 OpenAI - ChatGPT, Sora
OpenAI - ChatGPT, Sora Google - Gemini, Nano Banana
Google - Gemini, Nano Banana Antrópico - Claude
Antrópico - Claude xAI - Grok
xAI - Grok Busca profunda
Busca profunda Alibaba - Qwen
Alibaba - Qwen ByteDance - O Melhor da ByteDance
ByteDance - O Melhor da ByteDance Todos os modelos
Todos os modelos Planos Empresariais
Planos Empresariais Desenvolvimento de aplicações de IA
Desenvolvimento de aplicações de IA API de tradução de IA
API de tradução de IA Serviço de SEO/GEO com IA
Serviço de SEO/GEO com IA Serviço de Relações Públicas Otimizado por Geolocalização
Serviço de Relações Públicas Otimizado por Geolocalização Serviço de Web Scraping
Serviço de Web Scraping OpenClaw
OpenClaw Principais ferramentas de IA
Principais ferramentas de IA Os melhores robôs de IA
Os melhores robôs de IA
 Conecte-se
Conecte-se



const { OpenAI } = require('openai');
const api = new OpenAI({
baseURL: 'https://api.ai.cc/v1',
apiKey: '',
});
const main = async () => {
const result = await api.chat.completions.create({
model: 'deepseek/deepseek-v3.2-speciale',
messages: [
{
role: 'system',
content: 'You are an AI assistant who knows everything.',
},
{
role: 'user',
content: 'Tell me, why is the sky blue?'
}
],
});
const message = result.choices[0].message.content;
console.log(`Assistant: ${message}`);
};
main();
import os
from openai import OpenAI
client = OpenAI(
base_url="https://api.ai.cc/v1",
api_key="",
)
response = client.chat.completions.create(
model="deepseek/deepseek-v3.2-speciale",
messages=[
{
"role": "system",
"content": "You are an AI assistant who knows everything.",
},
{
"role": "user",
"content": "Tell me, why is the sky blue?"
},
],
)
message = response.choices[0].message.content
print(f"Assistant: {message}")


Detalhes do produto
DeepSeek V3.2 Especial é um modelo de linguagem de grande porte (LLM) avançado, focado em raciocínio, projetado para se destacar na resolução de problemas lógicos em várias etapas e no processamento de contexto extensivo. Com uma impressionante janela de contexto de até 128 mil tokensEle foi projetado para tarefas analíticas complexas. Um recurso inovador é o modo "somente pensar", permite que o modelo execute raciocínio interno silencioso antes de gerar qualquer resultado. Essa abordagem inovadora aprimora significativamente a precisão, a coerência factual e a dedução passo a passo, especialmente para consultas complexas.
Este modelo está em conformidade com as especificações de preenchimento de prefixo de bate-papo/FIM do DeepSeek e oferece recursos robustos de chamada de ferramentas. Acessível por meio de um endpoint Speciale por períodos limitados, ele preenche a lacuna entre a pesquisa de ponta e as aplicações práticas de raciocínio de IA, garantindo consistência analítica em diversos domínios, como geração de código, cálculos matemáticos e exploração científica.
✨ Especificações Técnicas ✨
- ✅ Arquitetura: Raciocínio baseado em texto LLM
- ✅ Comprimento do contexto: 128 mil tokens
- ✅ Capacidades: Bate-papo, raciocínio avançado, uso de ferramentas, preenchimento da MIF
- ✅ Dados de treinamento: Conjuntos de dados otimizados para raciocínio, alinhamento com feedback humano
🧠 Indicadores de desempenho 🧠
- 📈 Raciocínio Complexo: Demonstra estabilidade aprimorada em cadeias de múltiplas etapas, incluindo tarefas matemáticas e simbólicas.
- 💻 Síntese/Depuração de Código: Proporciona melhor explicabilidade do rastreamento, auxiliando nos processos de desenvolvimento e depuração.
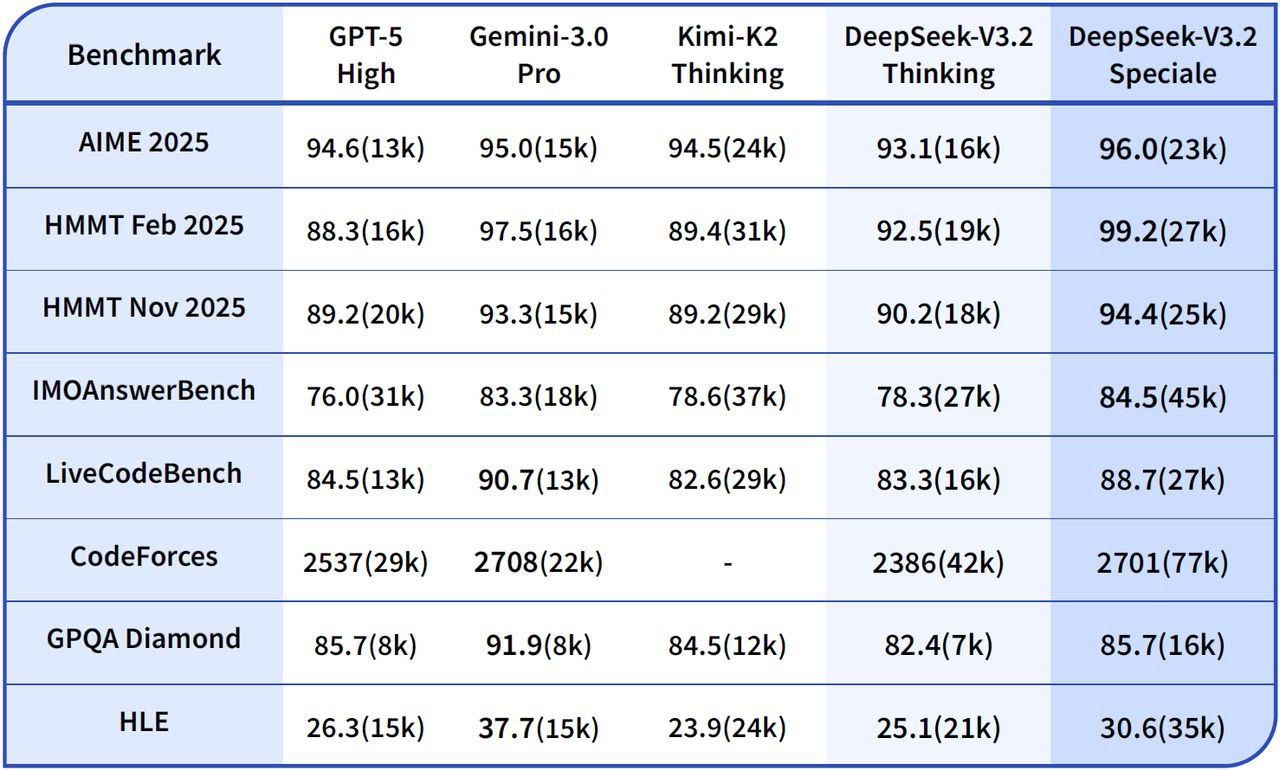
💡 Qualidade de Saída e Desempenho de Raciocínio 💡
🌟 Melhorias de Qualidade
- ✔️ Raciocínio coerente: Linhas de raciocínio consistentes mantêm a coerência ao longo de mais de 100 mil tokens.
- ✔️ Recuperação de erros aprimorada: Melhoria na recuperação de erros durante longas cadeias através do controle adaptativo da atenção.
- ✔️ Precisão simbólica superior: Supera os modelos DeepSeek anteriores em lógica multivariável e inferência de código.
- ✔️ Tom analítico equilibrado: Oferece explicações precisas, reduzindo ao mesmo tempo o sobreajuste ou a deriva semântica.
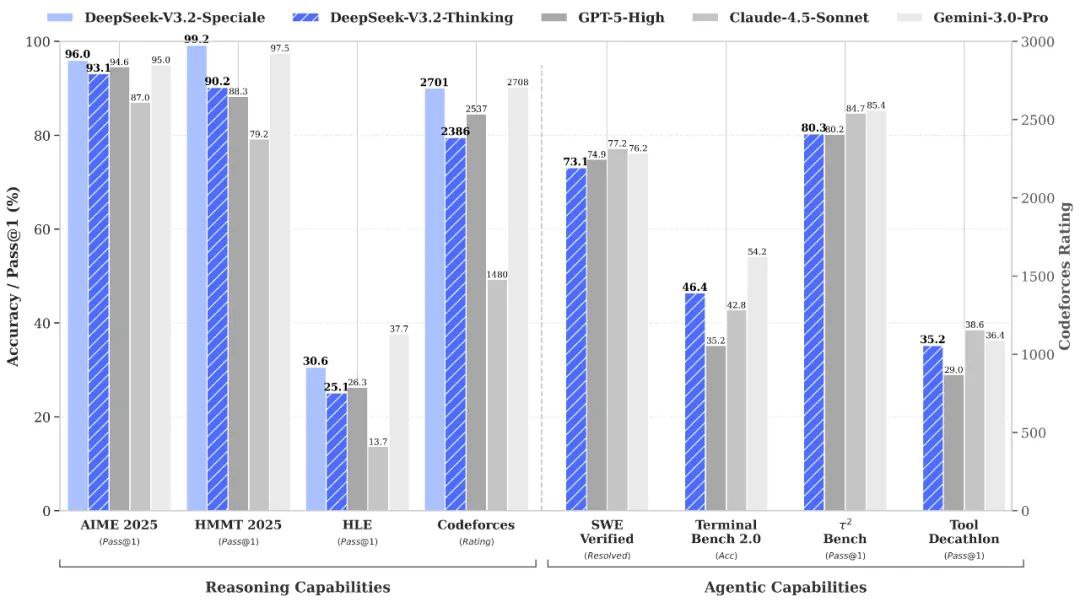
⚠️ Limitações
- Tom formal: Pode soar excessivamente formal ou rígido em tarefas informais.
- Aumento da latência: O modo "somente pensamento" aumenta ligeiramente a latência em cadeias altamente complexas.
- Variação criativa limitada: Variação mínima no tom criativo em comparação com os mestrados em direito orientados para a narrativa.
🚀 Novos recursos e atualizações técnicas 🚀
DeepSeek-V3.2-Speciale introduz estruturas de raciocínio pioneiras e camadas de otimização interna, projetadas para oferecer estabilidade, interpretabilidade e precisão superiores em contextos longos.
Principais melhorias
- 🧠 Modo somente para pensar: Adiciona uma passagem cognitiva silenciosa antes da saída visível ao usuário, reduzindo drasticamente as taxas de contradição e alucinações, para respostas mais confiáveis.
- 📏 Janela de contexto estendida (128 KB): Permite a síntese abrangente de documentos longos, a memorização sustentada de diálogos e o raciocínio baseado em dados provenientes de múltiplas fontes.
- 🔍 Auditoria interna da cadeia de suprimentos: Oferece maior visibilidade do processo de raciocínio, sendo algo inestimável para pesquisadores que validam inferências em várias etapas e garantem a transparência.
- ✏️ Preenchimento do meio (FIM): Facilita inserções em nível de contexto e correções de código estruturadas sem a necessidade de reenvio completo do prompt, aumentando a eficiência dos desenvolvedores.
Impacto prático
Essas melhorias significativas se traduzem em uma maior profundidade interpretativa em matemática, lógica científica e tarefas analíticas complexas. O DeepSeek V3.2 Speciale é, portanto, ideal para fluxos de trabalho de automação sofisticados e experimentos avançados de pesquisa cognitiva.
💰 Preços da API 💰
- Entrada: US$ 0,2977 por 1 milhão de tokens
- Saída: US$ 0,4538 por 1 milhão de tokens
💻 Exemplo de código 💻
# Exemplo de código Python para chamada da API DeepSeek V3.2 Speciale import openai client = openai.OpenAI( base_url="https://api.deepseek.com/v1", api_key="YOUR_API_KEY") response = client.chat.completions.create( model="deepseek/deepseek-v3.2-speciale", messages=[ {"role": "user", "content": "Explique o conceito de emaranhamento quântico de forma lógica e passo a passo."}, {"role": "assistant", "content": "(Modo somente pensamento ativado: Desconstruindo a consulta, identificando conceitos-chave, planejando a progressão lógica, relembrando princípios físicos relevantes, estruturando a explicação em etapas discretas.)"} ], # O modo 'somente pensamento' é um mecanismo interno. # A chamada da API em si permanece padrão, mas o processamento interno do modelo muda. temperature=0.7, max_tokens=500 ) imprimir(resposta.escolhas[0].mensagem.conteúdo) 🆚 Comparação com outros modelos 🆚
DeepSeek V3.2 Especial vs. Gemini-3.0-Pro: Os testes de desempenho indicam que o DeepSeek-V3.2-Speciale atinge um desempenho geral comparável ao do Gemini-3.0-Pro. No entanto, o DeepSeek dá uma ênfase significativamente maior ao raciocínio transparente e passo a passo, tornando-o particularmente vantajoso para aplicações de IA com agentes.
DeepSeek V3.2 Especial vs. GPT-5: As avaliações relatadas posicionam o DeepSeek-V3.2-Speciale à frente do GPT-5 em cargas de trabalho de raciocínio desafiadoras, especialmente em benchmarks com forte componente matemática e em competições. Ele também mantém alta competitividade em termos de codificação e confiabilidade no uso da ferramenta, oferecendo uma alternativa atraente para tarefas complexas.
DeepSeek V3.2 Especial vs. DeepSeek-R1: O Speciale foi projetado para cenários de raciocínio ainda mais extremos, apresentando uma janela de contexto de 128K e um "modo de pensamento" de alto poder computacional. Isso o torna excepcionalmente adequado para estruturas de agentes avançadas e experimentos de nível de benchmark, diferenciando-o do DeepSeek-R1, que foi projetado para uso interativo mais casual.
💬 Feedback da Comunidade 💬
Feedback do usuário em plataformas como Reddit O DeepSeek V3.2 Speciale é consistentemente destacado como uma solução excepcional para tarefas de raciocínio de alto risco. Os desenvolvedores elogiam particularmente seu domínio em benchmarks e sua impressionante relação custo-benefício, observando sua superioridade sobre o GPT-5 em benchmarks de matemática, código e lógica, frequentemente com uma eficiência de custos superior. Custo 15 vezes menorMuitos o descrevem como "notável" para fluxos de trabalho com agentes e resolução de problemas complexos. Os usuários também elogiam sua impressionante coerência em longas cadeias, a redução significativa de erros e a profundidade "semelhante à humana", especialmente quando comparada às versões anteriores do DeepSeek.
❓ Perguntas Frequentes (FAQ) ❓
P1: Qual é o foco principal do DeepSeek V3.2 Speciale?
A1: Concentra-se principalmente no raciocínio avançado e na resolução de problemas lógicos em várias etapas, sendo projetada para tarefas analíticas complexas nas áreas de código, matemática e ciências.
P2: Como funciona o modo "somente pensamento"?
A2: Este modo permite que o modelo execute um raciocínio interno silencioso antes de gerar qualquer saída visível. Essa passagem cognitiva interna melhora significativamente a precisão, a coerência factual e o fluxo lógico das respostas, especialmente para consultas complexas.
Q3: Qual é o comprimento máximo do contexto para o DeepSeek V3.2 Speciale?
A3: O DeepSeek V3.2 Speciale suporta uma janela de contexto estendida de até 128 mil tokens, permitindo lidar com documentos muito longos, manter uma memória de diálogo sustentada e realizar raciocínio baseado em dados em múltiplas fontes.
Q4: Como seu preço se compara ao de outros modelos?
A4: O feedback da comunidade sugere que o DeepSeek V3.2 Speciale oferece preços altamente competitivos, com desenvolvedores relatando que ele pode ser até 15 vezes mais barato do que alguns concorrentes, como o GPT-5, para tarefas complexas semelhantes.
Q5: O DeepSeek V3.2 Speciale é adequado para tarefas de escrita criativa?
A5: Embora altamente capaz em raciocínio analítico, suas "Limitações" incluem uma variação mínima no tom criativo em comparação com as linguagens de programação voltadas para a narrativa. Pode soar excessivamente formal ou rígida para tarefas informais ou altamente criativas.
Playground de IA

