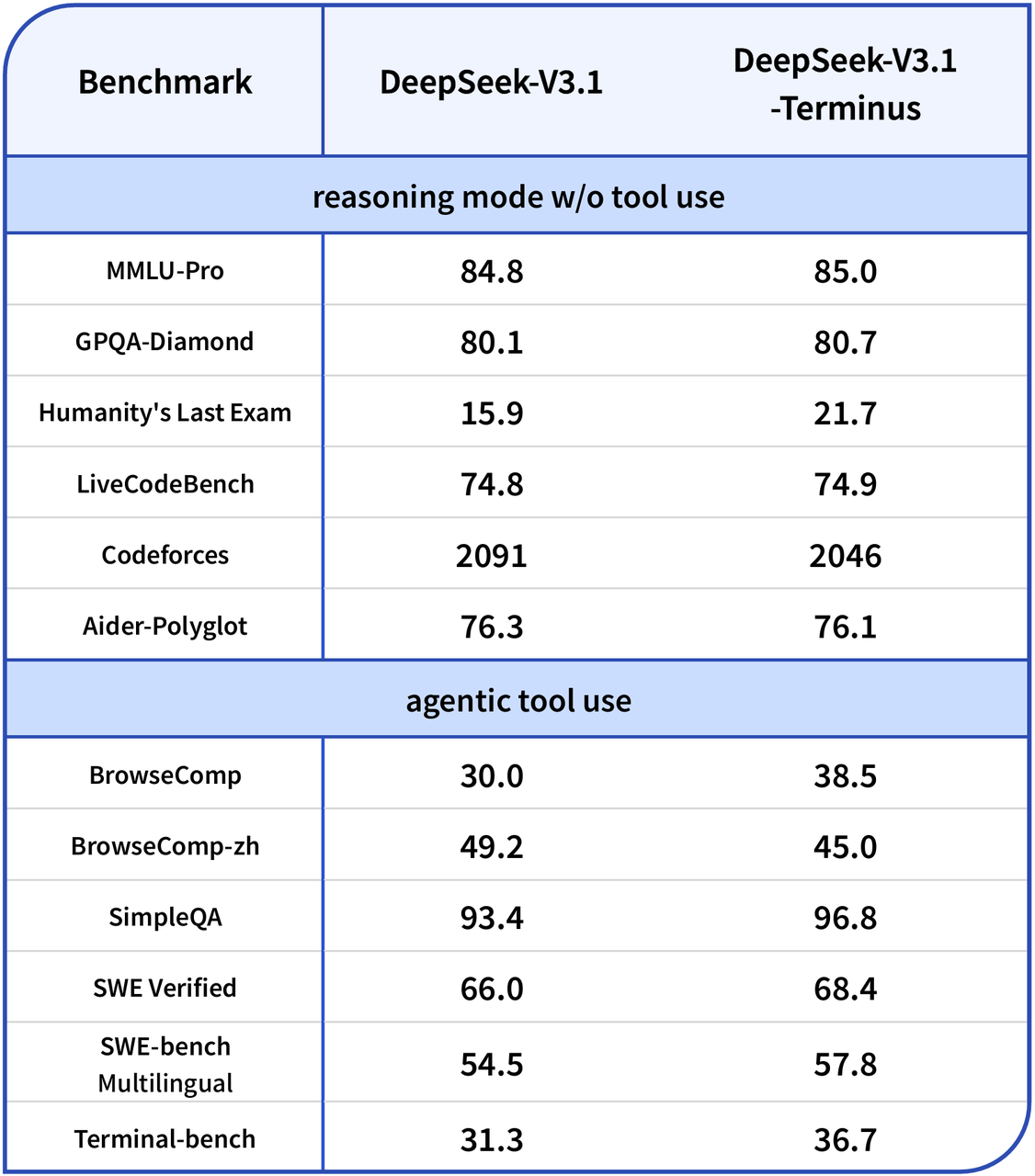
📊 Indicateurs de performance
- Raisonnement MMLU-Pro : Amélioration de 84,8 à 85.0 (Terminus)
- GPQA-Diamant : 80,7
- Le dernier examen de l'humanité : Augmentation significative de 15,9 à 21.7
- LiveCodeBench : Gain marginal à 74,9
- Score Codeforces : Légère variation autour de 2046
- Vérification en génie logiciel : Amélioré de 66,0 à 68,4
🌟 Principales caractéristiques du terminal DeepSeek V3.1
- Fenêtre de contexte large : Processus jusqu'à 128 000 jetons, permettant la compréhension de documents volumineux et d'un raisonnement complexe à plusieurs étapes.
- Intégration améliorée des agents : Offre des flux de travail d'agents multi-étapes optimisés avec une fiabilité supérieure dans l'appel d'outils, y compris des agents spécialisés pour génération de code, recherche, navigation, et opérations terminales.
- Améliorations en matière d'efficacité : Réalise une performance remarquable Réduction de 20 % à 50 % en consommation moyenne de jetons en mode de raisonnement, tout en maintenant ou en améliorant la qualité de la sortie.
- Amélioration de la cohérence linguistique : Réduit considérablement les problèmes d'insertion aléatoire de caractères et de mélange indésirable de langues, garantissant des résultats plus fluides et plus cohérents.
- Performances de codage supérieures : Offre des capacités avancées de génération de code, permettant de créer des applications complexes et une interaction transparente avec des moteurs de jeu comme Godot, sans erreurs de compilation.
💰 Tarification de l'API
- 1 million de jetons d'entrée : 0,294 $
- 1 million de jetons de production : 0,441 $
🎯 Principaux cas d'utilisation
- Complexe tâches de raisonnement en plusieurs étapes chaînes logiques exigeantes.
- Automatisé codage et assistance au développement logiciel.
- Automatisation en ligne de commande et fonctionnalités avancées script.
- Extraction de données Web et récupération sophistiquée via agents de navigation.
- Questions-réponses avancées nécessitant une compréhension approfondie du contexte.
- Synthèse et résumé de la recherche longs documents.
💻 Exemple de code
🔍 Comparaison avec d'autres modèles
contre GPT-4: Bien que GPT-4 soit reconnu pour sa polyvalence et ses productions créatives, excellant dans le raisonnement général et la qualité des dialogues, Terminus DeepSeek se distingue par son excellence en flux de travail agents et très efficace appel d'outil en plusieurs étapes, souvent à des coûts de jetons inférieurs.
contre Claude 4.1: Claude 4.1 est réputé pour son raisonnement intuitif et créatif en plusieurs étapes et pour son enchaînement fluide des idées. Terminus DeepSeek offre une correspondance étroite dans les flux de travail complexes impliquant des agents, en particulier lorsque la précision est requise. intégration d'outils et explicite planification sont primordiales.
contre DeepSeek R1: Terminus offre une qualité de raisonnement comparable, mais avec les avantages supplémentaires de temps de réponse plus rapides et une consommation réduite de jetons de sortie.
contre DeepSeek V3.1: Terminus Améliore considérablement la stabilité du langage, élimine quasiment tous les bugs d'affichage et améliore globalement coordination agent/outil pour une expérience utilisateur plus fluide.
❓ Foire aux questions (FAQ)
Q1 : Quel est l'objectif principal de DeepSeek V3.1 Terminus ?
A1 : DeepSeek V3.1 Terminus est principalement axé sur l'amélioration capacités de raisonnement hybride pour les tâches complexes nécessitant une chaîne de raisonnement, avec une stabilité améliorée, des flux de travail agent/outil et un raisonnement multi-étapes fiable dans diverses applications.
Q2 : En quoi la taille de sa fenêtre de contexte est-elle avantageuse pour les utilisateurs ?
A2 : Avec une fenêtre de contexte substantielle allant jusqu'à 128 000 jetonsTerminus peut traiter des documents incroyablement longs et maintenir des chaînes de raisonnement complexes, essentielles pour la recherche, la synthèse et les tâches analytiques approfondies.
Q3 : Quels sont les principaux gains d'efficacité à Terminus ?
A3 : Elle offre des gains d'efficacité significatifs, réduisant la consommation moyenne de jetons de 20 % à 50 % en mode de raisonnement tout en maintenant, voire en améliorant, la qualité de ses résultats par rapport aux versions précédentes.
Q4 : DeepSeek V3.1 Terminus peut-il gérer des tâches de codage avancées ?
A4 : Oui, il comporte performances de codage supérieures, capable de générer des applications complexes et d'interagir de manière fluide avec des moteurs de jeu comme Godot, garantissant un minimum d'erreurs de compilation et une fonctionnalité robuste.
Q5 : Qu’est-ce qui distingue Terminus dans les flux de travail multi-agents ?
A5 : Terminus se vante intégration améliorée des agents, offrant des flux de travail d'agents multi-étapes optimisés et une fiabilité accrue dans l'appel d'outils, y compris des agents spécialisés pour le codage, la recherche, la navigation et les opérations terminales.
Terrain de jeu de l'IA

