 OpenAI - ChatGPT, Sora
OpenAI - ChatGPT, Sora Google - Gemini, Nano Banana
Google - Gemini, Nano Banana Anthropique - Claude
Anthropique - Claude xAI - Grok
xAI - Grok Recherche profonde
Recherche profonde Alibaba - Qwen
Alibaba - Qwen ByteDance - Le meilleur de ByteDance
ByteDance - Le meilleur de ByteDance Tous les modèles
Tous les modèles Plans d'entreprise
Plans d'entreprise Développement d'applications d'IA
Développement d'applications d'IA API de traduction IA
API de traduction IA Service SEO/GEO IA
Service SEO/GEO IA Service de relations publiques géo-optimisé
Service de relations publiques géo-optimisé Service de web scraping
Service de web scraping OpenClaw
OpenClaw Meilleurs outils d'IA
Meilleurs outils d'IA Les meilleurs robots IA
Les meilleurs robots IA
 Se connecter
Se connecter



const { OpenAI } = require('openai');
const api = new OpenAI({
baseURL: 'https://api.ai.cc/v1',
apiKey: '',
});
const main = async () => {
const result = await api.chat.completions.create({
model: 'alibaba/qwen3-vl-32b-thinking',
messages: [
{
role: 'system',
content: 'You are an AI assistant who knows everything.',
},
{
role: 'user',
content: 'Tell me, why is the sky blue?'
}
],
});
const message = result.choices[0].message.content;
console.log(`Assistant: ${message}`);
};
main();
import os
from openai import OpenAI
client = OpenAI(
base_url="https://api.ai.cc/v1",
api_key="",
)
response = client.chat.completions.create(
model="alibaba/qwen3-vl-32b-thinking",
messages=[
{
"role": "system",
"content": "You are an AI assistant who knows everything.",
},
{
"role": "user",
"content": "Tell me, why is the sky blue?"
},
],
)
message = response.choices[0].message.content
print(f"Assistant: {message}")


Détails du produit
💡 Débloquer la cognition multimodale avancée avec Qwen3 VL 32B Thinking
Le Qwen3 VL 32B Réflexion Ce modèle représente une avancée majeure en matière de vision et de langage multimodal (VLM), conçu spécifiquement pour un raisonnement visuel et textuel complexe et un traitement sophistiqué et étendu des chaînes de pensée. Son mode innovant « Pensée seule » est optimisé avec précision pour les tâches analytiques approfondies, intégrant harmonieusement des entrées visuelles riches à une compréhension nuancée du langage. Cette puissante combinaison en fait le choix idéal pour les cas d'utilisation exigeant une cognition multimodale inégalée et des déductions logiques complexes.
🔧 Spécifications techniques
- ✓ Type de modèle : Modèle multimodal vision-langage (VLM)
- ✓ Taille du paramètre : 32 milliards de paramètres
- ✓ Entrée : Données visuelles + Invites textuelles
- ✓ Sortie : Réponses textuelles enrichies d'un raisonnement intégré et d'explications détaillées
- ✓ Architecture : Basé sur un transformeur avec des couches d'attention intermodales avancées, hautement optimisé pour les tâches de raisonnement complexes
- ✓ Mode Réflexion : Il comporte un pipeline de raisonnement en chaîne de pensée profond, permettant une inférence sophistiquée et multi-étapes.
- ✓ Latence : Optimisé pour un traitement par lots efficace, avec des considérations de latence adaptées à une profondeur analytique élevée
📊 Performances exceptionnelles dans les tâches complexes
Le Mode « Réflexion » Qwen3 VL 32B Elle excelle par sa capacité à permettre un raisonnement séquentiel et logique. Cette capacité s'avère extrêmement efficace pour résoudre des problèmes complexes à plusieurs étapes dans divers domaines.
- Programmation avancée : De la génération au débogage de structures de code complexes.
- Mathématiques supérieures : Résoudre des problèmes et des démonstrations mathématiques complexes.
- Déduction logique : Effectuer des raisonnements logiques complexes et résoudre des problèmes.
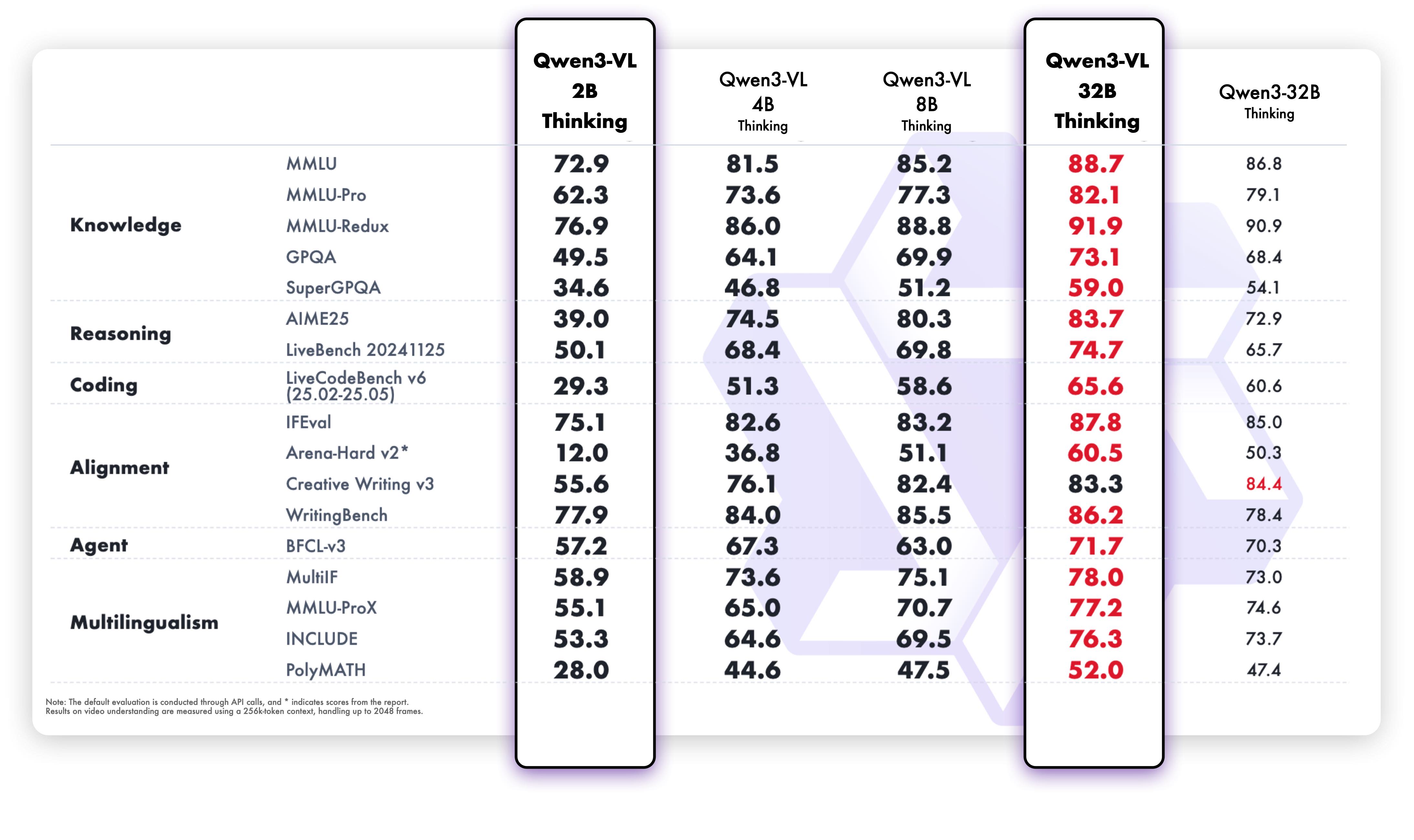
Aperçu visuel des capacités de raisonnement avancées du Qwen3 VL 32B.
★ Principales caractéristiques et avantages
- ✓ Raisonnement visuel et textuel supérieur : Capable d'interpréter des images complexes grâce à une compréhension contextuelle profonde.
- ✓ Chaîne de pensée étendue : Permet une analyse détaillée et étape par étape des réponses, essentielle à la résolution de problèmes complexes.
- ✓ Mode « Réflexion uniquement » dédié : Elle privilégie la profondeur et la précision cognitives à la vitesse, ce qui la rend parfaitement adaptée aux tâches exigeantes de niveau recherche.
- ✓ Intégration intermodale transparente : Intègre parfaitement les entrées visuelles et textuelles pour fournir des résultats complets et unifiés.
- ✓ Mémoire robuste et fenêtre de contexte : Permet de prendre en charge un contexte étendu, assurant une continuité inégalée dans les dialogues complexes ou les documents volumineux.
- ✓ Grande adaptabilité : Particulièrement adapté aux environnements de recherche scientifique, médicale et en IA nécessitant des capacités de raisonnement multimodal avancées.
💰 Tarification de l'API Qwen3 VL 32B
- ✓ Entrée : 0,735 $ / 1 million de jetons
- ✓ Sortie : 8,82 $ / 1 million de jetons
🔍 Divers cas d'utilisation pratiques
Exploitez la puissance exceptionnelle de la technologie Qwen3 VL 32B Thinking pour une large gamme d'applications exigeant une intelligence multimodale avancée :
- ✓ Assistant de recherche multimodal : Faciliter l'interprétation et le raisonnement très détaillés d'images dans un contexte académique et scientifique.
- ✓ Analyse d'imagerie médicale : Améliorez considérablement les informations diagnostiques en associant intelligemment les analyses visuelles à des requêtes textuelles complexes.
- ✓ Documentation juridique et financière : Analyser les graphiques, les figures et les contrats longs et détaillés qui intègrent des éléments visuels.
- ✓ Tutorat interactif par IA : Fournir des explications claires et progressives des concepts visuels, complétées par un soutien pédagogique textuel solide.
- ✓ Création de contenu dynamique : Créer des récits riches et bien argumentés, étayés par des images, pour des domaines variés tels que le journalisme, le marketing et la narration.
- ✓ Exploration de données multimodales avancée : Extraire des informations pertinentes et exploitables à partir de vastes ensembles de données combinant images et annotations textuelles.
💻 Exemple de code pour l'intégration
(Remarque : ceci est un espace réservé ; remplacez-le
📜 Qwen3 VL 32B Réflexion : Avantage comparatif
✓ vs. GPT-4o-VL : Qwen3 VL 32B Thinking offre un raisonnement visuel nettement amélioré et une cohérence de pensée supérieure sur de longues chaînes dans les tâches multimodales. En revanche, GPT-4o-VL excelle en fluidité conversationnelle, mais propose généralement des contextes de raisonnement plus courts.
✓ contre Claude 4.5 Haïku : L'architecture de Qwen3 VL 32B est optimisée avec précision pour une logique complexe et séquentielle au sein des combinaisons texte-image. Cela lui confère un avantage sur Claude 4.5 Haiku qui, malgré sa richesse en langage créatif et poétique, privilégie moins la longueur du raisonnement.
✓ vs. Gemini 2.5 Pro : Les deux modèles présentent de solides capacités en matière de raisonnement multimodal et dans les domaines STEM. Cependant, Qwen3 VL 32B Thinking se distingue par des fenêtres de contexte nettement plus larges (jusqu'à 256 000 jetons, extensible) et une optimisation dédiée pour une compréhension complète des vidéos et des documents de longue durée.
❓ Foire aux questions (FAQ)
Q1 : Que pense Qwen3 VL 32B ?
UN: Il s'agit d'un modèle de vision-langage multimodal de pointe (VLM) spécialement conçu pour le raisonnement visuel-textuel avancé et le traitement étendu de la chaîne de pensée, en particulier dans son mode « Pensée uniquement » pour les tâches analytiques approfondies.
Q2 : Quels sont les principaux avantages de son mode « Réflexion uniquement » ?
UN: Ce mode privilégie la profondeur cognitive et la précision analytique à la vitesse de traitement, ce qui le rend exceptionnellement bien adapté aux tâches exigeantes de niveau recherche qui nécessitent un raisonnement en plusieurs étapes, comme le codage complexe, les mathématiques avancées et les déductions logiques complexes.
Q3 : Comment Qwen3 VL 32B Thinking prend-il en charge les applications médicales ?
UN: Il est extrêmement performant en matière d'analyse d'images médicales, contribuant au diagnostic en reliant efficacement les images à des requêtes textuelles complexes et en fournissant des interprétations nuancées et raisonnées, ce qui en fait un outil puissant pour les professionnels de la santé.
Q4 : Quelle est la structure tarifaire de l'API Qwen3 VL 32B ?
UN: L'API est proposée au prix de 0,735 $ / 1 million de jetons pour les entrées et 8,82 $ / 1 million de jetons pour la sortie, conçu pour un traitement multimodal avancé et rentable.
Q5 : Comment sa fenêtre contextuelle se compare-t-elle à celle de concurrents comme Gemini 2.5 Pro ?
UN: Bien que les deux se concentrent sur le raisonnement multimodal, Qwen3 VL 32B Thinking offre des fenêtres de contexte nettement plus larges (jusqu'à 256 000 jetons, extensibleCette optimisation la rend supérieure pour le traitement et la compréhension de vidéos de longue durée et de documents volumineux, offrant une compréhension contextuelle plus approfondie et plus continue.
Terrain de jeu de l'IA

