 OpenAI - ChatGPT, Sora
OpenAI - ChatGPT, Sora Google - Gemini, Nano Banana
Google - Gemini, Nano Banana Antrópico - Claude
Antrópico - Claude xAI - Grok
xAI - Grok Búsqueda profunda
Búsqueda profunda Alibaba - Reina
Alibaba - Reina ByteDance - Lo mejor de ByteDance
ByteDance - Lo mejor de ByteDance Todos los modelos
Todos los modelos Planes empresariales
Planes empresariales Desarrollo de aplicaciones de IA
Desarrollo de aplicaciones de IA API de traducción de IA
API de traducción de IA Servicio de SEO/GEO con IA
Servicio de SEO/GEO con IA Servicio de relaciones públicas geooptimizado
Servicio de relaciones públicas geooptimizado Servicio de extracción de datos web
Servicio de extracción de datos web OpenClaw
OpenClaw Las mejores herramientas de IA
Las mejores herramientas de IA Los mejores robots de IA
Los mejores robots de IA
 Acceso
Acceso













Comparación de API de IA de 2026: OpenAI, Anthropic Claude, Google Gemini y Grok

Comparativa de API de IA para 2026:
OpenAI contra Claude
vs Géminis vs Grok
En marzo de 2026, el panorama de las API de IA nunca ha sido más competitivo, ni más confuso. Grok 4.1 Rápido rompiendo récords de precios, Gemini 3.1 Pro domina el razonamiento de contexto largo, y Claude Opus 4.6 liderando en codificación y escrituraElegir la API LLM adecuada puede ser crucial para el éxito o el fracaso del presupuesto de tu proyecto. Esta guía analiza los precios, los puntos de referencia, las ventajas y el código de integración de las cuatro API líderes.
%252520Top%252520Large%252520Language%252520Models_%252520A%252520Comparative%252520Analysis.png)
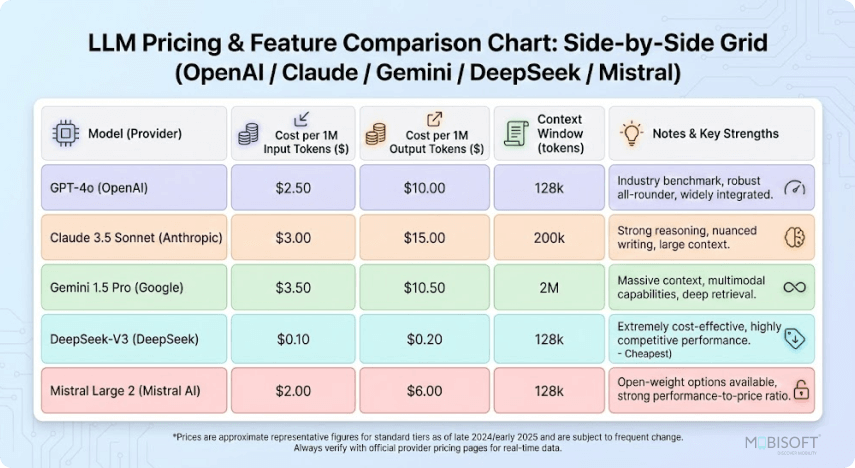
// Comparación de precios y características de las API de LLM modernas: descripción general visual de las estructuras de costos de los principales proveedores (2026)
Precios de la API de IA en 2026 (por millón de tokens)
Los precios han convergido drásticamente, pero aún existen grandes diferencias, especialmente a gran escala. Últimos datos, marzo de 2026:
| Proveedor | Modelo | Entrada ($/1M) | Producción ($/1M) | Ventana de contexto | Lo mejor para | Descuento almacenado en caché |
|---|---|---|---|---|---|---|
| OpenAI | GPT-5.4 (versión insignia) | $2.50 | $15.00 | Más de 400.000 | Empresa equilibrada | Hasta un 90% |
| OpenAI | GPT-5.4-mini | $0.75 | $4.50 | 400 mil | Codificación y agentes | Hasta un 90% |
| Antrópico | Claude Opus 4.6 | $5.00 | $25.00 | 200.000 (1 millón en versión beta) | Razonamiento profundo y escritura | Almacenamiento en caché potente |
| Antrópico | Soneto 4.6 de Claude | $3.00 | $15.00 | 200.000 (1 millón en versión beta) | Punto dulce más popular | Almacenamiento en caché potente |
| Gemini 3.1 Pro | $2.00 | $12.00 | 2M | Contexto multimodal y extenso | Excelente | |
| Géminis 3 Flash | $0.50 | $3.00 | Más de 1 millón | Velocidad de alto volumen | Excelente | |
| xAI Grok | Grok 4.1 Rápido | $0.20 | $0.50 | 2M | Sensible al costo y codificación | Competitivo |
| xAI Grok | Comprender 4 | $3.00 | $15.00 | 256K–2M | En tiempo real y sin censura | Competitivo |
Conclusión principal: Grok 4.1 Fast es la opción de alto contexto más económica indiscutible en 2026. Claude Opus 4.6 mantiene un precio elevado, pero ofrece una profundidad inigualable. Gemini ofrece la mejor relación precio-contexto para trabajos multimodales.

// Gemini vs GPT vs Claude vs Grok: comparación de capacidades de modelos de IA (2026)
Indicadores de rendimiento — Marzo de 2026
Ningún modelo es infalible. Así es como se comparan en los principales benchmarks independientes:
| Punto de referencia | Gemini 3.1 Pro | Claude Opus 4.6 | GPT-5.4 | Grok 4.1 Rápido | Ganador |
|---|---|---|---|---|---|
| GPQA Diamante (nivel de doctorado) | 94,3% | 91,3% | 92,8% | ~88% | Géminis |
| ARC-AGI-2 (razonamiento novedoso) | 77,1% | 68,8% | ~70% | ~16% | Géminis |
| SWE-Bench (programación) | 80,6% | 80,8% | 74,9% | ~75% | Claude |
| LiveCodeBench (programación) | Fuerte | Líder | Fuerte | Fuerte | Claude |
| Multimodal (visión/vídeo) | líder nativo | Bien | Fuerte | Texto primero | Géminis |
| En tiempo real / Sin censura | Bien | Conservador | Bien | Líder | Comprender |
& escribiendo
contexto masivo
producción
codificación/agentes
Ventajas, desventajas y mejores casos de uso


Ejemplos de código de integración — Python 2026
Ejemplos minimalistas y listos para producción que utilizan SDK oficiales. Todos se pueden intercambiar en menos de 5 minutos en una plataforma unificada.
from openai import OpenAI client = OpenAI(api_key="your-openai-key") response = client.chat.completions.create( model="gpt-5.4", messages=[{"role": "user", "content": "Explicar la computación cuántica en un párrafo"}], temperature=0.7 ) print(response.choices[0].message.content) 
// Panel de control de codificación de IA que muestra el flujo de trabajo de desarrollo asistido por LLM
from anthropic import Anthropic client = Anthropic(api_key="your-anthropic-key") response = client.messages.create( model="claude-4.6-sonnet", max_tokens=1024, messages=[{"role": "user", "content": "Write a professional email..."}] ) print(response.content[0].text) import google.generativeai as genai genai.configure(api_key="your-gemini-key") model = genai.GenerativeModel("gemini-3.1-pro") response = model.generate_content("Analiza esta imagen y resume las tendencias", stream=False) print(response.text) from xai import Grok # SDK oficial client = Grok(api_key="your-grok-key") response = client.chat.completions.create( model="grok-4.1-fast", messages=[{"role": "user", "content": "Últimas tendencias X en agentes de IA"}], temperature=0.8 ) print(response.choices[0].message.content) Para obtener un consejo: Utilice LangChain o LlamaIndex para abstraerlos por completo y, a continuación, cambie de modelo con una sola línea de código.
Consejos para optimizar los costos en 2026
- Usar almacenamiento en caché — Los cuatro proveedores ahora lo respaldan ampliamente, con ahorros de hasta el 90% en contextos repetidos.
- Dirige las tareas sencillas a modelos más económicos: Grok 4.1 Rápido o Destello de Géminis para solicitudes de gran volumen.
- Usar API por lotes Donde esté disponible: ahorros de más del 50 % en cargas de trabajo que no sean en tiempo real.
- Supervise el uso de los tokens en tiempo real: pequeños cambios de ingeniería rápidos pueden reducir los costos entre un 30 % y un 70 %.

// Felix: panel de desarrollo de IA multi-backend para monitorear el gasto y el enrutamiento entre proveedores de LLM.
Deja de hacer malabares con las API.
Empiece a construir más rápido.
Gestionar cuatro SDK, claves, límites de velocidad y paneles de facturación diferentes es complicado. Los equipos inteligentes consolidan todo en una sola plataforma con una clave, un panel y acceso instantáneo a todos los modelos principales.