 OpenAI - ChatGPT, Sora
OpenAI - ChatGPT, Sora Google - Gemini, Nano Banana
Google - Gemini, Nano Banana Antrópico - Claude
Antrópico - Claude xAI - Grok
xAI - Grok Busca profunda
Busca profunda Alibaba - Qwen
Alibaba - Qwen ByteDance - O Melhor da ByteDance
ByteDance - O Melhor da ByteDance Todos os modelos
Todos os modelos Planos Empresariais
Planos Empresariais Desenvolvimento de aplicações de IA
Desenvolvimento de aplicações de IA API de tradução de IA
API de tradução de IA Serviço de SEO/GEO com IA
Serviço de SEO/GEO com IA Serviço de Relações Públicas Otimizado por Geolocalização
Serviço de Relações Públicas Otimizado por Geolocalização Serviço de Web Scraping
Serviço de Web Scraping OpenClaw
OpenClaw Principais ferramentas de IA
Principais ferramentas de IA Os melhores robôs de IA
Os melhores robôs de IA
 Conecte-se
Conecte-se



const main = async () => {
const response = await fetch('https://api.ai.cc/v2/generate/video/alibaba/generation', {
method: 'POST',
headers: {
Authorization: 'Bearer ',
'Content-Type': 'application/json',
},
body: JSON.stringify({
model: 'alibaba/wan2.2-t2v-plus',
prompt: 'A DJ on the stand is playing, around a World War II battlefield, lots of explosions, thousands of dancing soldiers, between tanks shooting, barbed wire fences, lots of smoke and fire, black and white old video: hyper realistic, photorealistic, photography, super detailed, very sharp, on a very white background',
aspect_ratio: '16:9',
}),
}).then((res) => res.json());
console.log('Generation:', response);
};
main()
import requests
def main():
url = "https://api.ai.cc/v2/generate/video/alibaba/generation"
payload = {
"model": "alibaba/wan2.2-t2v-plus",
"prompt": "A DJ on the stand is playing, around a World War II battlefield, lots of explosions, thousands of dancing soldiers, between tanks shooting, barbed wire fences, lots of smoke and fire, black and white old video: hyper realistic, photorealistic, photography, super detailed, very sharp, on a very white background",
"aspect_ratio": "16:9",
}
headers = {"Authorization": "Bearer ", "Content-Type": "application/json"}
response = requests.post(url, json=payload, headers=headers)
print("Generation:", response.json())
if __name__ == "__main__":
main()

.webp)
Detalhes do produto
Alibaba Wan2.2 é de última geração modelo de IA meticulosamente projetado para aplicações avançadas compreensão multimodalEle integra perfeitamente entradas de texto e de visão, oferecendo recursos robustos para processamento de contexto amplo e proporcionando precisão superior em tarefas complexas de conversão de texto em visão e desafios de raciocínio intrincados.
✨ Especificações Técnicas
Indicadores de desempenho
- ✅ Bancada VQA: 78,3%
- ✅ Raciocínio multimodal: 52,7%
- ✅ Recuperação multimodal: 81,9%
Métricas de desempenho (WAN 2.1)
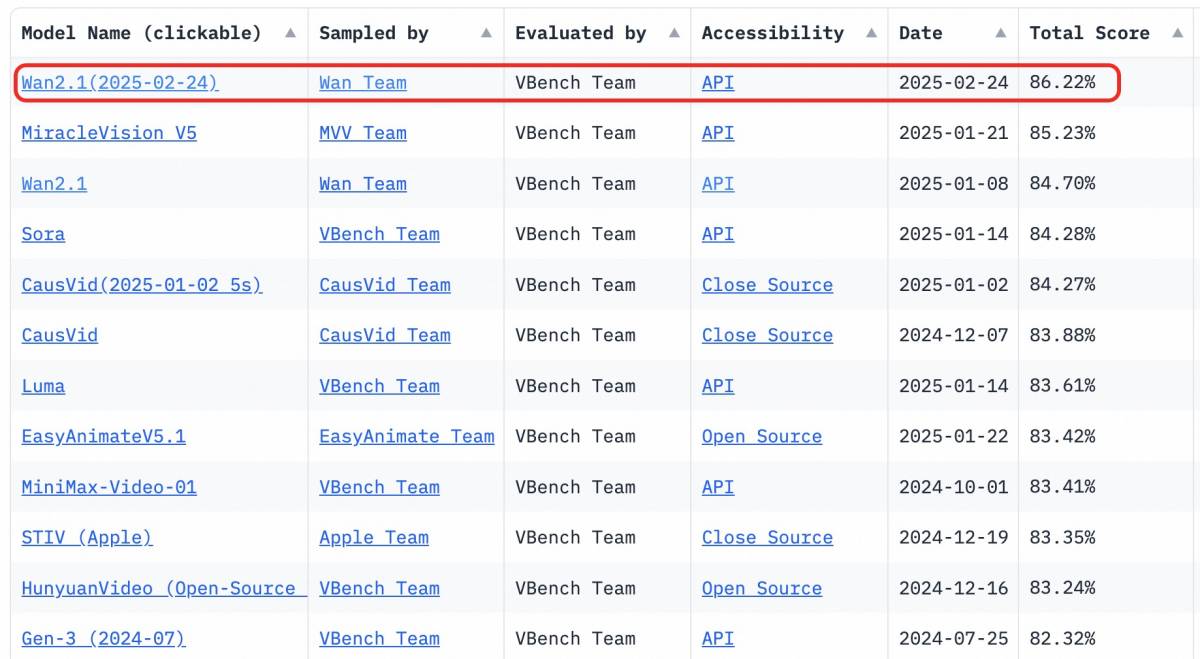
Wan2.1 lidera com um impressionante desempenho geral. Pontuação VBench de 86,22%, demonstrando desempenho excepcional em movimento dinâmico, relações espaciais, precisão de cores e interação com múltiplos objetos. O treinamento de modelos de vídeo fundamentais exige poder computacional significativo e acesso a vastos conjuntos de dados de alta qualidade. O acesso aberto a esses modelos avançados reduz drasticamente as barreiras, permitindo que mais empresas criem conteúdo visual personalizado e de alta qualidade de maneira econômica.
Principais capacidades
- 💡 Fusão Visão-Linguagem: Destaca-se na interpretação e geração de respostas precisas, combinando perfeitamente dados de imagem e texto.
- 💡 Raciocínio Avançado: Demonstra forte capacidade de raciocínio em múltiplas etapas em diversas modalidades para análises aprofundadas e compreensão complexa.
💲 Preços da API
- 🎥 480P: US$ 0,105/vídeo
- 🎥 1080P: US$ 0,525/vídeo
🚀 Casos de uso ideais
- ✅ Análise multimodal: Aprimorando a compreensão por meio da combinação especializada de dados de imagem e texto.
- ✅ Resposta visual a perguntas (VQA): Fornecer respostas precisas e contextualizadas com base em entradas integradas de imagem e texto.
- ✅ Recuperação multimodal: Permitir a correspondência e recuperação eficientes de informações nos domínios da visão e da linguagem.
- ✅ Inteligência de Negócios: Facilitar a interpretação de dados complexos através da integração de conteúdo visual com análises textuais para obter insights mais profundos.
💻 Exemplo de código
📊 Comparação com outros modelos líderes
- Contra Gemini 2.5 Flash: O Alibaba Wan2.2 oferece maior precisão multimodal (78,3% vs. 70,8% VQA-bench), tornando-a uma escolha superior para tarefas integradas de visão e linguagem.
- Em comparação com o OpenAI GPT-4 Vision: Wan2.2 fornece uma janela de contexto significativamente maior (65 mil vs. 32 mil tokens texto), possibilitando conversas mais extensas e coerentes com imagens incorporadas.
- Contra Qwen3-235B-A22B: O Alibaba Wan2.2 demonstra precisão superior na recuperação multimodal (81,9% vs. ~78% estimado), otimizando-o para fluxos de trabalho exigentes de visão computacional em larga escala.
⚠️ Limitações
Ocasionalmente, vídeos gerados podem conter elementos indesejados, como artefatos de texto ou marcas d'água. Embora o uso de avisos negativos possa ajudar a mitigar essas ocorrências, não as elimina completamente.
🔗 Integração de API
O Alibaba Wan2.2 é facilmente acessível através do API de IA/MLDocumentação completa está disponível para facilitar um processo de integração tranquilo e eficiente.
❓ Perguntas frequentes (FAQ)
A: O Alibaba Wan2.2 é um modelo avançado de IA projetado para compreensão multimodal, integrando especificamente entradas de texto e visão para raciocínio complexo e tarefas de conversão de texto em visão de alta precisão.
A: O Wan2.2 demonstra maior precisão multimodal (78,3% no teste VQA) em comparação com o Gemini 2.5 Flash (70,8%), tornando-o particularmente eficaz para tarefas integradas de visão e linguagem.
A: Suas principais capacidades incluem uma fusão robusta de visão e linguagem para interpretar e gerar conteúdo a partir de dados combinados de imagem e texto, além de raciocínio avançado em múltiplas etapas entre diferentes modalidades.
A: Ocasionalmente, vídeos gerados podem conter elementos indesejados, como artefatos de texto ou marcas d'água. Embora as configurações de aviso possam atenuar esses problemas, elas não os eliminam completamente.
A: O Alibaba Wan2.2 é facilmente acessível através da API de IA/ML, com documentação completa fornecida para orientar o processo de integração.
Playground de IA

