 OpenAI - ChatGPT, Sora
OpenAI - ChatGPT, Sora Google - Gemini, Nano Banana
Google - Gemini, Nano Banana Antrópico - Claude
Antrópico - Claude xAI - Grok
xAI - Grok Busca profunda
Busca profunda Alibaba - Qwen
Alibaba - Qwen ByteDance - O Melhor da ByteDance
ByteDance - O Melhor da ByteDance Todos os modelos
Todos os modelos Planos Empresariais
Planos Empresariais Desenvolvimento de aplicações de IA
Desenvolvimento de aplicações de IA API de tradução de IA
API de tradução de IA Serviço de SEO/GEO com IA
Serviço de SEO/GEO com IA Serviço de Relações Públicas Otimizado por Geolocalização
Serviço de Relações Públicas Otimizado por Geolocalização Serviço de Web Scraping
Serviço de Web Scraping OpenClaw
OpenClaw Principais ferramentas de IA
Principais ferramentas de IA Os melhores robôs de IA
Os melhores robôs de IA
 Conecte-se
Conecte-se













Comparação de API de IA de 2026: OpenAI vs Anthropic Claude vs Google Gemini vs Grok

Comparação de APIs de IA para 2026:
OpenAI vs Claude
vs Gêmeos vs Grok
Em março de 2026, o cenário de APIs de IA nunca foi tão competitivo — ou tão confuso. Grok 4.1 Quebrando recordes de preço rapidamente, Gemini 3.1 Pro dominando o raciocínio de contexto longo, e Claude Opus 4.6 liderando em codificação e escritaEscolher a API certa para o seu projeto de LLM pode ser crucial para o sucesso ou fracasso do orçamento. Este guia detalha preços, benchmarks, pontos fortes e código de integração das quatro principais opções disponíveis.
%252520Top%252520Large%252520Language%252520Models_%252520A%252520Comparative%252520Analysis.png)
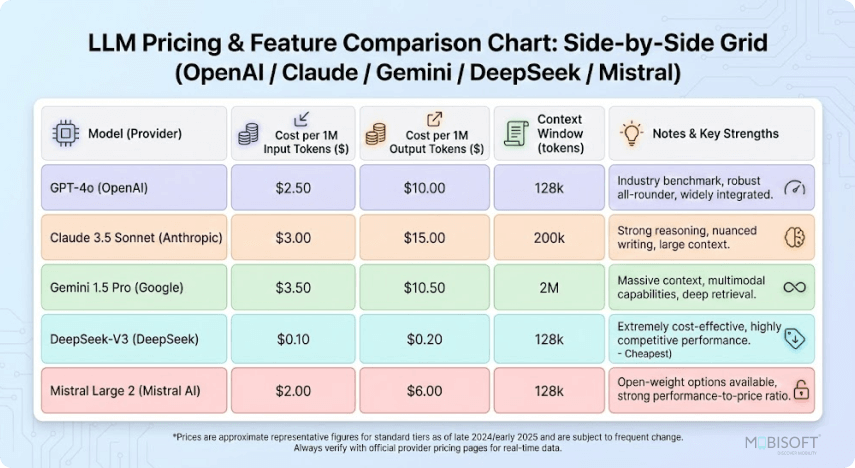
// Comparação de preços e recursos da API do LLM moderno — visão geral visual das estruturas de custos dos principais fornecedores (2026)
Preços da API de IA em 2026 (por 1 milhão de tokens)
Os preços convergiram drasticamente, mas ainda existem grandes lacunas — especialmente em grande escala. Dados mais recentes, março de 2026:
| Fornecedor | Modelo | Entrada ($/1M) | Produção ($/1M) | Janela de contexto | Ideal para | Desconto em cache |
|---|---|---|---|---|---|---|
| OpenAI | GPT-5.4 (modelo principal) | $ 2,50 | $ 15,00 | Mais de 400 mil | Empresa equilibrada | Até 90% |
| OpenAI | GPT-5.4-mini | $ 0,75 | $ 4,50 | 400 mil | Codificação e agentes | Até 90% |
| Antrópico | Claude Opus 4.6 | $ 5,00 | $ 25,00 | 200 mil (1 milhão beta) | Raciocínio profundo e escrita | Cache robusto |
| Antrópico | Soneto 4.6 de Claude | $ 3,00 | $ 15,00 | 200 mil (1 milhão beta) | Ponto ideal mais popular | Cache robusto |
| Gemini 3.1 Pro | $ 2,00 | $ 12,00 | 2M | Contexto multimodal e de longo prazo | Excelente | |
| Gemini 3 Flash | $ 0,50 | $ 3,00 | 1 milhão+ | Velocidade de alto volume | Excelente | |
| xAI Grok | Grok 4.1 Rápido | $ 0,20 | $ 0,50 | 2M | Custos sensíveis e codificação | Competitivo |
| xAI Grok | Grok 4 | $ 3,00 | $ 15,00 | 256K–2M | Em tempo real e sem censura | Competitivo |
Ponto principal: Grok 4.1 Fast é indiscutivelmente a opção de alto contexto mais barata em 2026. Claude Opus 4.6 continua com preço premium, mas oferece profundidade incomparável. Gemini oferece a melhor relação custo-benefício para trabalhos multimodais.

// Gemini vs GPT vs Claude vs Grok — Comparação da capacidade de modelos de IA (2026)
Indicadores de desempenho — março de 2026
Nenhum modelo sozinho é imbatível. Veja como eles se comparam nos principais benchmarks independentes:
| Referência | Gemini 3.1 Pro | Claude Opus 4.6 | GPT-5.4 | Grok 4.1 Rápido | Ganhador |
|---|---|---|---|---|---|
| GPQA Diamante (nível de doutorado) | 94,3% | 91,3% | 92,8% | ~88% | Gêmeos |
| ARC-AGI-2 (raciocínio inovador) | 77,1% | 68,8% | ~70% | ~16% | Gêmeos |
| SWE-Bench (codificação) | 80,6% | 80,8% | 74,9% | ~75% | Claude |
| LiveCodeBench (programação) | Forte | Líder | Forte | Forte | Claude |
| Multimodal (visão/vídeo) | Líder nativo | Bom | Forte | Texto primeiro | Gêmeos |
| Em tempo real / Sem censura | Bom | Conservador | Bom | Líder | Grok |
& escrita
contexto massivo
produção
codificação/agentes
Prós, contras e melhores casos de uso


Exemplos de código de integração — Python 2026
Exemplos mínimos e prontos para produção usando SDKs oficiais. Todos podem ser substituídos em menos de 5 minutos em uma plataforma unificada.
from openai import OpenAI client = OpenAI(api_key="your-openai-key") response = client.chat.completions.create( model="gpt-5.4", messages=[{"role": "user", "content": "Explain quantum computing in one paragraph"}], temperature=0.7 ) print(response.choices[0].message.content) 
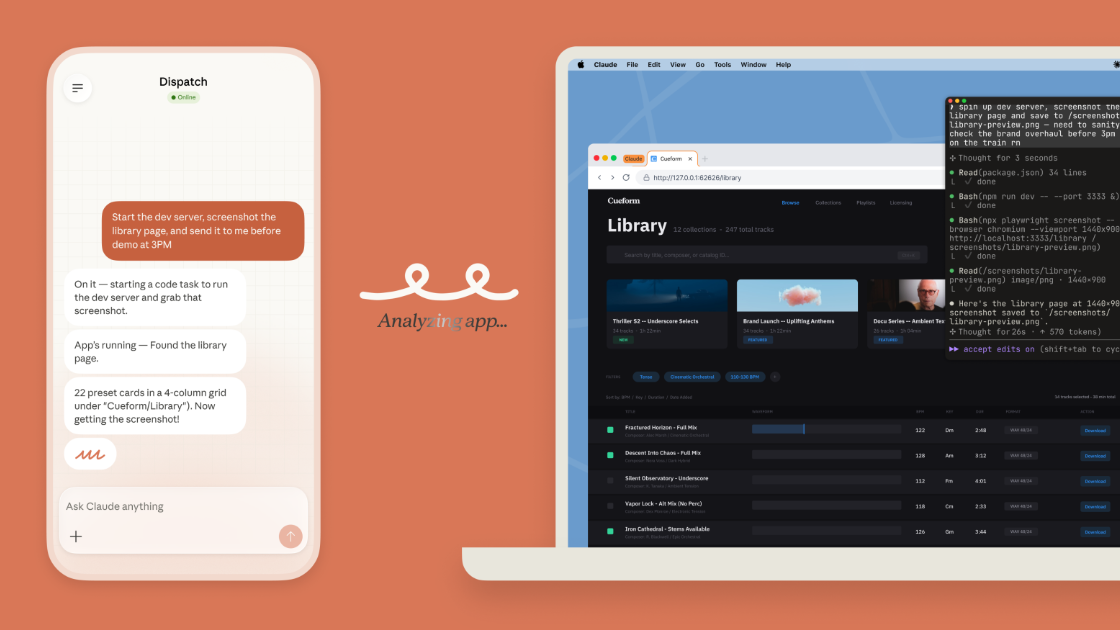
// Painel de codificação de IA mostrando o fluxo de trabalho de desenvolvimento assistido por LLM
from anthropic import Anthropic client = Anthropic(api_key="your-anthropic-key") response = client.messages.create( model="claude-4.6-sonnet", max_tokens=1024, messages=[{"role": "user", "content": "Write a professional email..."}] ) print(response.content[0].text) import google.generativeai as genai genai.configure(api_key="your-gemini-key") model = genai.GenerativeModel("gemini-3.1-pro") response = model.generate_content("Analyze this image and summarize trends", stream=False) print(response.text) from xai import Grok # SDK oficial client = Grok(api_key="your-grok-key") response = client.chat.completions.create( model="grok-4.1-fast", messages=[{"role": "user", "content": "Últimas tendências em agentes de IA"}], temperature=0.8 ) print(response.choices[0].message.content) Uma dica: Use LangChain ou LlamaIndex para abstrair completamente esses elementos — e então troque de modelo com uma única linha de código.
Dicas de Otimização de Custos para 2026
- Usar armazenamento em cache — todos os quatro fornecedores agora oferecem amplo suporte a essa funcionalidade, com economia de até 90% em contextos repetidos.
- Direcione tarefas simples para modelos mais baratos: Grok 4.1 Rápido ou Flash Gêmeo Para solicitações de alto volume.
- Usar API em lote Onde disponível — economia de mais de 50% em cargas de trabalho que não exigem tempo real.
- Monitore o uso de tokens em tempo real — pequenas e rápidas alterações de engenharia podem reduzir os custos em 30 a 70%.

// Felix — painel de desenvolvimento de IA com múltiplos back-ends para monitoramento de gastos e roteamento entre provedores de LLM
Pare de ficar fazendo malabarismos com APIs.
Comece a construir mais rápido.
Gerenciar quatro SDKs, chaves, limites de taxa e painéis de faturamento diferentes é um processo trabalhoso. Equipes inteligentes consolidam tudo em uma única plataforma com uma única chave, um único painel e acesso instantâneo a todos os principais modelos.