 OpenAI - ChatGPT, Sora
OpenAI - ChatGPT, Sora Google - Gemini, Nano Banana
Google - Gemini, Nano Banana Antrópico - Claude
Antrópico - Claude xAI - Grok
xAI - Grok Búsqueda profunda
Búsqueda profunda Alibaba - Reina
Alibaba - Reina ByteDance - Lo mejor de ByteDance
ByteDance - Lo mejor de ByteDance Todos los modelos
Todos los modelos Planes empresariales
Planes empresariales Desarrollo de aplicaciones de IA
Desarrollo de aplicaciones de IA API de traducción de IA
API de traducción de IA Servicio de SEO/GEO con IA
Servicio de SEO/GEO con IA Servicio de relaciones públicas geooptimizado
Servicio de relaciones públicas geooptimizado Servicio de extracción de datos web
Servicio de extracción de datos web OpenClaw
OpenClaw Las mejores herramientas de IA
Las mejores herramientas de IA Los mejores robots de IA
Los mejores robots de IA
 Acceso
Acceso



const { OpenAI } = require('openai');
const api = new OpenAI({
baseURL: 'https://api.ai.cc/v1',
apiKey: '',
});
const main = async () => {
const result = await api.chat.completions.create({
model: 'deepseek/deepseek-non-reasoner-v3.1-terminus',
messages: [
{
role: 'system',
content: 'You are an AI assistant who knows everything.',
},
{
role: 'user',
content: 'Tell me, why is the sky blue?'
}
],
});
const message = result.choices[0].message.content;
console.log(`Assistant: ${message}`);
};
main();
import os
from openai import OpenAI
client = OpenAI(
base_url="https://api.ai.cc/v1",
api_key="",
)
response = client.chat.completions.create(
model="deepseek/deepseek-non-reasoner-v3.1-terminus",
messages=[
{
"role": "system",
"content": "You are an AI assistant who knows everything.",
},
{
"role": "user",
"content": "Tell me, why is the sky blue?"
},
],
)
message = response.choices[0].message.content
print(f"Assistant: {message}")


Detalles del producto
✨ DeepSeek V3.1 Terminus (Modo sin razonamiento): IA de alta velocidad y eficiencia para tareas directas
El Terminal de DeepSeek V3.1 modelo, específicamente en su modo no razonadoDeepSeek V3.1 es un modelo de lenguaje avanzado y de gran tamaño, meticulosamente diseñado para generar contenido de forma rápida, eficiente y ligera. Está pensado para destacar en tareas que no requieren un razonamiento analítico profundo, lo que lo hace ideal para la generación de contenido sencilla. Como parte de la serie DeepSeek V3.1, ofrece mejoras sustanciales en estabilidad, coherencia multilingüe y fiabilidad en el uso de herramientas, lo que lo convierte en una opción óptima para flujos de trabajo de agentes que exigen velocidad y bajo consumo de recursos.
⚙️ Especificaciones técnicas
- • Familia modelo: DeepSeek V3.1 Terminus (Modo sin razonamiento)
- • Parámetros: 671 mil millones en total, 37 mil millones activos en inferencia
- • Arquitectura: Modelo lógico-legal híbrido con inferencia de modo dual (pensamiento y no pensamiento)
- • Ventana de contexto: Admite hasta 128.000 tokens entrenamiento de contexto largo
- • Precisión y eficiencia: Utiliza Microescalado FP8 para la eficiencia de la memoria y la inferencia
- • Modos: El modo sin razonamiento desactiva la cadena de pensamiento elaborada para respuestas más rápidas
- • Soporte de idiomas: Mayor coherencia multilingüe, en particular en Inglés y chino
📊 Puntos de referencia de rendimiento
- • Razonamiento (MMLU-Pro): 85.0 (ligera mejoría)
- • Navegación web agencial (BrowseComp): 38.5 (Aumentos significativos en el uso de herramientas de múltiples pasos)
- • Línea de comandos (Terminal-bench): 36,7 (mejor manejo de secuencias de comandos)
- • Generación de código (LiveCodeBench): 74.9 (Se mantienen altas capacidades)
- • Verificación de Ingeniería de Software (SWE Verified): 68.4 (mejora de la precisión de la validación)
- • Precisión del control de calidad (SimpleQA): 96.8 (rendimiento robusto)
- • Estabilidad general: Varianza reducida y resultados más deterministas para una mayor fiabilidad en el mundo real.
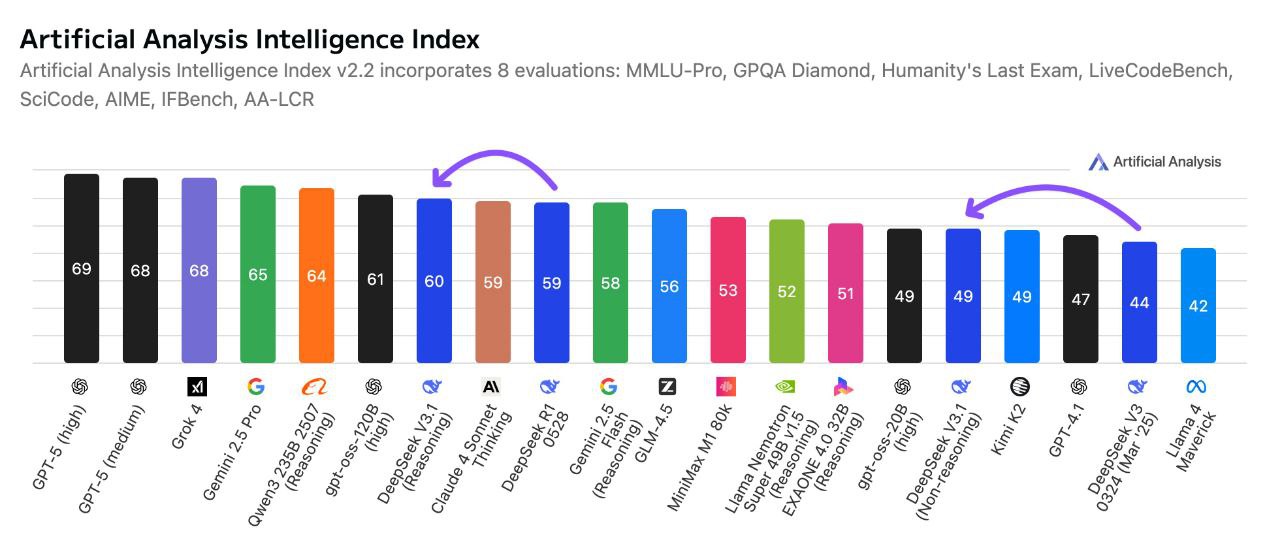
Pruebas de rendimiento: DeepSeek V3.1 Terminus en acción
⭐ Características principales
- 🚀 Generación rápida y ligera: El modo de no pensamiento priorizado garantiza Tiempo de procesamiento y consumo de recursos reducidos.Ideal para resultados rápidos.
- 🌐 Salida multilingüe robusta: Las mejoras evitan la mezcla de idiomas y los tokens inconsistentes, lo que permite... aplicaciones globales.
- 🛠️ Uso mejorado de las herramientas: Refuerza la fiabilidad en los flujos de trabajo de invocación de herramientas, incluyendo: Cadenas de ejecución de código y búsqueda web.
- 📖 Contexto largo flexible: Admite contextos masivos de hasta 128.000 tokens para historiales de entrada extensos.
- ✅ Resultados estables y consistentes: Las optimizaciones posteriores al entrenamiento reducen significativamente las alucinaciones y los artefactos de tokenización.
- 🔄 Compatible con versiones anteriores: Se integra a la perfección en los ecosistemas de API de DeepSeek existentes sin necesidad de realizar cambios disruptivos.
- ⚡ Inferencia híbrida escalable: Equilibra la capacidad de los modelos a gran escala con una implementación eficiente de parámetros activos.
💰 Precios de API
- • 1 millón de tokens de entrada: $0.294
- • 1 millón de tokens de salida: $0.441
💡 Casos de uso prácticos
- 💬 Soporte al cliente rápido: Respuestas rápidas y eficientes del chatbot.
- ✍️ Generación de contenido multilingüe: Textos publicitarios, resúmenes y mucho más en varios idiomas.
- 👨💻 Asistencia automatizada para la codificación: Ejecución de scripts y generación de código básico.
- 📚 Consulta de la base de conocimientos: Búsqueda y recuperación eficientes dentro de documentos extensos.
- ⚙️ Automatización de tareas asistida por herramientas: Flujos de trabajo optimizados con una invocación de herramientas fiable.
- 📄 Resumen rápido del documento: Resúmenes rápidos sin explicaciones analíticas profundas.
💻 Ejemplo de código
🤝 Comparación con otros modelos líderes
DeepSeek V3.1 Terminus vs. GPT-4: DeepSeek V3.1 Terminus ofrece una ventana de contexto significativamente más grande (hasta 128.000 tokens) en comparación con los 32K tokens de GPT-4, lo que lo hace superior para documentos extensos e investigación. Está optimizado para generación más rápida en su modo especializado sin razonamiento, mientras que GPT-4 prioriza el razonamiento detallado con una latencia mayor.
DeepSeek V3.1 Terminus vs. GPT-5: Mientras que GPT-5 sobresale en tareas multimodales y una integración de ecosistema más amplia con un contexto aún mayor, DeepSeek V3.1 Terminus enfatiza rentabilidad y licencias de peso libre, resultando atractivo para desarrolladores y empresas emergentes centradas en capacidades de infraestructura.
DeepSeek V3.1 Terminus vs. Claude 4.5: Claude 4.5 prioriza la seguridad, la alineación y el razonamiento sólido con una IA constitucional robusta. DeepSeek V3.1 Terminus se centra en ligero, de rápida producciónClaude suele tener precios por tarea más altos, preferidos en industrias reguladas, mientras que DeepSeek ofrece Licencias abiertas y accesibilidad para la creación rápida de prototipos.
DeepSeek V3.1 Terminus vs. OpenAI GPT-4.5: GPT-4.5 mejora el razonamiento y la escritura creativa, pero comparte una ventana de contexto de tokens similar de 128K con DeepSeek. DeepSeek V3.1 Terminus logra tiempos de respuesta más rápidos en su modo sin razonamiento, lo que lo hace ideal para aplicaciones críticas en cuanto a velocidad sin una cadena de pensamiento compleja. GPT-4.5 cuenta con una generación creativa más fuerte y una mayor integración con el ecosistema, mientras que DeepSeek destaca en escalabilidad y eficiencia de costos.
❓ Preguntas frecuentes (FAQ)
P: ¿Qué significa "No razonamiento" para DeepSeek V3.1 Terminus?
A: «Sin razonamiento» significa que este modelo está optimizado para tareas que no requieren deducción lógica compleja, resolución de problemas en varios pasos ni pensamiento analítico profundo. Prioriza la generación directa de texto, preguntas y respuestas sencillas y un procesamiento directo con la máxima eficiencia y velocidad.
P: ¿Cuáles son las principales ventajas de utilizar la variante sin razonamiento?
A: Entre las principales ventajas se incluyen tiempos de respuesta significativamente más rápidos, menores costes computacionales, mayor rendimiento, uso eficiente de los recursos y un rendimiento optimizado para tareas sencillas en las que no son necesarias todas las capacidades de razonamiento de los modelos estándar.
P: ¿Cuál es el tamaño de la ventana de contexto para DeepSeek V3.1 Terminus Non-Rasoning?
A: DeepSeek V3.1 Terminus Non-Rasoning presenta una impresionante Ventana de contexto de token de 128K, lo que le permite procesar documentos extensos y mantener el contexto de manera efectiva para tareas sencillas de generación y procesamiento de texto.
P: ¿Para qué tipos de tareas es más adecuado este modelo?
A: Es ideal para la generación de texto simple, preguntas y respuestas básicas, resumen de contenido, clasificación de texto, traducciones sencillas, relleno de plantillas, extracción de datos y cualquier aplicación que requiera un procesamiento de texto rápido y confiable sin razonamientos complejos.
P: ¿Cómo se compara su velocidad con la de los modelos de razonamiento estándar?
A: La variante sin razonamiento suele responder De 2 a 4 veces más rápido que los modelos de razonamiento estándar para tareas sencillas, ofreciendo una latencia significativamente menor y un mayor rendimiento para aplicaciones de procesamiento de texto de gran volumen.
Campo de juegos de IA

