 OpenAI - ChatGPT, Sora
OpenAI - ChatGPT, Sora Google - Gemini, Nano Banana
Google - Gemini, Nano Banana Antrópico - Claude
Antrópico - Claude xAI - Grok
xAI - Grok Busca profunda
Busca profunda Alibaba - Qwen
Alibaba - Qwen ByteDance - O Melhor da ByteDance
ByteDance - O Melhor da ByteDance Todos os modelos
Todos os modelos Planos Empresariais
Planos Empresariais Desenvolvimento de aplicações de IA
Desenvolvimento de aplicações de IA API de tradução de IA
API de tradução de IA Serviço de SEO/GEO com IA
Serviço de SEO/GEO com IA Serviço de Relações Públicas Otimizado por Geolocalização
Serviço de Relações Públicas Otimizado por Geolocalização Serviço de Web Scraping
Serviço de Web Scraping OpenClaw
OpenClaw Principais ferramentas de IA
Principais ferramentas de IA Os melhores robôs de IA
Os melhores robôs de IA
 Conecte-se
Conecte-se



const axios = require('axios').default;
const api = axios.create({
baseURL: 'https://api.ai.cc/v1',
headers: { Authorization: 'Bearer ' },
});
const main = async () => {
const response = await api.post('/tts', {
model: 'inworld/tts-1-max',
text: 'OpenAI TTS are fast and powerful language models. Use it to convert text to natural sounding spoken text.',
voice: 'coral',
});
console.log('Audio URL:', response.data.audio.url);
console.log('Characters:', response.data.usage.characters);
};
main();
import requests
def main():
url = "https://api.ai.cc/v1/tts"
headers = {
"Authorization": "Bearer ",
}
payload = {
"model": "inworld/tts-1-max",
"text": "OpenAI TTS are fast and powerful language models. Use it to convert text to natural sounding spoken text.",
"voice": "coral"
}
response = requests.post(url, headers=headers, json=payload)
data = response.json()
print("Audio URL:", data["audio"]["url"])
print("Characters:", data["usage"]["characters"])
main()


Detalhes do produto
Inworld TTS-1-Max: Revolucionando a tecnologia de conversão de texto em fala.
Descubra o API Inworld TTS-1-Max, um modelo de síntese de voz autorregressivo de última geração baseado em Transformers. Projetado para oferecer qualidade de fala e expressividade incomparáveis, ele se destaca como a principal escolha para aplicações profissionais e comerciais que exigem síntese de voz de alta resolução e nuances.
Com um impressionante 8,8 bilhões de parâmetrosO TTS-1-Max amplia os limites da geração de linguagem natural, produzindo vozes praticamente indistinguíveis da fala humana.
Especificações técnicas e desempenho
- ⚙️ Arquitetura: Modelo autorregressivo avançado baseado em Transformer
- 🔢 Parâmetros: Um enorme 8,8 bilhões (o maior da família Inworld TTS-1)
- 🔊 Saída de áudio: Imagem nítida e de alta resolução. 48 kHz discurso
- 🌐 Idiomas suportados: Suporte abrangente para 11 línguas principais
- ⚡ Velocidade de inferência: Atinge aproximadamente 8.000 tokens/seg por GPU em uma configuração com 32 H100, garantindo eficiência.
Liderando os Rankings de Qualidade
O modelo TTS-1-Max é consistentemente classificado como um melhor desempenho em rankings independentes de qualidade, demonstrando sua produção superior e naturalidade em diversas avaliações.
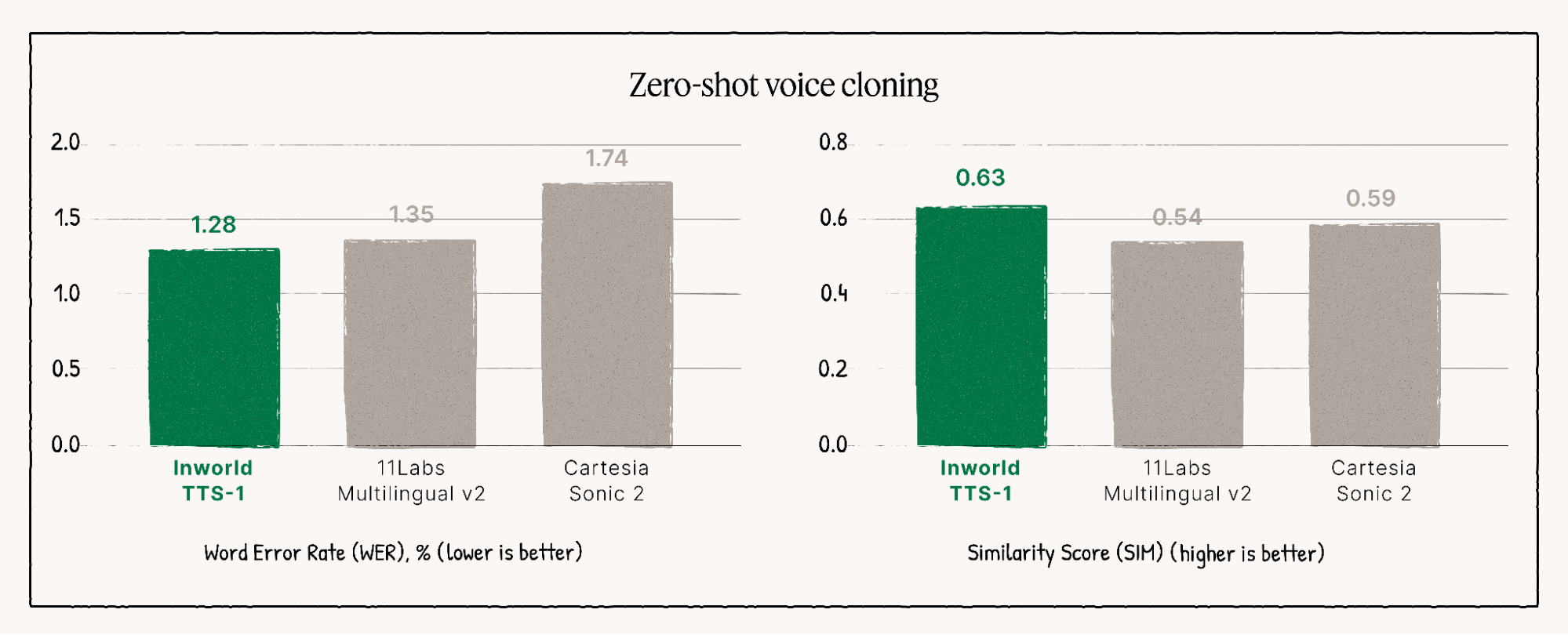
Principais características para uma síntese de voz incomparável
- ✨ Naturalidade e expressividade superiores: Aproveita a parametrização em larga escala para produzir resultados de voz incrivelmente naturais e emocionalmente ricos.
- 🗣️ Síntese multilíngue de alta fidelidade: Gere discursos com clareza e precisão excepcionais em todas as plataformas. 11 línguas diferentesIdeal para aplicações globais.
- 🎭 Modulação Emocional Avançada: Aprimore seu estilo de fala com recursos robustos de modulação emocional, adicionando nuances e profundidade a cada expressão.
- 👂 Sons e vocalizações não verbais realistas: Aprimora o realismo da fala com suporte integrado para diversas pistas não verbais, tornando as vozes de IA mais naturais.
- 👤 Clonagem de voz pura e contextualizada: Realiza a clonagem de voz sem a necessidade de dados pré-gravados do locutor, baseando-se exclusivamente em um sofisticado aprendizado contextual.
Preços de API transparentes e competitivos
💰 Experimente a síntese de voz premium com preços simples e transparentes:
- Custo: Apenas $ 10,5 por 1 milhão de caracteres gerados.
- Custo estimado por minuto: Aproximadamente $ 0,0105 por minuto de fala gerada de alta qualidade.
Integre com facilidade: Exemplo de código
A implementação do Inworld TTS-1-Max em seus aplicativos é simples. Abaixo, você encontra um trecho da API para facilitar a integração:
https://docs.ai.cc/api-references/speech-models/text-to-speech/inworld/tts-1-max " snippet data-name="voice.tts-openai" data-model="inworld/tts-1-max"> Para obter detalhes completos sobre a integração, parâmetros avançados e mais exemplos de código, consulte o Documentação oficial da API Inworld TTS-1-Max.
Inworld TTS-1-Max: Vantagem Competitiva
Entenda como o Inworld TTS-1-Max se diferencia de outros modelos líderes de conversão de texto em fala no mercado, oferecendo vantagens específicas para diversos casos de uso.
🆚 vs. Inworld TTS-1
O TTS-1-Max oferece expressividade e naturalidade superiores Graças à sua escala de parâmetros significativamente maior, de 8,8 bilhões (em comparação com os 1,6 bilhão do TTS-1), ele se torna ideal para conteúdo premium, como audiolivros. Em contraste, o TTS-1 prioriza velocidade em tempo real (~153 caracteres/segundo contra ~69 caracteres/segundo do TTS-1-Max), tornando-o mais adequado para aplicações altamente interativas.
🆚 vs. ElevenLabs Multilingual V2
Nos testes de qualidade, o TTS-1-Max alcança um Taxa de vitórias em confrontos diretos de 59,1%., oferecendo maior granularidade emocional e suporte robusto para sons não verbais por meio de marcações. Embora a ElevenLabs ofereça clonagem multilíngue robusta, a TTS-1-Max se destaca em resolução de áudio bruta e a pureza de sua abordagem de aprendizado contextualizado.
🆚 vs. MiniMax-Speech
TTS-1-Max prioriza qualidade vocal máxima e fidelidade em seus 11 idiomas suportados, demonstrando liderança em naturalidade comprovada e controle de prosódia emocional. O MiniMax-Speech, por outro lado, enfatiza recursos mais amplos de clonagem sem captura de voz em 32 idiomas e replicação rápida de voz em uma única captura.
Perguntas frequentes (FAQ)
❓ O que é o Inworld TTS-1-Max?
O Inworld TTS-1-Max é uma API de conversão de texto em fala autorregressiva de última geração, baseada em Transformers, com 8,8 bilhões de parâmetros. Ela foi projetada para aplicações profissionais e comerciais que exigem qualidade de fala e expressividade superiores.
❓ Quais são suas principais características técnicas?
Oferece uma arquitetura Transformer autorregressiva, 8,8 bilhões de parâmetros, áudio de alta resolução de 48 kHz, suporte para 11 idiomas principais e uma velocidade de inferência de aproximadamente 8.000 tokens/seg por GPU.
❓ Como o TTS-1-Max consegue atingir alta expressividade?
Sua expressividade e naturalidade excepcionais derivam de sua parametrização em larga escala, com 8,8 bilhões de parâmetros, aliada a recursos de modulação emocional e suporte para sons não verbais, criando uma fala altamente matizada.
❓ Qual é a estrutura de preços da API TTS-1-Max?
A API tem o preço de US$ 10,5 por 1 milhão de caracteres, o que se traduz em um custo estimado de cerca de US$ 0,0105 por minuto de fala gerada.
❓ Quais são os casos de uso ideais para o Inworld TTS-1-Max?
É perfeitamente adequado para locuções profissionais, dublagem, IA conversacional avançada, produção de conteúdo multimídia multilíngue, aplicativos de voz interativos, audiolivros, jogos e ambientes virtuais imersivos onde a qualidade e a expressividade de voz superiores são fundamentais.
Playground de IA

