 OpenAI - ChatGPT, Sora
OpenAI - ChatGPT, Sora Google - Gemini, Nano Banana
Google - Gemini, Nano Banana Антропический - Клод
Антропический - Клод xAI - Grok
xAI - Grok Глубокий поиск
Глубокий поиск Alibaba - Qwen
Alibaba - Qwen ByteDance - Лучшее от ByteDance
ByteDance - Лучшее от ByteDance Все модели
Все модели Планы предприятия
Планы предприятия Разработка приложений на основе искусственного интеллекта
Разработка приложений на основе искусственного интеллекта API для перевода с помощью ИИ
API для перевода с помощью ИИ Услуги SEO/ГЕ с использованием ИИ
Услуги SEO/ГЕ с использованием ИИ Географически оптимизированная PR-служба
Географически оптимизированная PR-служба Сервис веб-скрейпинга
Сервис веб-скрейпинга OpenClaw
OpenClaw Лучшие инструменты ИИ
Лучшие инструменты ИИ Лучшие роботы с искусственным интеллектом
Лучшие роботы с искусственным интеллектом
 Авторизоваться
Авторизоваться



const axios = require('axios').default;
const api = axios.create({
baseURL: 'https://api.ai.cc/v1',
headers: { Authorization: 'Bearer ' },
});
const main = async () => {
const response = await api.post('/tts', {
model: 'inworld/tts-1',
text: 'OpenAI TTS are fast and powerful language models. Use it to convert text to natural sounding spoken text.',
voice: 'coral',
});
console.log('Audio URL:', response.data.audio.url);
console.log('Characters:', response.data.usage.characters);
};
main();
import requests
def main():
url = "https://api.ai.cc/v1/tts"
headers = {
"Authorization": "Bearer ",
}
payload = {
"model": "inworld/tts-1",
"text": "OpenAI TTS are fast and powerful language models. Use it to convert text to natural sounding spoken text.",
"voice": "coral"
}
response = requests.post(url, headers=headers, json=payload)
data = response.json()
print("Audio URL:", data["audio"]["url"])
print("Characters:", data["usage"]["characters"])
main()


Подробная информация о товаре
✨ API Inworld TTS-1: Расширенный синтез речи в реальном времени
Он Inworld TTS-1 Эта модель представляет собой передовое авторегрессивное решение для преобразования текста в речь (TTS) на основе трансформеров, разработанное для создания высококачественная речь в режиме реального времени на нескольких языкахОн обеспечивает передачу звука с исключительно низкая задержка с превосходным разрешением 48 кГц. Кроме того, он включает в себя расширенные возможности для тонкий эмоциональный контрольчто делает его универсальным как для приложений, работающих на устройствах, так и для облачных приложений.
⚙️ Технические характеристики
- • Архитектура: Авторегрессионная модель на основе трансформатора
- • Количество параметров: 1,6 миллиарда (TTS-1)
- • Частота дискретизации: Аудио высокого разрешения до 48 кГц
- • Задержка: Оптимизировано для низкая задержкаприложения реального времени
- • Языки: Поддерживает 11 языков с расширенными многоязычными возможностями
- • Контроль эмоций: Высокая степень детализации выразительности
🌟 Основные характеристики
- • Высококачественный звук: Обеспечивает генерацию речи с частотой 48 кГц с использованием технологий сверхвысокого разрешения для кристально чистого звука.
- • Тонкий эмоциональный контроль: Позволяет вносить тонкие эмоциональные и просодические корректировки, обеспечивая высокоточную передачу речи.
- • Стабильное многоязычное качество: Обеспечивает стабильно высокое качество речи на всех 11 поддерживаемых языках.
- • Эффективное развертывание: Оптимизированная архитектура для бесшовной интеграции как в облачные, так и в периферийные (на устройствах) среды.
- • Надежная подготовка: Создан на основе обширного обучающего набора данных, содержащего более 300 000 часов английской и китайской речи, что повышает естественность и надежность.
🚀 Тесты производительности и визуальной эффективности
Inworld TTS-1 неизменно превосходит многие конкурирующие модели, особенно в таких областях, как Многоязычное качество речи, эмоциональный диапазон и сверхнизкая задержкачто позволило ей утвердиться в качестве лидера в области требовательных приложений реального времени.
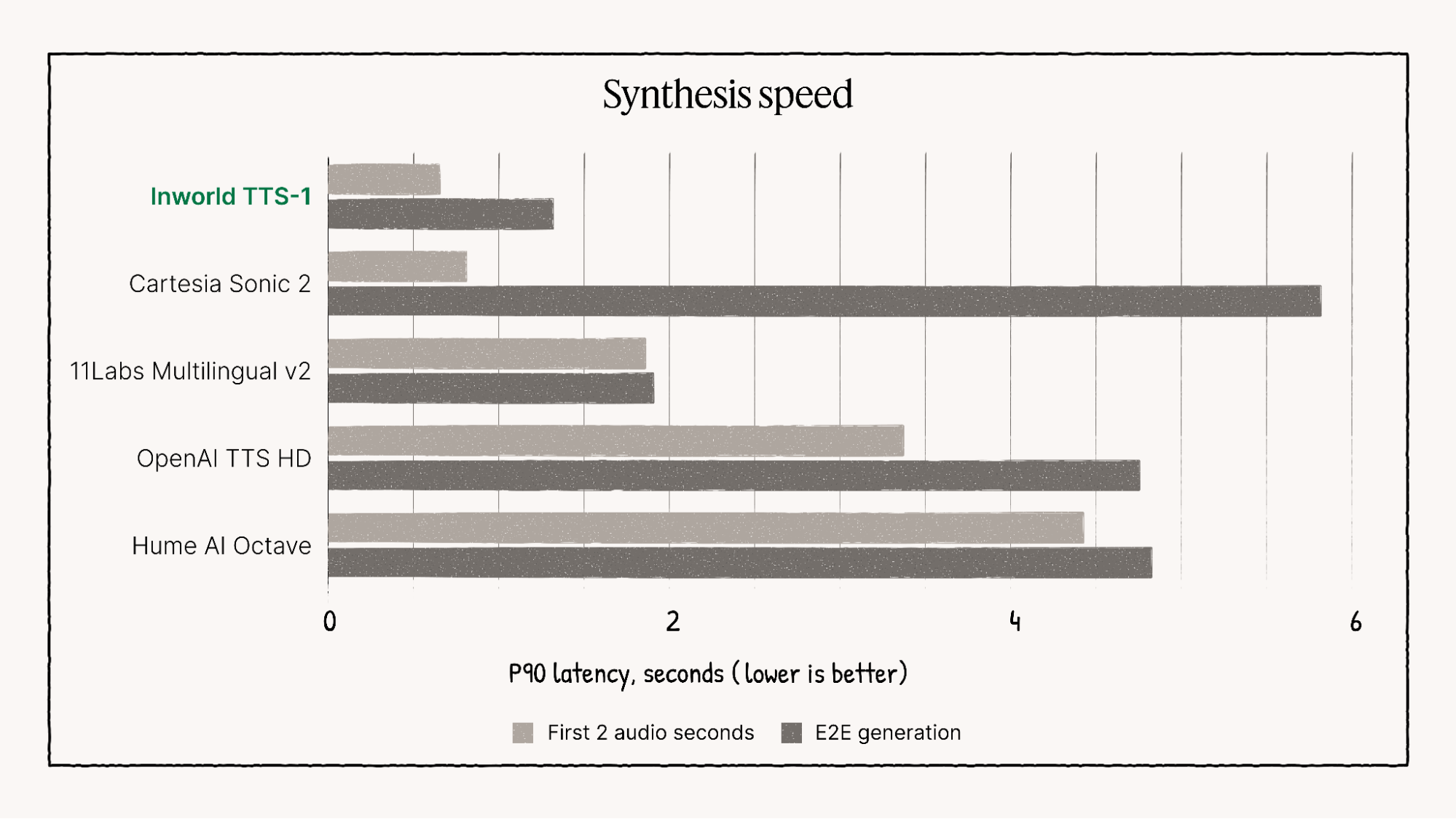
Визуальное представление характеристик производительности Inworld TTS-1.
💲 Цены на API
5,25 долларов за 1 миллион символов
(примерно 0,00525 долларов США (за минуту сгенерированной речи)
💡 Универсальные варианты использования
- • Голосовые помощники в реальном времени и разговорный искусственный интеллект: Идеально подходит для приложений, требующих естественной речи с низкой задержкой для бесперебойного взаимодействия.
- • Создание мультимедийного контента: Улучшите качество озвучивания аудиокниг, подкастов и видеороликов с помощью высококачественной многоязычной озвучки.
- • Системы интерактивного голосового ответа (IVR): Внедрение эмоциональных нюансов в системы интерактивного голосового ответа (IVR) позволит значительно повысить вовлеченность пользователей.
- • Приложения для преобразования текста в речь, встроенные в устройство: Эффективное развертывание высококачественного синтеза речи на мобильных и встроенных системах при ограниченных ресурсах.
- • Образовательные инструменты и средства обеспечения доступности: Обеспечьте высококачественный многоязычный синтез речи для улучшения процесса обучения и повышения доступности.
🆚 Внутриигровой TTS-1 против ведущих конкурентов
против Google WaveNet: Inworld TTS-1 превосходит все ожидания благодаря своим функциям. более низкая задержка и превосходный синтез в реальном времениЭто делает его идеальным для интерактивных приложений. WaveNet обеспечивает очень естественную и выразительную речь, но, как правило, с более высокими вычислительными затратами.
vs. 11LABS Multilingual V2: Внутриигровой TTS-1 предоставляет более тонкие эмоциональные нюансы и еще меньшая задержка для сценариев взаимодействия в реальном времени. Хотя 11LABS предлагает широкие многоязычные возможности с более простым интерфейсом, Inworld TTS-1 является предпочтительным выбором для высококачественного и выразительного вывода.
против OpenAI TTS-1-HD: OpenAI TTS-1-HD обеспечивает сверхвысокое разрешение звука студийного качества с исключительной точностью воспроизведения, часто превосходя Inworld по насыщенности звучания. Однако это достигается за счет снижения качества звука. более высокая задержка и стоимостьInworld TTS-1 предлагает более экономичное и универсальное решение для многоязычных и гибких в отношении устройств развертываний, идеально подходящее для повседневных задач в режиме реального времени.
💻 Пример кода и документация
Для получения подробной информации об использовании и интеграции API обратитесь к официальной документации:
Документация по API TTS-1 в виртуальном мире (внешняя ссылка)
❓ Часто задаваемые вопросы (FAQ)
Inworld TTS-1 — это современная авторегрессивная модель преобразования текста в речь на основе трансформеров, разработанная для высококачественного синтеза речи в реальном времени. Она обеспечивает низкую задержку звука на частоте 48 кГц, поддерживает точную настройку эмоционального восприятия и оптимизирована для многоязычных приложений как в облачной среде, так и на устройствах.
Ключевые характеристики включают архитектуру с 1,6 миллиардами параметров, аудио высокого разрешения до 48 кГц и поддержку 11 языков. Основные особенности включают высококачественную генерацию речи, тонкое управление эмоциональностью и просодией, эффективное развертывание в облаке/на периферии сети и надежность, обеспечиваемую обучающим набором данных объемом более 300 000 часов.
Inworld TTS-1 отличается меньшей задержкой и превосходными возможностями обработки в реальном времени по сравнению с Google WaveNet, более тонкой передачей эмоциональных нюансов и меньшей задержкой для взаимодействия в реальном времени по сравнению с 11LABS Multilingual V2, а также лучшей экономичностью и гибкостью использования устройств, чем OpenAI TTS-1-HD, который отдает приоритет сверхвысокой четкости при более высокой стоимости и задержке.
Основные области применения включают голосовых помощников в реальном времени, создание мультимедийного контента, эмоционально-ориентированные интерактивные голосовые системы (IVR), синтез речи на устройствах и многоязычные образовательные/инструменты для обеспечения доступности. Стоимость API составляет 5,25 долларов США за 1 миллион символов, что примерно соответствует 0,00525 доллара США за минуту речи.
Игровая площадка для ИИ

