 OpenAI - ChatGPT, Sora
OpenAI - ChatGPT, Sora Google - Gemini, Nano Banana
Google - Gemini, Nano Banana Antrópico - Claude
Antrópico - Claude xAI - Grok
xAI - Grok Búsqueda profunda
Búsqueda profunda Alibaba - Reina
Alibaba - Reina ByteDance - Lo mejor de ByteDance
ByteDance - Lo mejor de ByteDance Todos los modelos
Todos los modelos Planes empresariales
Planes empresariales Desarrollo de aplicaciones de IA
Desarrollo de aplicaciones de IA API de traducción de IA
API de traducción de IA Servicio de SEO/GEO con IA
Servicio de SEO/GEO con IA Servicio de relaciones públicas geooptimizado
Servicio de relaciones públicas geooptimizado Servicio de extracción de datos web
Servicio de extracción de datos web OpenClaw
OpenClaw Las mejores herramientas de IA
Las mejores herramientas de IA Los mejores robots de IA
Los mejores robots de IA
 Acceso
Acceso












Tutorial de Gemma 4: Guía completa para integrar el modelo de IA multimodal de código abierto más potente de Google + integración de API en 2026

Gemma 4: Guía completa de las herramientas más potentes de Google Código abierto IA multimodal
Google DeepMind acaba de lanzar Gemma 4 — la familia de modelos multimodales de código abierto más capaz hasta la fecha. Lanzada el 2 de abril de 2026 bajo un sistema totalmente permisivo. Licencia Apache 2.0Gemma 4 ofrece capacidades de vanguardia (desarrolladas a partir de la misma investigación que Gemini 3) para portátiles, teléfonos, Raspberry Pi y GPU de gama alta. Este tutorial práctico lo abarca todo: variantes del modelo, pruebas de rendimiento, código real e integración de API.
Variantes del modelo: Todos los escenarios de despliegue
La familia Gemma 4 incluye cuatro tamaños optimizados. Todos los modelos admiten entradas multimodales y destacan en flujos de trabajo con agentes, llamadas a funciones nativas, salida JSON estructurada y razonamiento de contexto extenso.
| Variante del modelo | Parámetros | Ferretería Target | Ventana de contexto | Puntos fuertes clave |
|---|---|---|---|---|
| Gemma 4 E2B | ~2B | Dispositivos móviles / de borde | 128K | Latencia ultrabaja, en el dispositivo |
| Gema 4 E4B | ~4B | Teléfonos / Raspberry Pi | 128K | Multimodal + audio nativo |
| Gemma 4 26B A4B | 26B (Ministerio de Educación) | Estaciones de trabajo / GPU | 256K | Velocidad y calidad equilibradas |
| Gemma 4 31B | 31B | Servidores de alta gama | 256K | Máxima capacidad de razonamiento |
// Arquitectura de IA multimodal: Gemma 4 procesa sin problemas entradas de texto, imágenes, audio y vídeo.
¿Por qué destaca Gemma 4?: Puntos de referencia
(Modelo 31B)
Diamante
Banco
Plurilingüe
- Nativo multimodal: Comprenda imágenes, clips de audio y video junto con texto en un solo modelo.
- Uso de agentes y herramientas: Llamada a funciones integrada e integración con herramientas: perfecto para agentes autónomos.
- Rendimiento en el dispositivo: Funciona sin conexión a internet con una latencia prácticamente nula en hardware de consumo.
- Contexto extenso: Hasta 256.000 tokens para documentos de gran tamaño o bases de código completas.
- Libertad comercial: La licencia Apache 2.0 elimina todas las restricciones anteriores: permite su implementación en cualquier lugar.
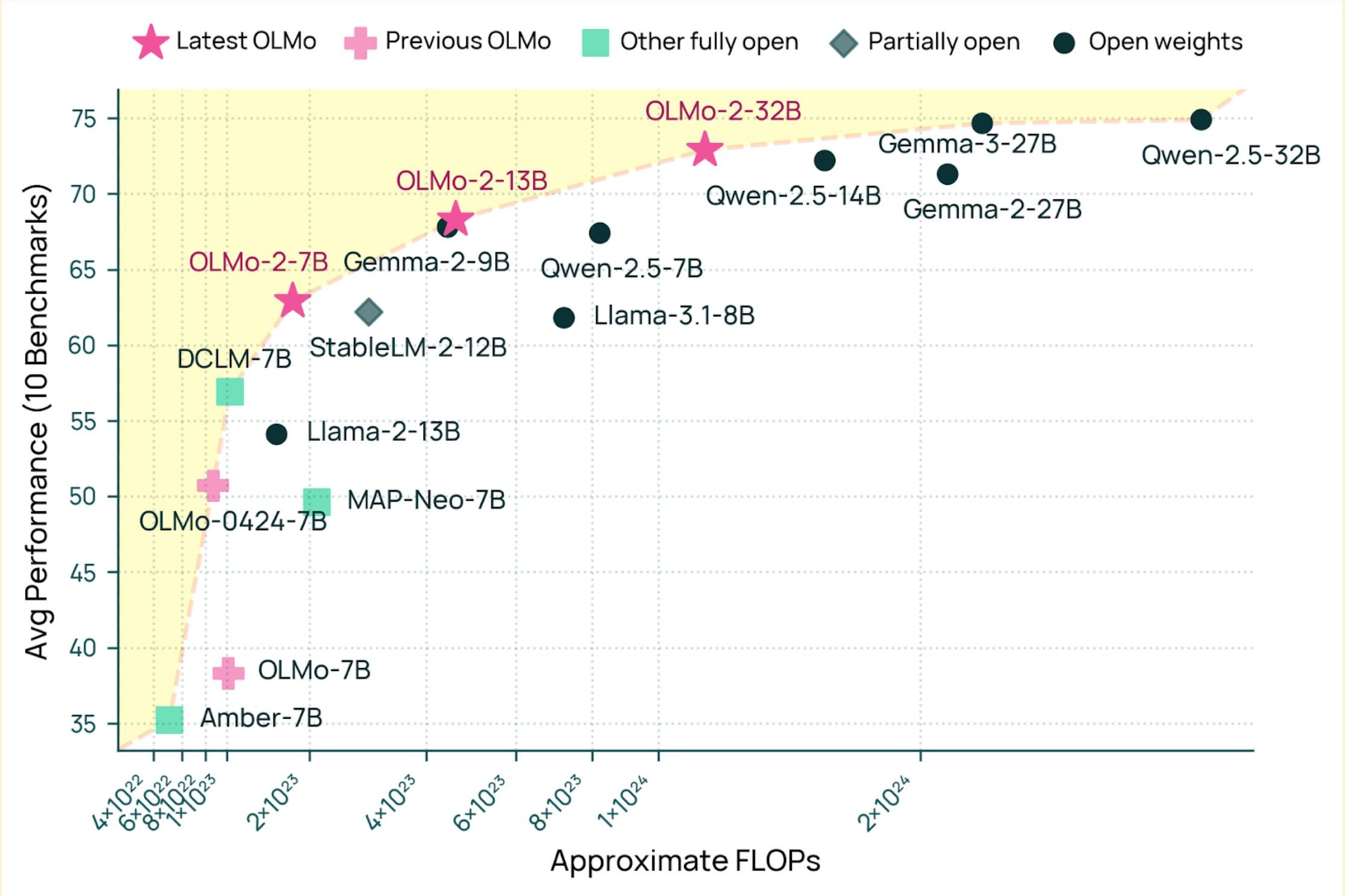
// Rendimiento de Gemma 4 frente a otros modelos abiertos: FLOPs frente al promedio de referencia
Tutorial práctico de integración de API (Python)
Tienes dos caminos principales: API Gemini alojada (más fácil, recomendado para la creación de prototipos) o despliegue local Vía Hugging Face / Ollama para total privacidad.
Opción 1: Inicio rápido de la API de Gemini
from google import genai # Obtén tu clave API gratuita en ai.google.dev client = genai.Client(api_key="YOUR_GEMINI_API_KEY") response = client.models.generate_content( model="gemma-4-31b-it", # o gemma-4-26b-a4b-it, etc. contents=[ "Analiza esta imagen y explica el gráfico en detalle.", # También puedes pasar bytes de imagen o URL aquí ] ) print(response.text)
Ejemplo multimodal: imagen + texto
respuesta = cliente.modelos.generar_contenido( modelo="gemma-4-e4b-it", contenido=["¿Qué está pasando en esta foto?", genai.tipos.Parte.desde_imagen( genai.tipos.Imagen.desde_bytes(bytes_imagen) )] )
Opción 2: Despliegue local mediante Hugging Face
from transformers import AutoModelForCausalLM, AutoProcessor import torch model_id = "google/gemma-4-31B-it" # o variantes más pequeñas processor = AutoProcessor.from_pretrained(model_id) model = AutoModelForCausalLM.from_pretrained( model_id, torch_dtype=torch.bfloat16, device_map="auto" ) # Ejemplo de mensaje multimodal messages = [ {"role": "user", "content": [ {"type": "image", "image": "https://example.com/chart.png"}, {"type": "text", "text": "Describe las tendencias en esta visualización de datos."} ]} ] inputs = processor.apply_chat_template( messages, add_generation_prompt=True, tokenize=True, return_tensors="pt" ).to(model.device) outputs = model.generate(**inputs, max_new_tokens=512) print(processor.decode(outputs[0])) 
// Google AI Studio: la forma más rápida de crear prototipos con Gemma 4
Casos de uso comunes y ejemplos del mundo real
Herramienta nativa que permite la extracción de datos web, el análisis de datos o flujos de trabajo de automatización complejos de varios pasos.
Análisis de imágenes + voz + texto en un modelo unificado: no se requiere ningún proceso de unión de imágenes.
Ejecute potentes modelos 2B-4B directamente en dispositivos móviles o hardware IoT, sin necesidad de conexión a internet.
La ventana de contexto de 256 KB gestiona bases de conocimiento masivas, bases de código completas y documentos legales.
Preguntas frecuentes
Sí, licencia completa Apache 2.0 con pesos abiertos y uso comercial totalmente permitido. Sin restricciones.
Por supuesto. Las variantes Edge (2B/4B) se ejecutan en teléfonos; las más grandes en una sola GPU con cuantización (4 bits/8 bits).
Gemma 4 ofrece capacidades de vanguardia similares, pero con total apertura y un enfoque en la optimización en el dispositivo.
Integra Gemma 4 + más de 100 modelos de primera categoría: un solo SDK
Gestionar múltiples modelos, claves API, límites de velocidad e implementaciones consume mucho tiempo. www.ai.cc te brinda acceso con un solo clic a Gemma 4, Claude, GPT, Grok, Veo y docenas más a través de un SDK único y sencillo.