 OpenAI - ChatGPT, Sora
OpenAI - ChatGPT, Sora Google - Gemini, Nano Banana
Google - Gemini, Nano Banana Антропический - Клод
Антропический - Клод xAI - Grok
xAI - Grok Глубокий поиск
Глубокий поиск Alibaba - Qwen
Alibaba - Qwen ByteDance - Лучшее от ByteDance
ByteDance - Лучшее от ByteDance Все модели
Все модели Планы предприятия
Планы предприятия Разработка приложений на основе искусственного интеллекта
Разработка приложений на основе искусственного интеллекта API для перевода с помощью ИИ
API для перевода с помощью ИИ Услуги SEO/ГЕ с использованием ИИ
Услуги SEO/ГЕ с использованием ИИ Географически оптимизированная PR-служба
Географически оптимизированная PR-служба Сервис веб-скрейпинга
Сервис веб-скрейпинга OpenClaw
OpenClaw Лучшие инструменты ИИ
Лучшие инструменты ИИ Лучшие роботы с искусственным интеллектом
Лучшие роботы с искусственным интеллектом
 Авторизоваться
Авторизоваться



const main = async () => {
const response = await fetch('https://api.ai.cc/v2/generate/video/alibaba/generation', {
method: 'POST',
headers: {
Authorization: 'Bearer ',
'Content-Type': 'application/json',
},
body: JSON.stringify({
model: 'alibaba/wan2.2-t2v-plus',
prompt: 'A DJ on the stand is playing, around a World War II battlefield, lots of explosions, thousands of dancing soldiers, between tanks shooting, barbed wire fences, lots of smoke and fire, black and white old video: hyper realistic, photorealistic, photography, super detailed, very sharp, on a very white background',
aspect_ratio: '16:9',
}),
}).then((res) => res.json());
console.log('Generation:', response);
};
main()
import requests
def main():
url = "https://api.ai.cc/v2/generate/video/alibaba/generation"
payload = {
"model": "alibaba/wan2.2-t2v-plus",
"prompt": "A DJ on the stand is playing, around a World War II battlefield, lots of explosions, thousands of dancing soldiers, between tanks shooting, barbed wire fences, lots of smoke and fire, black and white old video: hyper realistic, photorealistic, photography, super detailed, very sharp, on a very white background",
"aspect_ratio": "16:9",
}
headers = {"Authorization": "Bearer ", "Content-Type": "application/json"}
response = requests.post(url, json=payload, headers=headers)
print("Generation:", response.json())
if __name__ == "__main__":
main()

.webp)
Подробная информация о товаре
Alibaba Wan2.2 является передовым модель ИИ Тщательно разработан для продвинутых пользователей. мультимодальное пониманиеОн обеспечивает бесшовную интеграцию текстовых и визуальных входных данных, предлагая мощные возможности для обработки больших контекстных данных и обеспечивая превосходную точность в сложных задачах преобразования текста в изображение и сложных задачах логического мышления.
✨ Технические характеристики
Показатели производительности
- ✅ VQA-тест: 78,3%
- ✅ Мультимодальное рассуждение: 52,7%
- ✅ Межмодальный поиск: 81,9%
Показатели производительности (Wan2.1)
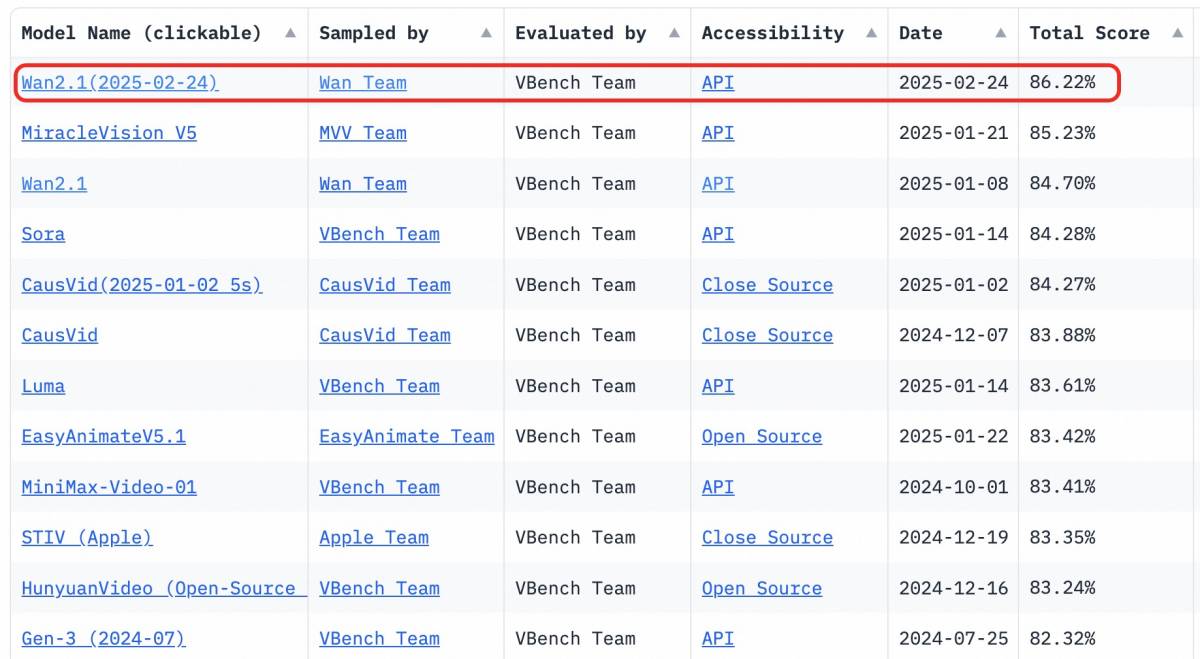
Wan2.1 лидирует с впечатляющим общим результатом. Результат теста VBench: 86,22%.демонстрируя исключительную производительность в динамическом движении, пространственных отношениях, точности цветопередачи и взаимодействии нескольких объектов. Обучение базовых видеомоделей требует значительных вычислительных мощностей и доступа к обширным высококачественным наборам данных. Открытый доступ к таким продвинутым моделям значительно снижает барьеры, позволяя большему числу компаний создавать персонализированный высококачественный визуальный контент экономически эффективным способом.
Ключевые возможности
- 💡 Слияние визуального и языкового восприятия: Отлично справляется с интерпретацией и формированием точных ответов, органично сочетая изображения и текстовые данные.
- 💡 Сложные логические рассуждения: Демонстрирует развитые навыки многоступенчатого логического мышления в различных контекстах для углубленного анализа и комплексного понимания.
💲 Цены на API
- 🎥 480P: 0,105 доллара за видео
- 🎥 1080P: 0,525 доллара за видео
🚀 Оптимальные варианты использования
- ✅ Мультимодальный анализ: Улучшение понимания за счет умелого сочетания изображений и текстовых данных.
- ✅ Визуальные ответы на вопросы (VQA): Предоставление точных и контекстно-зависимых ответов на основе интегрированных данных, полученных из изображений и текста.
- ✅ Межмодальный поиск: Обеспечение эффективного сопоставления и поиска информации как в области зрения, так и в области языка.
- ✅ Бизнес-аналитика: Упрощение интерпретации сложных данных путем интеграции визуального контента с текстовой аналитикой для получения более глубоких выводов.
💻 Пример кода
📊 Сравнение с другими ведущими моделями
- Против. Вспышка Gemini 2.5: Alibaba Wan2.2 обеспечивает более высокую точность мультимодального взаимодействия (78,3% против 70,8% VQA-теста), что делает его превосходным выбором для интегрированных задач, сочетающих зрение и язык.
- В сравнении с OpenAI GPT-4 Vision: Wan2.2 обеспечивает значительно большее контекстное окно (65 тыс. против 32K токенов текста), что позволяет вести более развернутые и связные беседы со встроенными изображениями.
- Против Qwen3-235B-A22B: Alibaba Wan2.2 демонстрирует превосходную точность поиска по различным модальностям (81,9% против примерно 78% по оценкам), оптимизируя его для сложных крупномасштабных рабочих процессов обработки изображений и языка.
⚠️ Ограничения
Иногда в сгенерированных видеороликах могут содержаться нежелательные элементы, такие как текстовые артефакты или водяные знаки. Хотя использование негативных подсказок может помочь смягчить эти проблемы, оно не устраняет их полностью.
🔗 Интеграция API
Доступ к Alibaba Wan2.2 осуществляется через API для ИИ/машинного обученияДля обеспечения плавного и эффективного процесса интеграции доступна полная документация.
❓ Часто задаваемые вопросы (FAQ)
A: Alibaba Wan2.2 — это передовая модель искусственного интеллекта, разработанная для многомодального понимания, в частности, для интеграции текстовых и визуальных входных данных с целью сложных рассуждений и высокоточных задач преобразования текста в изображение.
A: Wan2.2 демонстрирует более высокую многомодальную точность (78,3% по результатам теста VQA) по сравнению с Gemini 2.5 Flash (70,8%), что делает его особенно эффективным для интегрированных задач обработки визуальной и языковой информации.
А: Его основные возможности включают в себя надежное слияние визуальной и языковой информации для интерпретации и генерации контента из объединенных данных изображений и текста, а также расширенное многоэтапное логическое мышление в различных модальностях.
А: Иногда в сгенерированных видеороликах могут содержаться нежелательные элементы, такие как текстовые артефакты или водяные знаки. Хотя негативные подсказки могут смягчить эти проблемы, они не устраняют их полностью.
A: Доступ к Alibaba Wan2.2 осуществляется через API искусственного интеллекта/машинного обучения, а подробная документация поможет в процессе интеграции.
Игровая площадка для ИИ

