 OpenAI - ChatGPT, Sora
OpenAI - ChatGPT, Sora Google - Gemini, Nano Banana
Google - Gemini, Nano Banana Antrópico - Claude
Antrópico - Claude xAI - Grok
xAI - Grok Busca profunda
Busca profunda Alibaba - Qwen
Alibaba - Qwen ByteDance - O Melhor da ByteDance
ByteDance - O Melhor da ByteDance Todos os modelos
Todos os modelos Planos Empresariais
Planos Empresariais Desenvolvimento de aplicações de IA
Desenvolvimento de aplicações de IA API de tradução de IA
API de tradução de IA Serviço de SEO/GEO com IA
Serviço de SEO/GEO com IA Serviço de Relações Públicas Otimizado por Geolocalização
Serviço de Relações Públicas Otimizado por Geolocalização Serviço de Web Scraping
Serviço de Web Scraping OpenClaw
OpenClaw Principais ferramentas de IA
Principais ferramentas de IA Os melhores robôs de IA
Os melhores robôs de IA
 Conecte-se
Conecte-se



const { OpenAI } = require('openai');
const api = new OpenAI({
baseURL: 'https://api.ai.cc/v1',
apiKey: '',
});
const main = async () => {
const result = await api.chat.completions.create({
model: 'alibaba/qwen3-next-80b-a3b-instruct',
messages: [
{
role: 'system',
content: 'You are an AI assistant who knows everything.',
},
{
role: 'user',
content: 'Tell me, why is the sky blue?'
}
],
});
const message = result.choices[0].message.content;
console.log(`Assistant: ${message}`);
};
main();
import os
from openai import OpenAI
client = OpenAI(
base_url="https://api.ai.cc/v1",
api_key="",
)
response = client.chat.completions.create(
model="alibaba/qwen3-next-80b-a3b-instruct",
messages=[
{
"role": "system",
"content": "You are an AI assistant who knows everything.",
},
{
"role": "user",
"content": "Tell me, why is the sky blue?"
},
],
)
message = response.choices[0].message.content
print(f"Assistant: {message}")

-p-130x130q80-p-130x130q80.png)
Detalhes do produto
Qwen3-Next-80B-A3B Instruir É um modelo de linguagem de grande porte, altamente avançado e otimizado para instruções, projetado para oferecer velocidade, estabilidade e capacidade de lidar com contextos extremamente longos com alto rendimento. Ele alcança melhorias significativas em velocidade e custo-benefício ativando apenas uma pequena parte de seus 80 bilhões de parâmetros, sem comprometer o desempenho em áreas críticas como raciocínio complexo e geração de código.
⚙️ Especificações técnicas
O Qwen3-Next-80B-A3B Instruct otimiza suas operações por meio de Ativando apenas cerca de 3 bilhões de parâmetros de um total de 80 bilhões durante a inferência.Esse mecanismo de ativação esparsa oferece vantagens substanciais:
- Rapidez e custo-benefício: Opera aproximadamente 10 vezes mais rápido e com melhor relação custo-benefício em comparação com o modelo anterior Qwen3-32B.
- Capacidade de processamento: Oferece um aumento de desempenho mais de 10 vezes superior no processamento de contextos longos com 32 mil tokens ou mais.
- Implantação flexível: Oferece opções de implantação versáteis, incluindo hospedagem sem servidor, dedicada sob demanda e com reserva mensal.
- Compatibilidade de implantação: Compatível com SGLang e vLLM para uso eficiente e escalável, apresentando recursos avançados de previsão de múltiplos tokens.
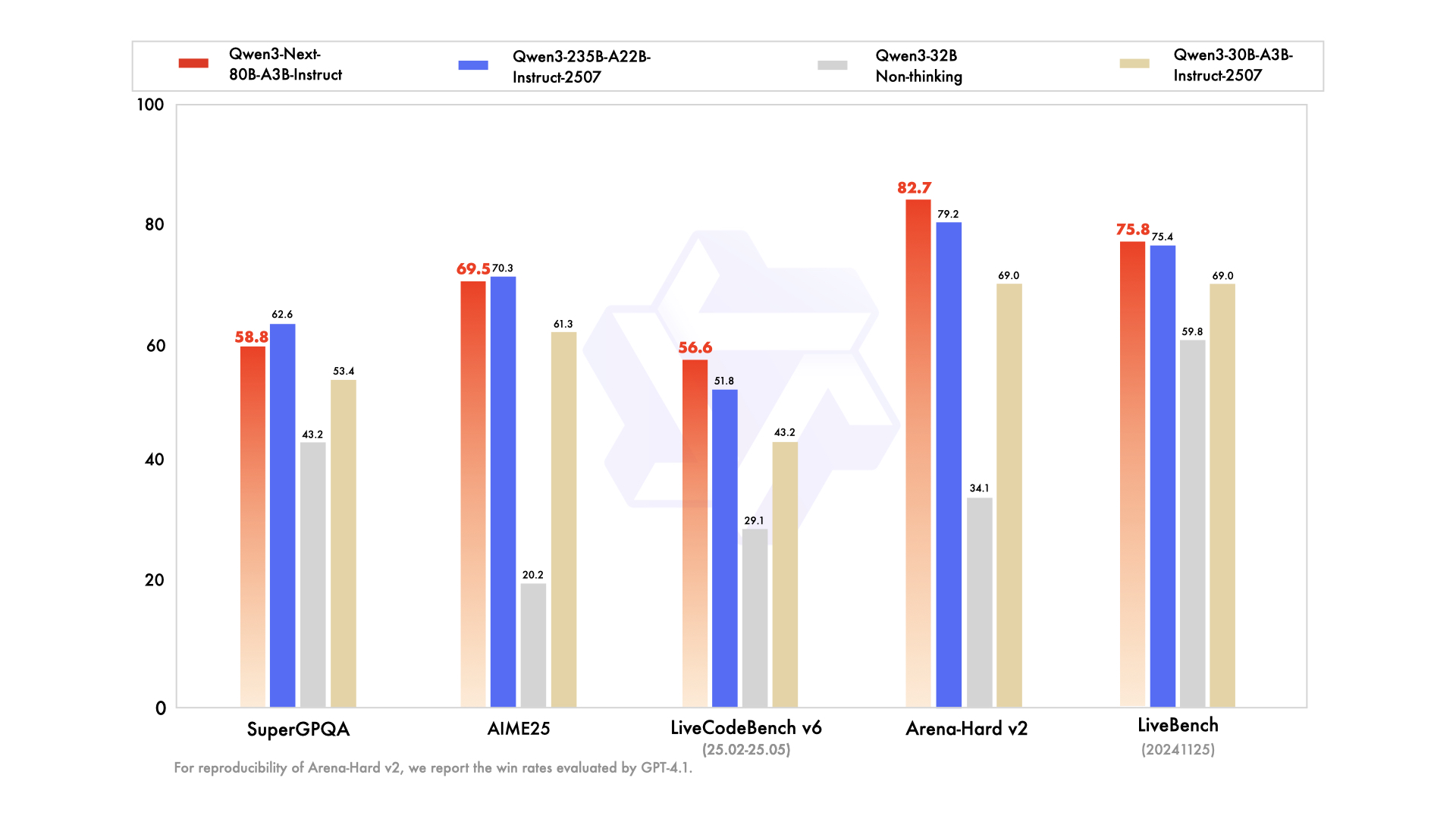
📊 Indicadores de desempenho
- ✅ Desempenho de primeira linha: Apresenta desempenho igual ou muito próximo ao do modelo principal Qwen3-235B em diversas tarefas de raciocínio, conclusão de código e seguimento de instruções.
- ✅ Manipulação consistente de contextos longos: Fornece respostas estáveis e determinísticas de forma consistente, destacando-se particularmente em tarefas que exigem ampla compreensão do contexto.
- ✅ Eficiente em termos de recursos: Supera em eficiência os modelos anteriores de tamanho médio otimizados para instruções, alcançando alto desempenho com menos recursos computacionais.
- ✅ Integração versátil: Altamente adequado para integração de ferramentas, Geração Aumentada por Recuperação (RAG) e fluxos de trabalho sofisticados que exigem resultados consistentes em termos de cadeia de raciocínio.
💰 Preços da API
Entrada: $ 0,1575
Saída: $ 1,6
✨ Principais capacidades
- 🚀 Inferência ultraeficiente: Utiliza uma arquitetura esparsa de Mistura de Especialistas (MoE), ativando dinamicamente apenas 3 bilhões de parâmetros de um total de 80 bilhões, para uma inferência significativamente mais rápida e com melhor custo-benefício.
- 🧠 Desempenho excepcional em tarefas: Destaca-se em uma ampla gama de tarefas complexas, incluindo raciocínio avançado, geração de código robusto, resposta precisa a perguntas de conhecimento e aplicações multilíngues versáteis.
- ⚡️ Respostas estáveis e rápidas: Otimizado para o modo de instrução, garantindo respostas rápidas e consistentes sem etapas intermediárias de "pensamento".
- 📖 Manipulação de Contextos Ultralongos: Apresenta um comprimento de contexto nativo de 262 mil tokens, expansível até impressionantes 1 milhão de tokens usando tecnologia avançada de escalonamento.
- 📈 Alto Rendimento: Obtém uma melhoria de 10 vezes na capacidade de processamento de contextos longos e extensos em comparação com os modelos anteriores.
- 💬 Diálogo e respostas consistentes: Ideal para diálogos com múltiplas interações e tarefas que exigem respostas finais determinísticas e consistentes.
- 🛠️ Fluxos de trabalho avançados com agentes: Recursos robustos para chamada de ferramentas, execução de tarefas em várias etapas e fluxos de trabalho sofisticados baseados em agentes, com ferramentas perfeitamente integradas.
💡 Casos de uso
- Geração de código: Acelere o desenvolvimento de software por meio de sugestões de código inteligentes e geração de blocos de código completos.
- Criação e edição de conteúdo: Gere conteúdo diversificado, desde artigos a textos de marketing, e realize edições complexas com base em instruções detalhadas.
- Análise de dados: Facilita a interpretação de dados complexos, a análise estatística e a geração de relatórios abrangentes.
- Automação do atendimento ao cliente: Aumente a eficiência do suporte ao cliente com o processamento preciso de instruções e respostas automatizadas.
- Documentação técnica: Simplifique a criação de documentos técnicos, manuais e formatos de saída específicos.
- Automação de processos: Execute tarefas com várias etapas e integre chamadas de ferramentas para automatizar e otimizar diversos fluxos de trabalho.
- Conversas longas e manuseio de documentos: Gerencie diálogos extensos com eficiência, resuma documentos grandes e extraia informações importantes de textos longos.
💻 Exemplo de código
import openai client = openai.OpenAI( base_url="https://api.perplexity.ai", # URL base de exemplo, substitua pelo endpoint real api_key="YOUR_API_KEY", # Substitua pela sua chave de API real ) messages = [ { "role": "system", "content": "Você é Qwen3-Next-80B-A3B Instruct, um assistente de IA prestativo." }, { "role": "user", "content": "Explique o conceito de emaranhamento quântico em termos simples para um aluno do ensino médio." }, ] response = client.chat.completions.create( model="alibaba/qwen3-next-80b-a3b-instruct", messages=messages, max_tokens=500, temperature=0.7, top_p=0.9, frequency_penalty=0, presence_penalty=0, ) print(response.choices[0].message.content) Observação: Os campos `base_url` e `api_key` no exemplo acima são apenas marcadores. Consulte a documentação oficial da API para obter detalhes específicos sobre a integração.
🆚 Comparação com outros modelos
O modelo 80B A3B oferece desempenho igual ou muito próximo ao do modelo topo de linha 235B em tarefas de raciocínio e codificação, sendo significativamente mais eficiente ao ativar menos parâmetros para inferências mais rápidas e econômicas.
O Qwen3-Next oferece capacidades comparáveis de seguimento de instruções e de contexto longo, distinguindo-se por uma vantagem em termos de rendimento e um tamanho de janela de token maior, tornando-o particularmente adequado para tarefas extensas de compreensão de documentos.
O Qwen3-Next demonstra desempenho superior em diálogos com múltiplas interações e fluxos de trabalho com agentes, fornecendo resultados mais determinísticos em contextos muito longos em comparação com os pontos fortes conversacionais do Claude.
O Qwen3-Next demonstra melhor escalabilidade no tratamento de contextos ultralongos e eficiência superior na previsão de múltiplos tokens, o que lhe confere uma clara vantagem no processamento de tarefas complexas de raciocínio em várias etapas.
❓ Perguntas frequentes
P1: O que torna o Qwen3-Next-80B-A3B Instruct excepcionalmente eficiente?
O modelo utiliza uma arquitetura esparsa de Mistura de Especialistas (MoE), ativando apenas cerca de 3 bilhões dos seus 80 bilhões de parâmetros durante a inferência. Essa abordagem inovadora resulta em um processamento significativamente mais rápido e custos operacionais mais baixos, alcançando uma eficiência até 10 vezes maior do que os modelos anteriores.
Q2: Como ele se comporta em contextos ultralongos?
O Qwen3-Next-80B-A3B Instruct suporta um comprimento de contexto nativo de 262 mil tokens e, com tecnologia avançada de escalonamento, esse valor pode ser expandido para impressionantes 1 milhão de tokens. Essa capacidade o torna ideal para tarefas que exigem compreensão profunda de documentos extensos e longas conversas.
P3: Como seu desempenho se compara ao de outros modelos de linguagem líderes de mercado?
Apesar de ser altamente eficiente, o Qwen3-Next-80B-A3B Instruct iguala ou se aproxima do desempenho de modelos de ponta como o Qwen3-235B em tarefas complexas de raciocínio e geração de código. Ele também oferece capacidades comparáveis ou superiores em termos de taxa de transferência, processamento de contextos longos e saídas determinísticas quando comparado a modelos como GPT-4.1, Claude 4.1 Opus e Gemini 2.5 Flash.
Q4: Quais são os principais casos de uso para o Qwen3-Next-80B-A3B Instruct?
Este modelo é excepcionalmente adequado para aplicações que exigem alto rendimento, seguimento preciso de instruções e processamento de contexto abrangente. Os principais casos de uso incluem geração de código avançada, criação de conteúdo sofisticado, análise de dados detalhada, atendimento automatizado ao cliente, documentação técnica e fluxos de trabalho complexos com agentes.
Q5: O Qwen3-Next-80B-A3B Instruct é compatível com as infraestruturas de implantação existentes?
Sim, o modelo foi projetado para integração perfeita com ferramentas de implantação existentes, como SGLang e vLLM, oferecendo suporte a recursos avançados de previsão de múltiplos tokens. Ele também fornece opções de implantação flexíveis, incluindo arquitetura sem servidor, servidores dedicados sob demanda e hospedagem com reserva mensal, para atender a diversas necessidades operacionais.
Playground de IA

