 OpenAI - ChatGPT, Sora
OpenAI - ChatGPT, Sora Google - Gemini, Nano Banana
Google - Gemini, Nano Banana Antrópico - Claude
Antrópico - Claude xAI - Grok
xAI - Grok Busca profunda
Busca profunda Alibaba - Qwen
Alibaba - Qwen ByteDance - O Melhor da ByteDance
ByteDance - O Melhor da ByteDance Todos os modelos
Todos os modelos Planos Empresariais
Planos Empresariais Desenvolvimento de aplicações de IA
Desenvolvimento de aplicações de IA API de tradução de IA
API de tradução de IA Serviço de SEO/GEO com IA
Serviço de SEO/GEO com IA Serviço de Relações Públicas Otimizado por Geolocalização
Serviço de Relações Públicas Otimizado por Geolocalização Serviço de Web Scraping
Serviço de Web Scraping OpenClaw
OpenClaw Principais ferramentas de IA
Principais ferramentas de IA Os melhores robôs de IA
Os melhores robôs de IA
 Conecte-se
Conecte-se



const { OpenAI } = require('openai');
const api = new OpenAI({
baseURL: 'https://api.ai.cc/v1',
apiKey: '',
});
const main = async () => {
const result = await api.chat.completions.create({
model: 'deepseek/deepseek-non-reasoner-v3.1-terminus',
messages: [
{
role: 'system',
content: 'You are an AI assistant who knows everything.',
},
{
role: 'user',
content: 'Tell me, why is the sky blue?'
}
],
});
const message = result.choices[0].message.content;
console.log(`Assistant: ${message}`);
};
main();
import os
from openai import OpenAI
client = OpenAI(
base_url="https://api.ai.cc/v1",
api_key="",
)
response = client.chat.completions.create(
model="deepseek/deepseek-non-reasoner-v3.1-terminus",
messages=[
{
"role": "system",
"content": "You are an AI assistant who knows everything.",
},
{
"role": "user",
"content": "Tell me, why is the sky blue?"
},
],
)
message = response.choices[0].message.content
print(f"Assistant: {message}")


Detalhes do produto
✨ DeepSeek V3.1 Terminus (Modo Não Raciocinante): IA de Alta Velocidade e Eficiente para Tarefas Diretas
O DeepSeek V3.1 Terminus modelo, especificamente em seu modo não racionalO DeepSeek V3.1 se destaca como um modelo de linguagem avançado e robusto, meticulosamente projetado para tarefas de geração rápidas, eficientes e leves. Ele foi desenvolvido para se sobressair em situações onde o raciocínio analítico profundo não é necessário, tornando-o perfeito para a geração de conteúdo simples. Como parte da série DeepSeek V3.1, oferece melhorias substanciais em estabilidade, consistência multilíngue e confiabilidade de uso da ferramenta, tornando-se a escolha ideal para fluxos de trabalho de agentes que exigem velocidade e baixo consumo de recursos.
⚙️ Especificações Técnicas
- • Família Modelo: DeepSeek V3.1 Terminus (Modo sem Raciocínio)
- • Parâmetros: 671 bilhões no total, 37 bilhões de ativos na inferência
- • Arquitetura: LLM híbrido com inferência de modo duplo (pensamento e não-pensamento)
- • Janela de contexto: Suporta até 128.000 tokens treinamento de contexto longo
- • Precisão e Eficiência: Utiliza Microescala FP8 para eficiência de memória e inferência
- • Modos: O modo sem raciocínio desativa a elaborada linha de raciocínio para respostas mais rápidas
- • Suporte linguístico: Melhoria da consistência multilíngue, particularmente em Inglês e chinês
📊 Indicadores de desempenho
- • Raciocínio (MMLU-Pro): 85,0 (ligeira melhoria)
- • Navegação Web Agencial (BrowseComp): 38,5 (ganhos significativos no uso de ferramentas em várias etapas)
- • Linha de comando (Terminal-bench): 36,7 (melhor tratamento da sequência de comandos)
- • Geração de código (LiveCodeBench): 74,9 (Altas capacidades mantidas)
- • Verificação de Engenharia de Software (SWE Verified): 68,4 (precisão de validação aprimorada)
- • Precisão do controle de qualidade (SimpleQA): 96,8 (desempenho robusto)
- • Estabilidade geral: Variância reduzida e resultados mais determinísticos para maior confiabilidade no mundo real.
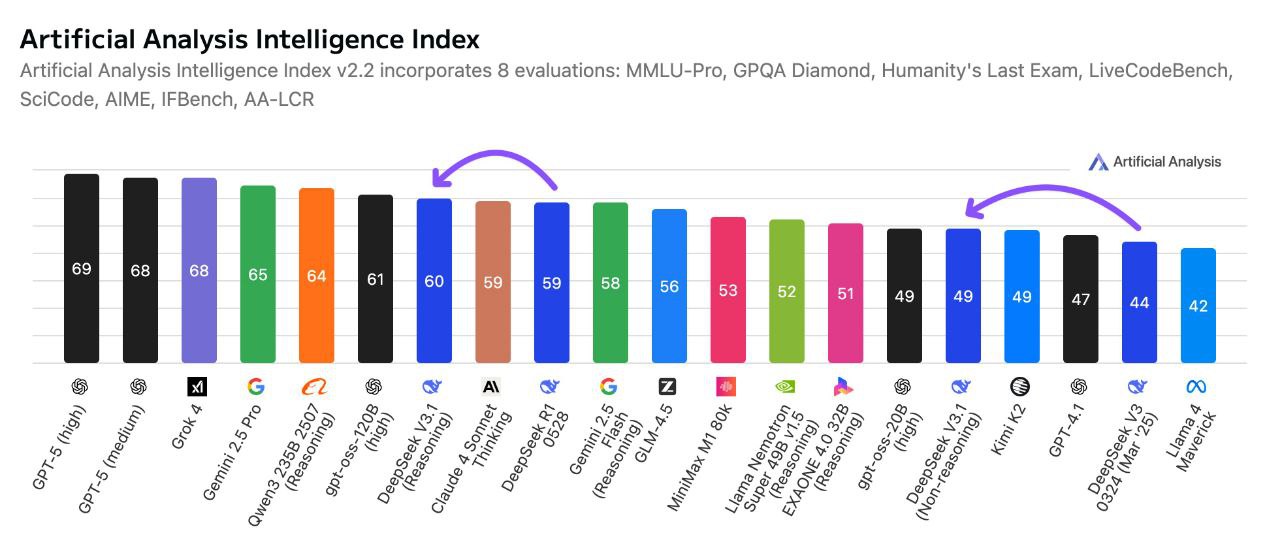
Testes de desempenho: DeepSeek V3.1 Terminus em ação
⭐ Principais características
- 🚀 Geração rápida e leve: O modo de não-pensamento priorizado garante redução do tempo de processamento e do consumo de recursosIdeal para resultados rápidos.
- 🌐 Saída multilíngue robusta: As melhorias previnem a mistura de idiomas e tokens inconsistentes, oferecendo suporte. aplicações globais.
- 🛠️ Melhoria no uso de ferramentas: Aumenta a confiabilidade nos fluxos de trabalho de invocação de ferramentas, incluindo Execução de código e cadeias de pesquisa na web.
- 📖 Contexto longo flexível: Suporta contextos massivos de até 128 mil tokens para históricos de entrada extensos.
- ✅ Resultados estáveis e consistentes: As otimizações pós-treinamento reduzem significativamente as alucinações e os artefatos de tokenização.
- 🔄 Compatível com versões anteriores: Integra-se perfeitamente aos ecossistemas de API DeepSeek existentes, sem alterações disruptivas.
- ⚡ Inferência híbrida escalável: Equilibra a capacidade de modelagem em larga escala com a implantação eficiente de parâmetros ativos.
💰 Preços da API
- • 1 milhão de tokens de entrada: $ 0,294
- • 1 milhão de tokens de saída: $ 0,441
💡 Casos de uso práticos
- 💬 Suporte ao cliente rápido: Respostas rápidas e eficientes do chatbot.
- ✍️ Geração de conteúdo multilíngue: Textos de marketing, resumos e muito mais em vários idiomas.
- 👨💻 Assistência automatizada de codificação: Execução de scripts e geração de código básico.
- 📚 Consulta à Base de Conhecimento: Busca e recuperação eficientes em documentos longos.
- ⚙️ Automação de tarefas assistida por ferramentas: Fluxos de trabalho simplificados com invocação confiável de ferramentas.
- 📄 Resumo rápido de documentos: Visões gerais rápidas sem explicações analíticas aprofundadas.
💻 Exemplo de código
🤝 Comparação com outros modelos líderes
DeepSeek V3.1 Terminus vs. GPT-4: O DeepSeek V3.1 Terminus oferece uma janela de contexto significativamente maior (até 128 mil tokens) em comparação com os 32 mil tokens do GPT-4, tornando-o superior para documentos extensos e pesquisas. É otimizado para geração mais rápida Em seu modo especializado de não raciocínio, o GPT-4 prioriza o raciocínio detalhado com maior latência.
DeepSeek V3.1 Terminus vs. GPT-5: Embora o GPT-5 se destaque em tarefas multimodais e na integração de um ecossistema mais amplo com um contexto ainda maior, o DeepSeek V3.1 Terminus enfatiza custo-benefício e licenciamento de peso livre, atraindo desenvolvedores e startups focadas em recursos de infraestrutura.
DeepSeek V3.1 Terminus vs. Claude 4.5: Claude 4.5 prioriza segurança, alinhamento e raciocínio sólido com IA constitucional robusta. DeepSeek V3.1 Terminus concentra-se em leve, produção rápidaClaude costuma ter preços por tarefa mais altos, sendo a opção preferida em setores regulamentados, enquanto DeepSeek oferece licenciamento aberto e acessibilidade para prototipagem rápida.
DeepSeek V3.1 Terminus vs. OpenAI GPT-4.5: O GPT-4.5 aprimora o raciocínio e a escrita criativa, mas compartilha uma janela de contexto de 128 mil tokens semelhante à do DeepSeek. O DeepSeek V3.1 Terminus atinge tempos de resposta mais rápidos Em seu modo não racional, o que o torna ideal para aplicações que exigem alta velocidade e não requerem uma cadeia de pensamento complexa. O GPT-4.5 oferece geração criativa mais robusta e melhor integração com o ecossistema, enquanto o DeepSeek se destaca em escalabilidade e eficiência de custos.
❓ Perguntas frequentes (FAQ)
P: O que significa "Não Raciocinante" para o DeepSeek V3.1 Terminus?
A: "Não Raciocinante" significa que este modelo é otimizado para tarefas que não exigem dedução lógica complexa, resolução de problemas em várias etapas ou pensamento analítico profundo. Ele prioriza a geração direta de texto, perguntas e respostas simples e processamento direto com máxima eficiência e velocidade.
P: Quais são as principais vantagens de usar a variante sem raciocínio?
A: As principais vantagens incluem tempos de resposta significativamente mais rápidos, custos computacionais mais baixos, maior rendimento, uso eficiente de recursos e desempenho otimizado para tarefas simples, onde as capacidades de raciocínio completas dos modelos padrão não são necessárias.
P: Qual é o tamanho da janela de contexto para o DeepSeek V3.1 Terminus Non-Reasoning?
A: O DeepSeek V3.1 Terminus Non-Reasoning apresenta um impressionante janela de contexto de token de 128K, permitindo-lhe processar documentos extensos e manter o contexto de forma eficaz para tarefas simples de geração e processamento de texto.
P: Para que tipos de tarefas este modelo é mais adequado?
A: É ideal para geração de texto simples, perguntas e respostas básicas, sumarização de conteúdo, classificação de texto, traduções diretas, preenchimento de modelos, extração de dados e qualquer aplicação que exija processamento de texto rápido e confiável, sem raciocínio complexo.
P: Como sua velocidade se compara aos modelos de raciocínio padrão?
A: A variante sem raciocínio normalmente responde 2 a 4 vezes mais rápido do que os modelos de raciocínio padrão para tarefas simples, oferecendo latência significativamente menor e maior taxa de transferência para aplicações de processamento de texto de alto volume.
Playground de IA

