 OpenAI - ChatGPT, Sora
OpenAI - ChatGPT, Sora Google - Gemini, Nano Banana
Google - Gemini, Nano Banana Antrópico - Claude
Antrópico - Claude xAI - Grok
xAI - Grok Búsqueda profunda
Búsqueda profunda Alibaba - Reina
Alibaba - Reina ByteDance - Lo mejor de ByteDance
ByteDance - Lo mejor de ByteDance Todos los modelos
Todos los modelos Planes empresariales
Planes empresariales Desarrollo de aplicaciones de IA
Desarrollo de aplicaciones de IA API de traducción de IA
API de traducción de IA Servicio de SEO/GEO con IA
Servicio de SEO/GEO con IA Servicio de relaciones públicas geooptimizado
Servicio de relaciones públicas geooptimizado Servicio de extracción de datos web
Servicio de extracción de datos web OpenClaw
OpenClaw Las mejores herramientas de IA
Las mejores herramientas de IA Los mejores robots de IA
Los mejores robots de IA
 Acceso
Acceso



const { OpenAI } = require('openai');
const api = new OpenAI({
baseURL: 'https://api.ai.cc/v1',
apiKey: '',
});
const main = async () => {
const result = await api.chat.completions.create({
model: 'alibaba/qwen3-vl-32b-thinking',
messages: [
{
role: 'system',
content: 'You are an AI assistant who knows everything.',
},
{
role: 'user',
content: 'Tell me, why is the sky blue?'
}
],
});
const message = result.choices[0].message.content;
console.log(`Assistant: ${message}`);
};
main();
import os
from openai import OpenAI
client = OpenAI(
base_url="https://api.ai.cc/v1",
api_key="",
)
response = client.chat.completions.create(
model="alibaba/qwen3-vl-32b-thinking",
messages=[
{
"role": "system",
"content": "You are an AI assistant who knows everything.",
},
{
"role": "user",
"content": "Tell me, why is the sky blue?"
},
],
)
message = response.choices[0].message.content
print(f"Assistant: {message}")


Detalles del producto
💡 Desbloqueando la cognición multimodal avanzada con Qwen3 VL 32B Thinking
El Qwen3 VL 32B Pensamiento Representa un innovador modelo multimodal de visión y lenguaje (VLM) diseñado específicamente para el razonamiento visual-textual complejo y el procesamiento sofisticado y extenso de cadenas de pensamiento. Su innovador modo "Solo Pensar" está meticulosamente optimizado para tareas analíticas profundas, integrando a la perfección información visual detallada con una comprensión lingüística matizada. Esta potente combinación lo convierte en la opción ideal para casos de uso que requieren una cognición multimodal sin precedentes y deducciones lógicas extensas.
🔧 Especificaciones técnicas
- ✓ Tipo de modelo: Modelo multimodal de visión y lenguaje (VLM)
- ✓ Tamaño del parámetro: 32 mil millones de parámetros
- ✓ Entrada: Datos visuales + Indicaciones de texto
- ✓ Salida: Respuestas textuales enriquecidas con razonamientos integrados y explicaciones detalladas.
- ✓ Arquitectura: Basado en Transformer con capas de atención multimodal avanzadas, altamente optimizado para tareas de razonamiento complejas.
- ✓ Modo de pensamiento: Cuenta con un sistema de razonamiento en cadena de pensamiento profundo, que permite una inferencia sofisticada y de múltiples pasos.
- ✓ Latencia: Optimizado para un procesamiento por lotes eficiente, con consideraciones de latencia adaptadas para una profundidad analítica profunda.
📊 Rendimiento excepcional en tareas complejas
El Modo "Pensando" de Qwen3 VL 32B Destaca por permitir un razonamiento secuencial, basado en cadenas de pensamiento. Esta capacidad resulta muy eficaz para desafíos complejos de múltiples pasos en diversos ámbitos.
- Programación avanzada: Desde la generación hasta la depuración de estructuras de código complejas.
- Matemáticas superiores: Resolución de problemas matemáticos complejos y demostraciones.
- Deducción lógica: Realizar inferencias lógicas sofisticadas y resolver problemas.
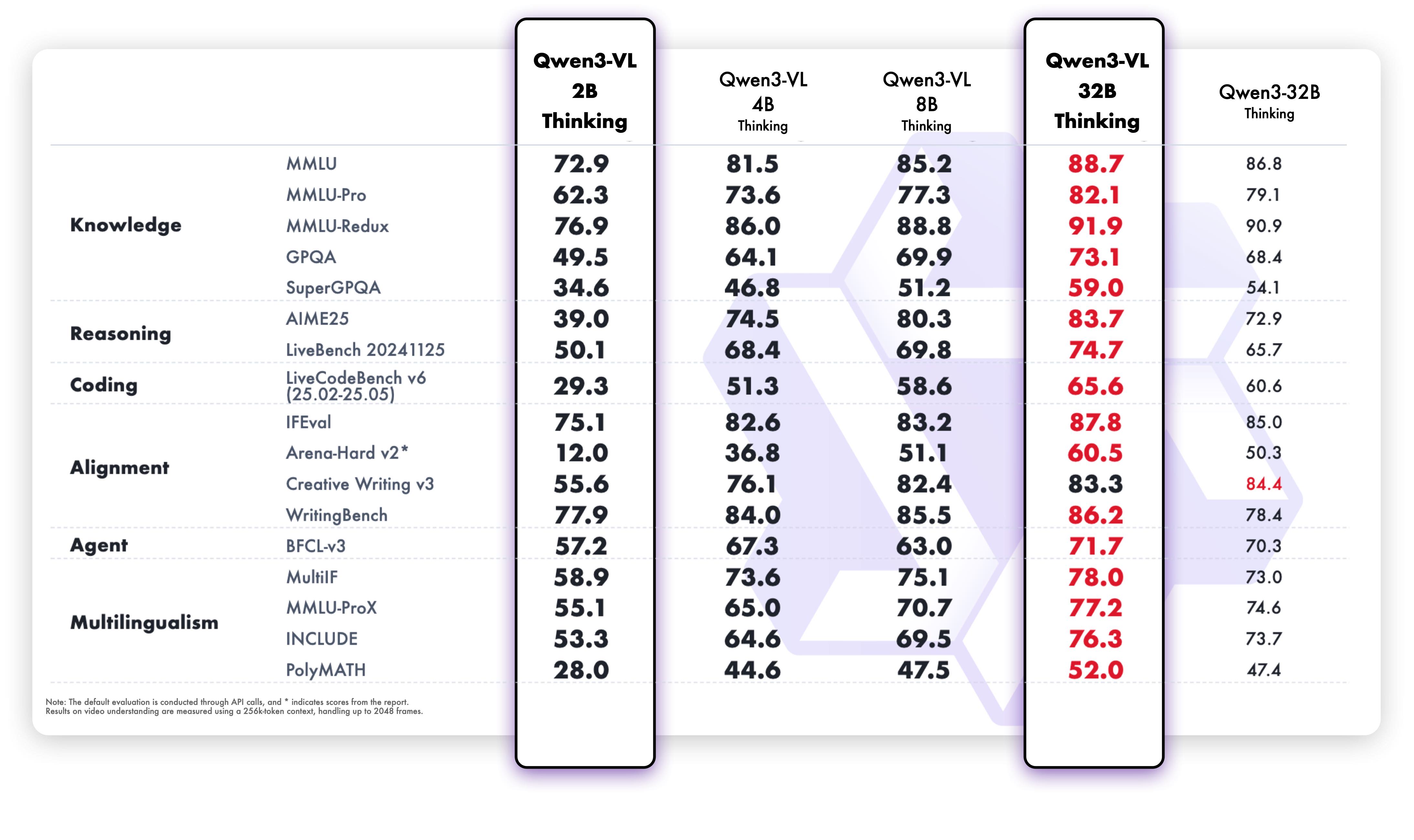
Una visión general de las capacidades de razonamiento avanzado del Qwen3 VL 32B.
★ Características y ventajas principales
- ✓ Razonamiento visual-textual superior: Capaz de interpretar imágenes complejas con una profunda comprensión del contexto.
- ✓ Cadena de pensamiento extendida: Permite realizar análisis detallados paso a paso dentro de las respuestas, algo crucial para la resolución de problemas complejos.
- ✓ Modo exclusivo "Solo para pensar": Prioriza la profundidad cognitiva y la precisión sobre la velocidad, lo que la hace perfectamente adecuada para tareas exigentes de nivel de investigación.
- ✓ Integración multimodal perfecta: Integra a la perfección las entradas visuales con el texto para ofrecer resultados completos y unificados.
- ✓ Memoria robusta y ventana de contexto: Ofrece un contexto exhaustivo, lo que garantiza una continuidad sin precedentes en diálogos complejos o documentos extensos.
- ✓ Amplia adaptabilidad: Muy adecuado para entornos de investigación científica, médica y de inteligencia artificial que requieren capacidades avanzadas de razonamiento multimodal.
💰 Precios de la API Qwen3 VL 32B
- ✓ Entrada: $0,735 / 1 millón de tokens
- ✓ Salida: 8,82 dólares / 1 millón de tokens
🔍 Diversos casos de uso prácticos
Aproveche el poder excepcional de Qwen3 VL 32B Thinking en una amplia gama de aplicaciones que requieren inteligencia multimodal avanzada:
- ✓ Asistente de investigación multimodal: Facilitar la interpretación y el razonamiento de imágenes con gran nivel de detalle dentro de contenidos académicos y científicos.
- ✓ Análisis de imágenes médicas: Mejore significativamente la información diagnóstica mediante la vinculación inteligente de escaneos visuales con consultas textuales complejas.
- ✓ Documentación legal y financiera: Analizar gráficos, figuras y contratos extensos que incorporen elementos visuales integrados.
- ✓ Tutoría interactiva con IA: Proporcionar explicaciones claras y paso a paso de conceptos visuales, complementadas con un sólido apoyo educativo basado en texto.
- ✓ Creación de contenido dinámico: Genera narrativas ricas y bien fundamentadas, basadas en imágenes, para diversos campos como el periodismo, el marketing y la narración de historias.
- ✓ Minería de datos multimodal avanzada: Extraiga información valiosa y práctica de grandes conjuntos de datos que combinen imágenes y anotaciones de texto.
💻 Ejemplo de código para la integración
(Nota: Este es un marcador de posición; reemplácelo
📜 Qwen3 VL 32B Pensamiento: Ventaja comparativa
✓ vs. GPT-4o-VL: Qwen3 VL 32B Thinking ofrece un razonamiento visual significativamente mejorado y una coherencia de pensamiento superior en cadenas largas en tareas multimodales. En cambio, GPT-4o-VL destaca por su fluidez conversacional, pero suele ofrecer contextos de razonamiento más cortos.
✓ vs. Claude 4.5 Haiku: La arquitectura de Qwen3 VL 32B está meticulosamente optimizada para la lógica compleja y secuencial dentro de las combinaciones de texto e imágenes. Esto le otorga una ventaja sobre Claude 4.5 Haiku, que, si bien destaca por su lenguaje creativo y poético, pone menos énfasis en la extensión de las cadenas de pensamiento.
✓ vs. Gemini 2.5 Pro: Ambos modelos demuestran sólidas capacidades en razonamiento multimodal y dominios STEM. Sin embargo, Qwen3 VL 32B Thinking se distingue por ventanas de contexto notablemente más grandes (hasta 256.000 tokens, ampliable) y una optimización específica para la comprensión integral de vídeos y documentos de larga duración.
❓ Preguntas frecuentes (FAQ)
P1: ¿Qué está pensando Qwen3 VL 32B?
A: Se trata de un modelo de visión y lenguaje multimodal de vanguardia (VLM, por sus siglas en inglés) diseñado específicamente para el razonamiento visual-textual avanzado y el procesamiento de cadenas de pensamiento extendidas, particularmente en su modo "Solo pensamiento" para tareas analíticas profundas.
P2: ¿Cuáles son las principales ventajas de su modo "Solo pensar"?
A: Este modo prioriza la profundidad cognitiva y la precisión analítica sobre la velocidad de procesamiento, lo que lo hace excepcionalmente adecuado para tareas exigentes de investigación que requieren razonamiento en varios pasos, como codificación compleja, matemáticas avanzadas y deducciones lógicas intrincadas.
P3: ¿Cómo apoya Qwen3 VL 32B Thinking las aplicaciones médicas?
A: Es altamente capaz en el análisis de imágenes médicas, ya que ayuda a obtener información diagnóstica al vincular eficazmente las exploraciones visuales con consultas textuales complejas y proporcionar interpretaciones matizadas y razonadas, lo que la convierte en una herramienta poderosa para los profesionales de la salud.
P4: ¿Cuál es la estructura de precios para la API Qwen3 VL 32B?
A: La API tiene un precio de $0,735 / 1 millón de tokens para su entrada y 8,82 dólares / 1 millón de tokens para la salida, diseñado para un procesamiento multimodal avanzado y rentable.
P5: ¿Cómo se compara su ventana de contexto con la de competidores como Gemini 2.5 Pro?
A: Si bien ambos se centran en el razonamiento multimodal, Qwen3 VL 32B Thinking ofrece ventanas de contexto significativamente más grandes (hasta 256.000 tokens, ampliableEsta optimización la hace superior para procesar y comprender vídeos de larga duración y documentos extensos, proporcionando una comprensión contextual más profunda y continua.
Campo de juegos de IA

