 OpenAI - ChatGPT, Sora
OpenAI - ChatGPT, Sora Google - Gemini, Nano Banana
Google - Gemini, Nano Banana Antrópico - Claude
Antrópico - Claude xAI - Grok
xAI - Grok Busca profunda
Busca profunda Alibaba - Qwen
Alibaba - Qwen ByteDance - O Melhor da ByteDance
ByteDance - O Melhor da ByteDance Todos os modelos
Todos os modelos Planos Empresariais
Planos Empresariais Desenvolvimento de aplicações de IA
Desenvolvimento de aplicações de IA API de tradução de IA
API de tradução de IA Serviço de SEO/GEO com IA
Serviço de SEO/GEO com IA Serviço de Relações Públicas Otimizado por Geolocalização
Serviço de Relações Públicas Otimizado por Geolocalização Serviço de Web Scraping
Serviço de Web Scraping OpenClaw
OpenClaw Principais ferramentas de IA
Principais ferramentas de IA Os melhores robôs de IA
Os melhores robôs de IA
 Conecte-se
Conecte-se



const main = async () => {
const response = await fetch('https://api.ai.cc/v2/generate/video/alibaba/generation', {
method: 'POST',
headers: {
Authorization: 'Bearer ',
'Content-Type': 'application/json',
},
body: JSON.stringify({
model: 'alibaba/wan2.1-t2v-turbo',
prompt: 'A DJ on the stand is playing, around a World War II battlefield, lots of explosions, thousands of dancing soldiers, between tanks shooting, barbed wire fences, lots of smoke and fire, black and white old video: hyper realistic, photorealistic, photography, super detailed, very sharp, on a very white background',
aspect_ratio: '16:9',
}),
}).then((res) => res.json());
console.log('Generation:', response);
};
main()
import requests
def main():
url = "https://api.ai.cc/v2/generate/video/alibaba/generation"
payload = {
"model": "alibaba/wan2.1-t2v-turbo",
"prompt": "A DJ on the stand is playing, around a World War II battlefield, lots of explosions, thousands of dancing soldiers, between tanks shooting, barbed wire fences, lots of smoke and fire, black and white old video: hyper realistic, photorealistic, photography, super detailed, very sharp, on a very white background",
"aspect_ratio": "16:9",
}
headers = {"Authorization": "Bearer ", "Content-Type": "application/json"}
response = requests.post(url, json=payload, headers=headers)
print("Generation:", response.json())
if __name__ == "__main__":
main()

.webp)
Detalhes do produto
Wan2.1 Turbo da Alibaba é um modelo de IA de conversão de texto em vídeo de última geração, projetado especificamente para geração eficiente Equilibrando desempenho superior e velocidade, ele processa extensas entradas contextuais e se destaca na produção de resultados. vídeos de alta qualidade, apresentando dinâmica temporal suave e alinhamento semântico preciso entre descrições textuais e resultados visuais.
✨ Especificações Técnicas
Indicadores de desempenho
- ✅ Bancada VQA: Aumenta a eficiência do turbo; números específicos disponíveis mediante solicitação.
- ✅ Raciocínio multimodal: Demonstra forte capacidade de raciocínio tanto em formato de vídeo quanto de texto.
- ✅ Recuperação multimodal: Garante uma precisão de recuperação robusta, otimizada para tarefas de visão e linguagem em larga escala.
Métricas de desempenho
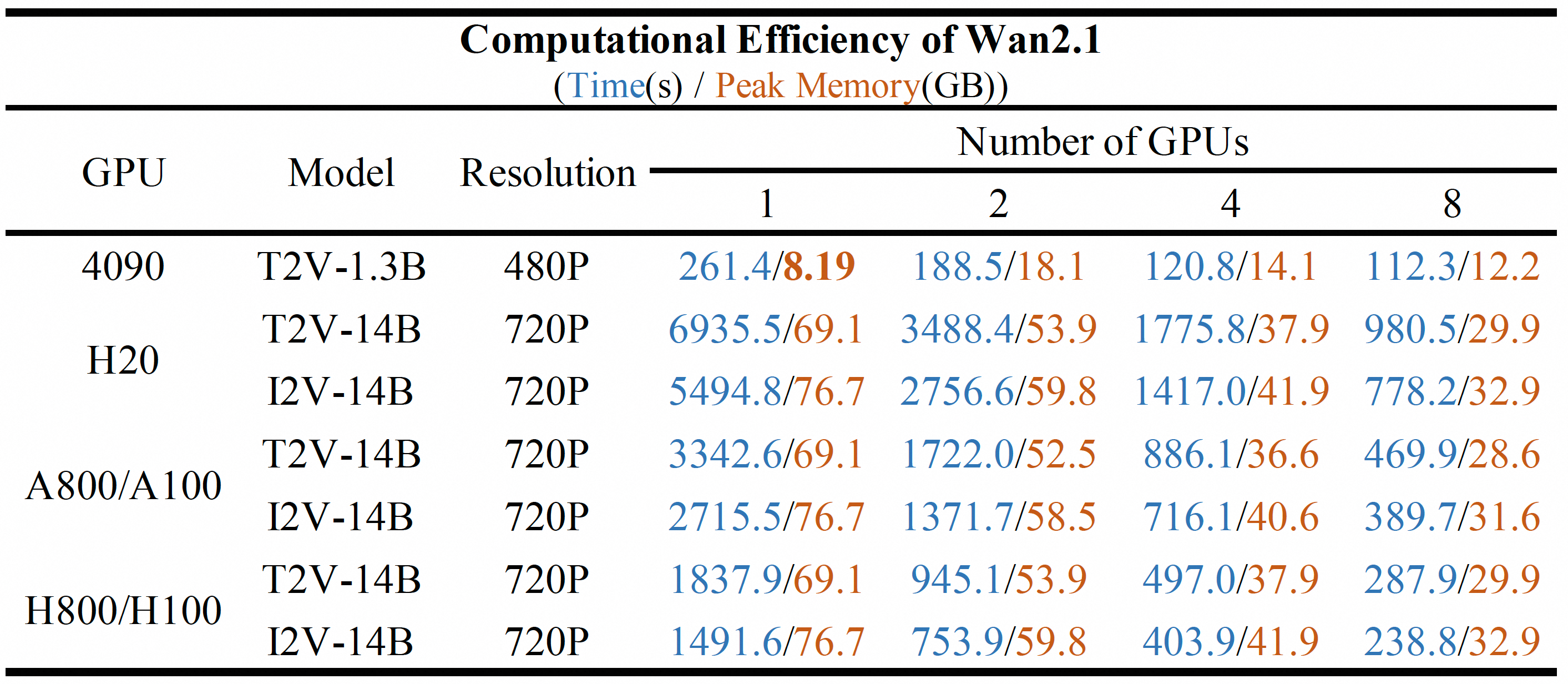
Wan2.1 Turbo oferece excelente qualidade de geração de vídeo ao mesmo tempo que reduz significativamente o tempo de inferência e os recursos computacionais em comparação com modelos maiores. Isso o torna excepcionalmente adequado para aplicações em tempo real ou sensíveis a custosO modelo preserva os pontos fortes característicos do Alibaba em termos de movimento dinâmico, relações espaciais e precisão composicional.
Principais capacidades
- 💡 Fusão Visão-Linguagem: Integra e gera conteúdo de vídeo de forma transparente, com base em descrições textuais detalhadas.
- 🚀 Geração em Tempo Real: Oferece velocidade de inferência turbinada, permitindo saídas de vídeo mais rápidas sem comprometimento substancial da qualidade.
- 🧠 Compreensão contextual: Mantém um raciocínio robusto em várias etapas e garante a consistência narrativa em todos os vídeos gerados.
Preços da API
💰 Apenas US$ 0,189 por vídeo
🎯 Casos de uso ideais
- 🎥 Geração de texto para vídeo: Ideal para síntese de vídeo rápida e de alta qualidade diretamente a partir de entrada de texto.
- ⚡ Criação de conteúdo em tempo real: Ideal para aplicações que exigem rápidas atualizações de vídeo e entrega de conteúdo dinâmico.
- 🔗 Fluxos de trabalho multimodais: Apoia projetos que integram dados de visão e linguagem para inteligência de negócios, entretenimento e produção de mídia criativa.
💻 Exemplo de código
📊 Comparação com outros modelos
Contra Wan2.2-T2V: O Wan2.1 Turbo oferece inferência significativamente mais rápida e melhor custo-benefício, embora com uma resolução máxima de geração e um tamanho de modelo ligeiramente menores.
Contra Gemini 2.5 Flash: Oferece precisão multimodal competitiva, além de ser altamente otimizada para velocidade.
Em comparação com o OpenAI GPT-4 Vision: Apresenta uma janela de contexto menor, mas demonstra ser mais econômico para tarefas específicas de geração de vídeo.
Contra Qwen3-235B-A22B: Prioriza a eficiência turbo, enquanto o Wan2.1 Turbo oferece uma precisão de recuperação ligeiramente melhor em contextos específicos.
⚠️ Limitações
Algumas saídas geradas podem ocasionalmente incluir pequenos artefatos ou exibir texturas menos detalhadas em comparação com os maiores modelos Wan2.2. No entanto, esses problemas geralmente podem ser minimizados de forma eficaz através de engenharia rápida ou técnicas de pós-processamento.
❓ Perguntas Frequentes
P: Qual arquitetura computacional possibilita a velocidade de inferência excepcional do Wan2.1 Turbo?
A: O Wan2.1 Turbo emprega uma arquitetura híbrida revolucionária, combinando redes especializadas esparsas com caminhos computacionais dinâmicos. Isso permite que o modelo ative apenas subconjuntos de parâmetros relevantes, reduzindo a sobrecarga computacional em 67% em comparação com modelos densos. Ele também integra mecanismos avançados de quantização e atenção com uso eficiente de memória, juntamente com um novo mecanismo de omissão de tokens para processamento em tempo real de tokens semanticamente críticos.
P: Como o Wan2.1 Turbo mantém a qualidade apesar da otimização agressiva?
A: O modelo mantém uma qualidade excepcional por meio da sofisticada destilação de conhecimento de arquiteturas WAN maiores, preservando padrões de raciocínio críticos. Ele incorpora processos de refinamento em múltiplos estágios que ajustam dinamicamente a profundidade de processamento com base na complexidade da tarefa, garantindo respostas rápidas para consultas simples e análises mais profundas para as complexas. O monitoramento contínuo do espaço latente detecta e corrige potenciais degradações de qualidade em tempo real.
P: Quais aplicações em tempo real se beneficiam mais das otimizações de latência do Wan2.1 Turbo?
A: O Wan2.1 Turbo se destaca em domínios sensíveis à latência, como análise de negociação de alta frequência (requisitos abaixo de 10 ms), plataformas educacionais interativas que suportam milhares de usuários simultâneos, tradução multilíngue em tempo real em conversas ao vivo, sistemas de decisão para veículos autônomos que exigem interpretação ambiental instantânea e operações de atendimento ao cliente em larga escala, onde a consistência e a velocidade de resposta impactam diretamente a satisfação do usuário e a eficiência operacional.
P: Como a eficiência energética do modelo se compara às arquiteturas convencionais?
A: O Wan2.1 Turbo alcança uma eficiência energética sem precedentes por meio de gerenciamento de energia sensível ao contexto, aritmética de precisão adaptativa e otimização sofisticada da hierarquia de cache. Os resultados dos testes de desempenho demonstram uma redução de 58% no consumo de energia por inferência, mantendo 94% das métricas de qualidade dos modelos originais, tornando-o excepcionalmente adequado para implantação na borda da rede e iniciativas de computação ambientalmente conscientes.
P: Que flexibilidade de implementação o Wan2.1 Turbo oferece em diferentes plataformas de hardware?
A: O modelo oferece excepcional adaptabilidade de hardware por meio de sua arquitetura modular, suportando a reconfiguração dinâmica para diversas unidades de processamento. Ele apresenta otimização especializada para clusters de GPUs com paralelismo tensorial eficiente, implantação de CPU com utilização avançada do conjunto de instruções e compatibilidade com hardware neuromórfico emergente. A estrutura de implantação inclui detecção e configuração automática de hardware, permitindo transições perfeitas entre infraestrutura em nuvem, dispositivos de borda e plataformas móveis, mantendo características de desempenho consistentes.
Playground de IA

