 OpenAI - ChatGPT, Sora
OpenAI - ChatGPT, Sora Google - Gemini, Nano Banana
Google - Gemini, Nano Banana Antrópico - Claude
Antrópico - Claude xAI - Grok
xAI - Grok Busca profunda
Busca profunda Alibaba - Qwen
Alibaba - Qwen ByteDance - O Melhor da ByteDance
ByteDance - O Melhor da ByteDance Todos os modelos
Todos os modelos Planos Empresariais
Planos Empresariais Desenvolvimento de aplicações de IA
Desenvolvimento de aplicações de IA API de tradução de IA
API de tradução de IA Serviço de SEO/GEO com IA
Serviço de SEO/GEO com IA Serviço de Relações Públicas Otimizado por Geolocalização
Serviço de Relações Públicas Otimizado por Geolocalização Serviço de Web Scraping
Serviço de Web Scraping OpenClaw
OpenClaw Principais ferramentas de IA
Principais ferramentas de IA Os melhores robôs de IA
Os melhores robôs de IA
 Conecte-se
Conecte-se



const { OpenAI } = require('openai');
const api = new OpenAI({
baseURL: 'https://api.ai.cc/v1',
apiKey: '',
});
const main = async () => {
const result = await api.chat.completions.create({
model: 'alibaba/qwen3-vl-32b-instruct',
messages: [
{
role: 'system',
content: 'You are an AI assistant who knows everything.',
},
{
role: 'user',
content: 'Tell me, why is the sky blue?'
}
],
});
const message = result.choices[0].message.content;
console.log(`Assistant: ${message}`);
};
main();
import os
from openai import OpenAI
client = OpenAI(
base_url="https://api.ai.cc/v1",
api_key="",
)
response = client.chat.completions.create(
model="alibaba/qwen3-vl-32b-instruct",
messages=[
{
"role": "system",
"content": "You are an AI assistant who knows everything.",
},
{
"role": "user",
"content": "Tell me, why is the sky blue?"
},
],
)
message = response.choices[0].message.content
print(f"Assistant: {message}")


Detalhes do produto
✨ Descubra o Qwen3 VL 32B Instruct: Sua IA avançada de visão e linguagem
O Qwen3 VL 32B Instruções É um modelo de visão-linguagem de última geração (VL) projetado especificamente para seguir instruções com precisão em um amplo espectro de tarefas visuais. Ele se destaca por sua capacidade de interpretar entradas visuais complexas e gerar saídas textuais altamente coerentes e contextualizadas. Este modelo é meticulosamente otimizado para se sobressair na descrição de imagens, diálogos visuais envolventes e geração de conteúdo versátil, tornando-o uma ferramenta poderosa para aplicações de IA multimodal.
Conforme detalhado em seu Visão geral oficial do Qwen3 VL 32BA Qwen3 VL 32B Instruct é uma versão "somente para processamento não cognitivo", o que significa que foi otimizada para a execução direta e eficiente de tarefas visuais, em vez de raciocínio geral mais amplo, garantindo desempenho superior em seu domínio especializado.
⚙️ Especificações técnicas em resumo
- Tipo de modelo: Modelo de grande escala de visão-linguagem (VL)
- Contagem de parâmetros: 32 bilhões de parâmetros
- Arquitetura: Arquitetura multimodal baseada em Transformers, integrando um codificador visual robusto com um decodificador de texto sofisticado.
- Modalidades de entrada: Permite a integração perfeita de instruções/sugestões com imagens e texto.
- Modalidades de saída: Especializada em geração de texto de alta qualidade (descrições, diálogos, conteúdo criativo).
- Dados de treinamento: Treinado em um vasto conjunto de dados multimodais de grande escala, composto por imagens meticulosamente anotadas, combinadas com textos descritivos e conversacionais ricos.
- Capacidades de inferência: Oferece instruções precisas para tiros zerados e poucos tiros, eliminando a necessidade de extenso treinamento adicional.
🚀 Desempenho e padrões de referência inigualáveis
- 🎯 Conquistas precisão de última geração em conjuntos de dados de descrição visual líderes, rigorosamente comparados com as tarefas COCO Caption e VQA.
- 📈 Demonstra habilidades superiores de seguir instruções, validado por meio de avaliações humanas quanto à relevância e coerência excepcionais.
- 💡 Supera as versões anteriores do Qwen VL. na geração de conteúdo multimodal, na qualidade e no alinhamento preciso das instruções.
- 🔒 Exposições desempenho robusto de zero disparos em tarefas complexas de diálogo visual, quando comparadas a modelos de referência.
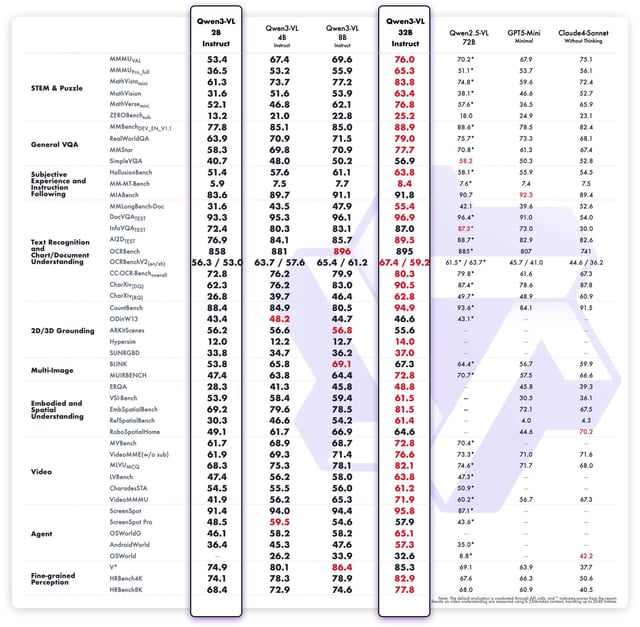
🌟 Principais Características e Vantagens
- ✨ Descrições precisas das imagens: Otimizado para gerar descrições de imagens excepcionalmente claras e precisas com base nas instruções do usuário.
- 💬 Diálogos visuais envolventes: Capaz de compreender contextos visuais complexos e participar de diálogos visuais dinâmicos.
- 🎨 Geração de conteúdo criativo: Produz conteúdo visual altamente relevante e inovador diretamente a partir de instruções textuais.
- ✔️ Alto alinhamento de instruções: Minimiza conteúdo irrelevante ou alucinatório, garantindo forte alinhamento com as instruções do usuário.
- 🖼️ Processamento eficiente de alta resolução: Processa imagens grandes e de alta resolução de forma eficiente, com uma compreensão visual refinada.
- 🌍 Saída multilíngue: Suporta saída de texto multilíngue, demonstrando forte fluência em diversos idiomas.
- 🔌 Integração fácil: Projetado para integração direta em fluxos de trabalho de criação de conteúdo baseados em IA e assistentes visuais interativos.
💰 Preços da API Qwen3 VL 32B
- ➡️ Entrada: US$ 0,735 / 1 milhão de tokens
- ⬅️ Saída: US$ 2,94 / 1 milhão de tokens
💡 Casos de uso versáteis
- 📸 Legendas automáticas para imagens: Ideal para sistemas de gerenciamento de ativos digitais, fornecendo descrições instantâneas e precisas.
- 🗣️ Controle de qualidade visual e suporte ao cliente: Aprimora os chatbots de atendimento ao cliente com recursos interativos de resposta a perguntas visuais.
- ✍️ Marketing e Criação de Conteúdo: Gera conteúdo para campanhas de marketing, mídias sociais e narrativas criativas usando imagens.
- 🚶♀️ Assistência para deficientes visuais: Descreve cenas visuais com riqueza de detalhes, oferecendo um suporte inestimável.
- 🔍 Busca multimídia aprimorada: Aprimora as capacidades dos mecanismos de busca por meio da compreensão avançada do contexto baseado em imagens.
- 📚 Aplicações educacionais: Oferece suporte a explicações visuais e tutoriais interativos, tornando o aprendizado mais envolvente.
💻 Exemplo de código para integração
Abaixo, segue um trecho de código típico que demonstra como interagir com a API de instruções do Qwen3 VL 32B.
import openai client = openai.OpenAI( api_key="YOUR_API_KEY", # Substitua pela sua chave de API real base_url="https://api.your-provider.com/v1" # Substitua pelo endpoint da sua API ) response = client.chat.completions.create( model="alibaba/qwen3-vl-32b-instruct", messages=[ {"role": "system", "content": "Você é um assistente útil que pode descrever imagens."}, {"role": "user", "content": [ {"type": "text", "text": "O que há nesta imagem?"}, {"type": "image_url", "image_url": {"url": "https://example.com/image.jpg"}} ]} ], max_tokens=500 ) print(response.choices[0].message.content) 🆚 Qwen3 VL 32B Instruct vs. Outros Modelos Líderes
vs. Qwen3 VL 32B Base:
O Versão de instruções é meticulosamente ajustado para uma melhor adesão às instruções, resultando em descrições mais relevantes ao contexto e mais precisas. Em contraste, o modelo Base visa principalmente a compreensão multimodal geral.
vs. OpenAI GPT-4 (com visão):
O Qwen3 VL 32B Instruct foi desenvolvido e otimizado especificamente para seguir instruções especializadas e gerar conteúdo visual, demonstrando menos alucinações em relação a estímulos visuais. Embora o GPT-4 ofereça capacidades gerais de IA mais amplas, ele pode ser menos especializado na adesão direta a instruções visuais.
vs. Claude 4.5 Visual:
O Qwen3 VL 32B Instruct oferece descrições de imagem e qualidade de diálogo superiores, com ênfase em instruções visuais. O Claude, embora excelente em raciocínio baseado em texto e gerenciamento de contextos mais amplos, geralmente oferece um pouco menos de especialização visual.
vs. DeepSeek V3.1:
O Qwen3 VL 32B Instruct se destaca na geração de conteúdo detalhado e em tarefas de visualização sofisticadas. O DeepSeek, por outro lado, é mais voltado para funcionalidades de busca e recuperação semântica de imagens.
❓ Perguntas frequentes (FAQ)
P: Para que serve principalmente o Qwen3 VL 32B Instruct?
A: É um modelo especializado de visão e linguagem otimizado para seguir instruções em tarefas como descrição precisa de imagens, diálogo visual envolvente e geração inteligente de conteúdo com base em entradas visuais e sugestões textuais.
P: Como o Qwen3 VL 32B Instruct se compara à sua versão Base?
A: A versão Instruct foi especificamente otimizada para uma melhor adesão às instruções, resultando em descrições mais precisas e relevantes ao contexto, ao contrário do modelo Base, que oferece uma compreensão multimodal geral.
P: Quais são as principais vantagens de usar o Qwen3 VL 32B Instruct?
A: As principais vantagens incluem descrição precisa de imagens, recursos robustos de diálogo visual, geração de conteúdo criativo com alto alinhamento de instruções, processamento eficiente de imagens de alta resolução e saída de texto multilíngue.
P: O Qwen3 VL 32B Instruct pode ser usado em aplicações do mundo real?
A: Com certeza. É ideal para legendagem automática de imagens, perguntas e respostas visuais no atendimento ao cliente, criação de conteúdo com inteligência artificial, auxílio a usuários com deficiência visual, aprimoramento de buscas multimídia e ferramentas educacionais interativas.
P: Qual é a estrutura de preços da API Qwen3 VL 32B?
A: O preço é escalonado: a entrada custa US$ 0,735 por 1 milhão de tokens e a saída custa US$ 2,94 por 1 milhão de tokens.
Playground de IA

