 OpenAI - ChatGPT, Sora
OpenAI - ChatGPT, Sora Google - Gemini, Nano Banana
Google - Gemini, Nano Banana Antrópico - Claude
Antrópico - Claude xAI - Grok
xAI - Grok Busca profunda
Busca profunda Alibaba - Qwen
Alibaba - Qwen ByteDance - O Melhor da ByteDance
ByteDance - O Melhor da ByteDance Todos os modelos
Todos os modelos Planos Empresariais
Planos Empresariais Desenvolvimento de aplicações de IA
Desenvolvimento de aplicações de IA API de tradução de IA
API de tradução de IA Serviço de SEO/GEO com IA
Serviço de SEO/GEO com IA Serviço de Relações Públicas Otimizado por Geolocalização
Serviço de Relações Públicas Otimizado por Geolocalização Serviço de Web Scraping
Serviço de Web Scraping OpenClaw
OpenClaw Principais ferramentas de IA
Principais ferramentas de IA Os melhores robôs de IA
Os melhores robôs de IA
 Conecte-se
Conecte-se



const { OpenAI } = require('openai');
const api = new OpenAI({
baseURL: 'https://api.ai.cc/v1',
apiKey: '',
});
const main = async () => {
const result = await api.chat.completions.create({
model: 'x-ai/grok-4-1-fast-non-reasoning',
messages: [
{
role: 'system',
content: 'You are an AI assistant who knows everything.',
},
{
role: 'user',
content: 'Tell me, why is the sky blue?'
}
],
});
const message = result.choices[0].message.content;
console.log(`Assistant: ${message}`);
};
main();
import os
from openai import OpenAI
client = OpenAI(
base_url="https://api.ai.cc/v1",
api_key="",
)
response = client.chat.completions.create(
model="x-ai/grok-4-1-fast-non-reasoning",
messages=[
{
"role": "system",
"content": "You are an AI assistant who knows everything.",
},
{
"role": "user",
"content": "Tell me, why is the sky blue?"
},
],
)
message = response.choices[0].message.content
print(f"Assistant: {message}")


Detalhes do produto
🚀 Grok 4.1 Fast API: LLM ultrarrápido e não racional para fluxos de trabalho eficientes
O Grok 4.1 API rápida sem raciocínio O modelo xAI representa um salto significativo na tecnologia de modelos de linguagem de grande escala, projetado especificamente para velocidade incomparável e geração determinística de texto para texto. Este modelo se destaca em ambientes onde o raciocínio complexo não é o requisito principal, mas sim a obtenção de resultados ultrarrápidos e o processamento massivo de contexto. Seu design o torna uma solução ideal para fluxos de trabalho com alto volume de conteúdo, tarefas em lote rápidas e aplicações que exigem resultados consistentes com latência mínima.
🔧 Especificações Técnicas Principais
- Tipo de modelo: LLM avançado baseado em Transformer (Texto para Texto)
- Modo operacional: Sem raciocínio (fornece resultados diretos para maior velocidade)
- Latência: Inferência instantânea com latência extremamente baixa
- Protocolos de segurança: Utiliza testes adversários e avaliações multilíngues abrangentes para garantir um desempenho robusto em diversos idiomas, incluindo inglês, espanhol, chinês, japonês, árabe e russo.
📊 Destaques e indicadores de desempenho
Avaliado segundo métricas-chave, o Grok 4.1 Fast Non-Reasoning demonstra consistentemente precisão, segurança e eficiência operacional superiores. Ele supera seus antecessores, apresentando maior precisão (indicada por pontuações mais baixas) em testes com 500 questões biográficas aprimoradas com ferramentas de busca na web.
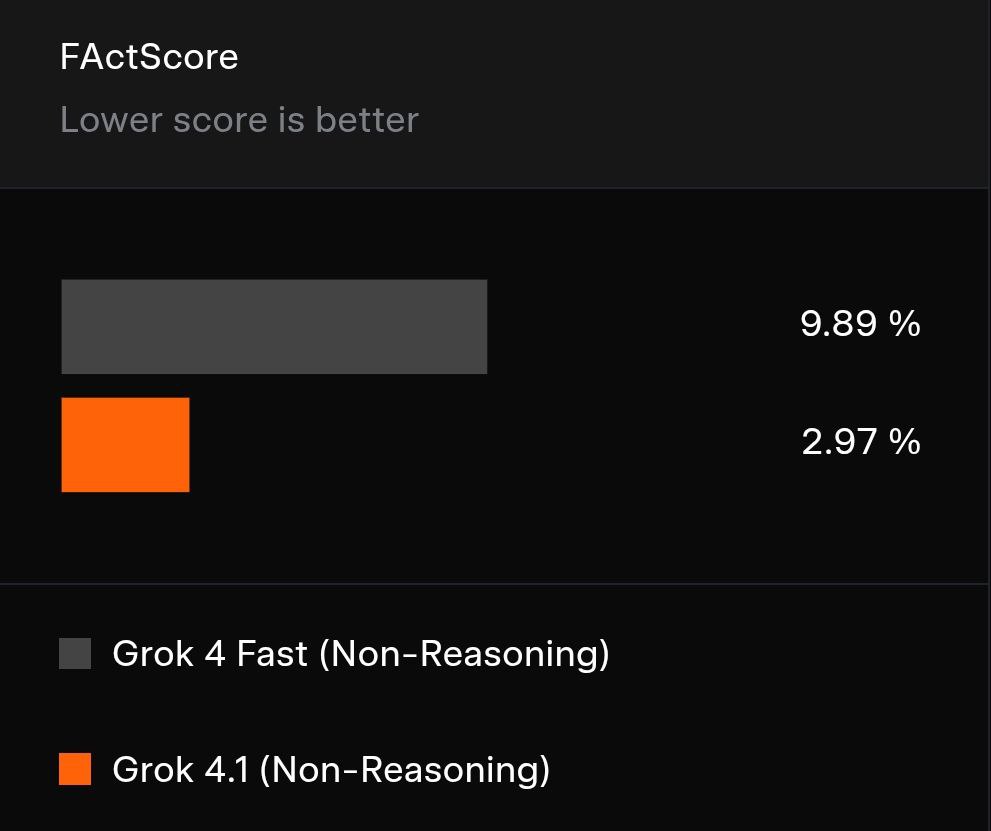
Representação visual das melhorias de desempenho, demonstrando maior precisão.
✅ Características distintivas
- 📜 Tratamento de contextos ultralongos: Processa documentos e conversas extremamente longas sem qualquer perda de coerência.
- 🔄 Resultados determinísticos: Garante respostas estáveis e previsíveis para comandos idênticos.
- 💭 Alta precisão factual: Ajustado para minimizar alucinações e garantir máxima precisão factual em perguntas simples.
- ⚠️ Otimizado para velocidade: Prioriza o processamento rápido e em massa, dispensando intencionalmente o uso de ferramentas ou recursos de raciocínio avançados.
- 🚨 Segurança avançada: Apresenta taxas extremamente baixas de recusa e fuga graças a mecanismos de segurança robustos.
💸 Estrutura de preços da API
- Tokens de entrada: US$ 0,21 por 1 milhão de tokens
- Tokens de saída: US$ 0,53 por 1 milhão de tokens
💡 Aplicações e casos de uso ideais
- 📝 Resumo de documentos longos: Resuma rapidamente artigos de pesquisa extensos, documentos legais ou relatórios.
- 💬 Processamento do histórico de conversas: Anote e processe com eficiência grandes volumes de registros de bate-papo e dados de conversas.
- 🔀 Transformação de texto em massa: Executar tarefas de reformatação, reformulação ou extração de dados de conteúdo em larga escala.
- 🎤 Transcrição e busca automatizadas de reuniões: Gere transcrições de áudio e possibilite buscas rápidas em vastos arquivos.
- 🤖 Chatbots de alto volume: Capacite chatbots de atendimento ao cliente para lidar com consultas simples e repetitivas de forma eficiente.
💻 Exemplo de código de API (Python)
import openai client = openai.OpenAI( base_url="https://api.xai.com/v1", api_key="YOUR_API_KEY", # Substitua pela sua chave de API real ) completion = client.chat.completions.create( model="x-ai/grok-4-1-fast-non-reasoning", messages=[ {"role": "system", "content": "Você é um assistente útil."}, {"role": "user", "content": "Resuma os principais recursos do Grok 4.1 Fast em menos de 50 palavras."} ], max_tokens=100 ) print(completion.choices[0].message.content) 🔍 Grok 4.1 Rápido: Uma Visão Geral Comparativa
A compreensão dos pontos fortes exclusivos do Grok 4.1 Fast Non-Reasoning fica mais clara quando comparada a outros modelos de linguagem líderes de mercado:
vs. Grok 4.1 Raciocínio: O Grok 4.1 Fast prioriza velocidade extrema e respostas determinísticas, enquanto a variante "Reasoning" foi projetada para lógica de múltiplas etapas e maior profundidade analítica. Para obter informações mais detalhadas, consulte o Documentação oficial do produto Grok 4.1.
vs. DeepSeek V3.1: O Grok 4.1 Fast oferece uma capacidade significativamente maior. Janela de contexto de 2 milhões de tokens, uma enorme vantagem sobre os 128 mil tokens do DeepSeek V3.1, tornando-o superior para o processamento extensivo de documentos.
vs. Claude 4: O Grok 4.1 Fast oferece uma janela de contexto substancialmente maior, processando até 2 milhões de tokens, enquanto Claude 4 normalmente opera em um contexto de 100 mil a 200 mil tokens.
vs. GPT-4o: O GPT-4o é um modelo versátil de propósito geral que se destaca em raciocínio robusto, criatividade e resolução de problemas avançados. O Grok 4.1 Fast, por outro lado, limita intencionalmente a complexidade para oferecer velocidade incomparável e resultados determinísticos, tornando-o a escolha ideal para tarefas de alto rendimento que não exigem raciocínio, onde os recursos avançados do GPT-4o não são necessários.
❓ Perguntas frequentes (FAQ)
O que é o Grok 4.1 Fast Non-Reasoning?
Grok 4.1 Fast Non-Reasoning é um modelo de linguagem abrangente da xAI, otimizado para geração de texto determinística ultrarrápida e processamento extensivo de contexto. Ele foi projetado para tarefas em que velocidade e alto rendimento são priorizados em detrimento do raciocínio interno complexo.
Qual é a janela de contexto máxima suportada pelo Grok 4.1 Fast?
O Grok 4.1 Fast Non-Reasoning suporta uma impressionante janela de contexto de até 2 milhões de tokens, permitindo processar e compreender documentos e conversas extremamente longos sem perder a coerência.
Como o Grok 4.1 Fast garante segurança e precisão?
Ele integra mecanismos de segurança robustos, incluindo testes adversários e avaliações multilíngues. Isso garante alta precisão factual em consultas simples e mantém taxas extremamente baixas de recusa e de desbloqueio.
Que tipos de aplicações se beneficiam mais com o Grok 4.1 Fast?
É ideal para tarefas como resumir documentos longos, processar extensos históricos de bate-papo, transformação de texto em massa, transcrição automatizada de reuniões e para alimentar chatbots de interação com o cliente simples e de alto volume.
Qual é o preço da API do Grok 4.1 Fast?
A API tem o preço de US$ 0,21 por 1 milhão de tokens de entrada e US$ 0,53 por 1 milhão de tokens de saída, oferecendo uma solução econômica para necessidades de geração de texto em larga escala.
Playground de IA

