 OpenAI - ChatGPT, Sora
OpenAI - ChatGPT, Sora Google - Gemini, Nano Banana
Google - Gemini, Nano Banana Antrópico - Claude
Antrópico - Claude xAI - Grok
xAI - Grok Búsqueda profunda
Búsqueda profunda Alibaba - Reina
Alibaba - Reina ByteDance - Lo mejor de ByteDance
ByteDance - Lo mejor de ByteDance Todos los modelos
Todos los modelos Planes empresariales
Planes empresariales Desarrollo de aplicaciones de IA
Desarrollo de aplicaciones de IA API de traducción de IA
API de traducción de IA Servicio de SEO/GEO con IA
Servicio de SEO/GEO con IA Servicio de relaciones públicas geooptimizado
Servicio de relaciones públicas geooptimizado Servicio de extracción de datos web
Servicio de extracción de datos web OpenClaw
OpenClaw Las mejores herramientas de IA
Las mejores herramientas de IA Los mejores robots de IA
Los mejores robots de IA
 Acceso
Acceso



const axios = require('axios').default;
const api = axios.create({
baseURL: 'https://api.ai.cc/v1',
headers: { Authorization: 'Bearer ' },
});
const main = async () => {
const response = await api.post('/tts', {
model: 'inworld/tts-1',
text: 'OpenAI TTS are fast and powerful language models. Use it to convert text to natural sounding spoken text.',
voice: 'coral',
});
console.log('Audio URL:', response.data.audio.url);
console.log('Characters:', response.data.usage.characters);
};
main();
import requests
def main():
url = "https://api.ai.cc/v1/tts"
headers = {
"Authorization": "Bearer ",
}
payload = {
"model": "inworld/tts-1",
"text": "OpenAI TTS are fast and powerful language models. Use it to convert text to natural sounding spoken text.",
"voice": "coral"
}
response = requests.post(url, headers=headers, json=payload)
data = response.json()
print("Audio URL:", data["audio"]["url"])
print("Characters:", data["usage"]["characters"])
main()


Detalles del producto
✨ API TTS-1 integrada en el mundo virtual: Síntesis de voz avanzada en tiempo real
El TTS-1 en el mundo virtual El modelo representa una solución de conversión de texto a voz (TTS) autorregresiva de vanguardia basada en Transformer, diseñada para producir Voz de alta calidad y en tiempo real en varios idiomas.Ofrece audio con latencia excepcionalmente baja con una resolución superior de 48 kHz. Además, incorpora capacidades avanzadas para control emocional minucioso, lo que la hace versátil tanto para aplicaciones en dispositivos como para aplicaciones basadas en la nube.
⚙️ Especificaciones técnicas
- • Arquitectura: Modelo autorregresivo basado en transformadores
- • Recuento de parámetros: 1.600 millones (TTS-1)
- • Frecuencia de muestreo: Audio de alta resolución de hasta 48 kHz
- • Estado latente: Optimizado para baja latenciaaplicaciones en tiempo real
- • Idiomas: Soportes 11 idiomas con sólidas capacidades multilingües
- • Control emocional: Expresividad avanzada de grano fino
🌟 Características principales
- • Audio de alta fidelidad: Generación de voz a 48 kHz con técnicas de superresolución para un audio nítido.
- • Control emocional matizado: Permite realizar ajustes emocionales y prosódicos muy precisos, lo que posibilita una producción del habla con gran riqueza de matices.
- • Calidad multilingüe uniforme: Garantiza una calidad de voz uniforme y superior en los 11 idiomas compatibles.
- • Despliegue eficiente: Arquitectura optimizada para una integración perfecta tanto en entornos de nube como de borde (en el dispositivo).
- • Entrenamiento sólido: Desarrollado a partir de un vasto conjunto de datos de entrenamiento de más de 300.000 horas de habla en inglés y chino, lo que mejora la naturalidad y la solidez.
🚀 Pruebas de rendimiento y visuales
Inworld TTS-1 supera consistentemente a muchos modelos de la competencia, particularmente en áreas de Calidad de voz multilingüe, rango emocional y latencia ultrabaja., consolidándola como líder en aplicaciones exigentes en tiempo real.
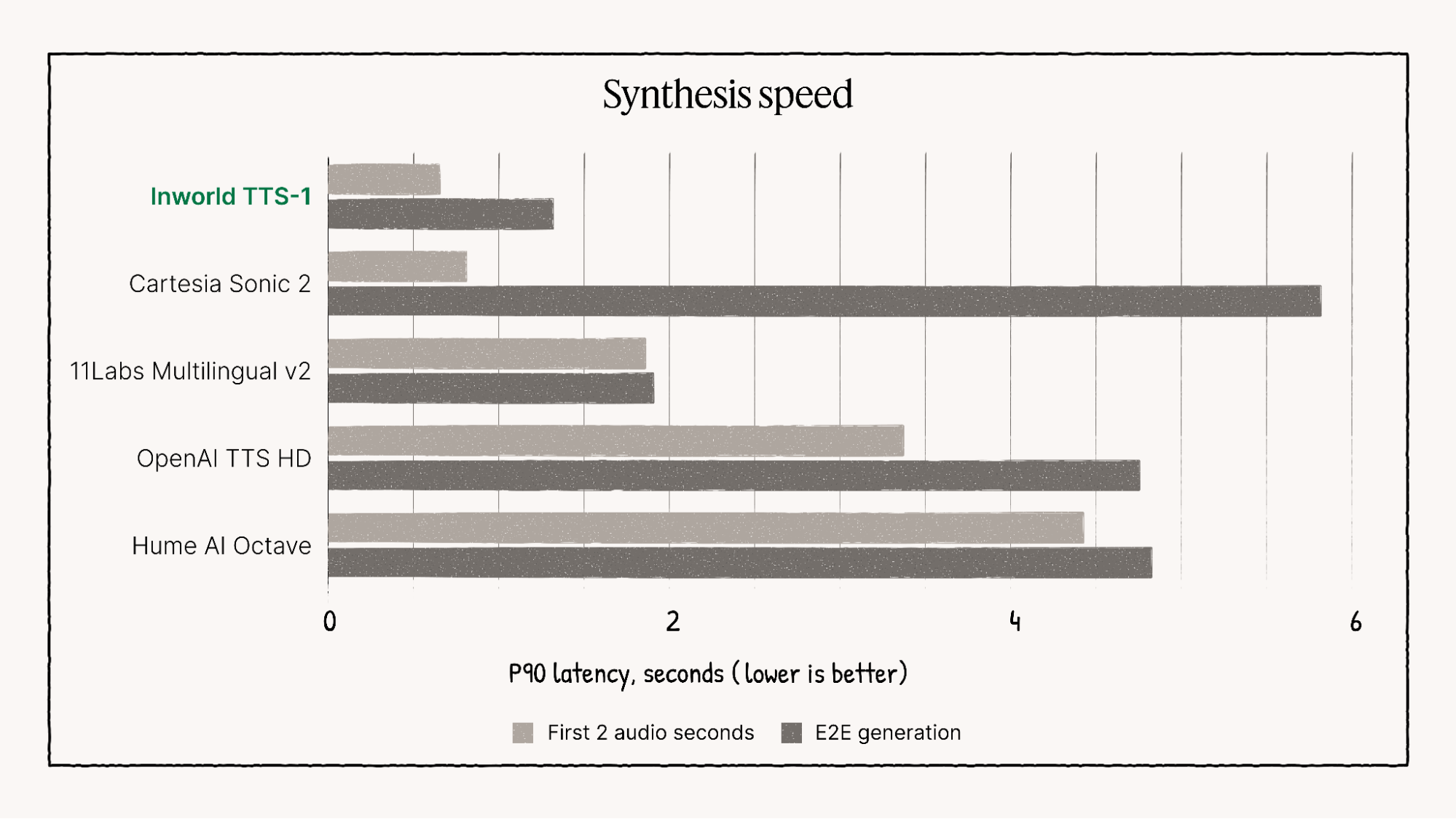
Representación visual de las características de rendimiento de Inworld TTS-1.
💲 Precios de API
$5.25 por cada millón de caracteres
(aproximadamente $0.00525 por minuto de habla generada)
💡 Casos de uso versátiles
- • Asistentes de voz en tiempo real e IA conversacional: Ideal para aplicaciones que requieren un habla natural y de baja latencia para una interacción fluida.
- • Creación de contenido multimedia: Mejora tus audiolibros, podcasts y narraciones de vídeo con locuciones multilingües de alta calidad.
- • Sistemas de respuesta de voz interactiva (IVR): Incorpore matices emocionales a los sistemas IVR para aumentar significativamente la participación del usuario.
- • Aplicaciones de síntesis de voz en el dispositivo: Implemente de forma eficiente la síntesis de voz de alta calidad en sistemas móviles y embebidos con recursos limitados.
- • Herramientas educativas y de accesibilidad: Proporcionar síntesis de voz multilingüe de alta calidad para enriquecer las experiencias de aprendizaje y accesibilidad.
🆚 Inworld TTS-1 vs. Principales competidores
vs. Google WaveNet: Inworld TTS-1 destaca por su Menor latencia y síntesis en tiempo real superior., lo que lo hace ideal para aplicaciones interactivas. WaveNet ofrece un habla muy natural y expresiva, pero generalmente a un costo computacional más elevado.
vs. 11LABS Multilingüe V2: Inworld TTS-1 proporciona matices emocionales más sutiles e incluso menor latencia. Para escenarios de interacción en vivo. Si bien 11LABS ofrece sólidas capacidades multilingües con una interfaz más sencilla, Inworld TTS-1 es la opción preferida para una salida expresiva y de alta calidad.
vs. OpenAI TTS-1-HD: OpenAI TTS-1-HD ofrece audio de ultra alta definición y calidad de estudio con una fidelidad excepcional, superando a menudo a Inworld en riqueza de audio. Sin embargo, esto se produce a expensas de mayor latencia y costoInworld TTS-1 ofrece una solución más rentable y versátil para implementaciones multilingües y compatibles con diversos dispositivos, perfectamente adaptada a las necesidades cotidianas en tiempo real.
💻 Ejemplo de código y documentación
Para obtener información detallada sobre el uso e integración de la API, consulte la documentación oficial:
Documentación de la API de TTS-1 en el mundo virtual (enlace externo)
❓ Preguntas frecuentes (FAQ)
Inworld TTS-1 es un modelo autorregresivo de conversión de texto a voz basado en Transformer, de última generación, diseñado para la síntesis de voz en tiempo real y de alta calidad. Ofrece audio de baja latencia a 48 kHz, admite un control emocional preciso y está optimizado para aplicaciones multilingües tanto en la nube como en dispositivos móviles.
Entre sus especificaciones clave se incluyen una arquitectura con 1600 millones de parámetros, audio de alta resolución de hasta 48 kHz y compatibilidad con 11 idiomas. Sus características principales abarcan la generación de voz de alta fidelidad, un control emocional y prosódico preciso, una implementación eficiente en la nube y en el borde, y una gran robustez gracias a un conjunto de datos de entrenamiento de más de 300 000 horas.
Inworld TTS-1 se distingue por su menor latencia y capacidades superiores en tiempo real en comparación con Google WaveNet, matices emocionales más finos y menor latencia para interacciones en vivo en comparación con 11LABS Multilingual V2, y una mejor relación costo-eficiencia y flexibilidad de dispositivos que OpenAI TTS-1-HD, que prioriza la ultra alta definición a un costo y latencia mayores.
Entre los principales casos de uso se incluyen asistentes de voz en tiempo real, creación de contenido multimedia, sistemas IVR con inteligencia emocional, síntesis de voz en dispositivos y herramientas educativas/de accesibilidad multilingües. El precio de la API es de 5,25 dólares por millón de caracteres, lo que equivale aproximadamente a 0,00525 dólares por minuto de voz.
Campo de juegos de IA

