 OpenAI - ChatGPT, Sora
OpenAI - ChatGPT, Sora Google - Gemini, Nano Banana
Google - Gemini, Nano Banana Antrópico - Claude
Antrópico - Claude xAI - Grok
xAI - Grok Busca profunda
Busca profunda Alibaba - Qwen
Alibaba - Qwen ByteDance - O Melhor da ByteDance
ByteDance - O Melhor da ByteDance Todos os modelos
Todos os modelos Planos Empresariais
Planos Empresariais Desenvolvimento de aplicações de IA
Desenvolvimento de aplicações de IA API de tradução de IA
API de tradução de IA Serviço de SEO/GEO com IA
Serviço de SEO/GEO com IA Serviço de Relações Públicas Otimizado por Geolocalização
Serviço de Relações Públicas Otimizado por Geolocalização Serviço de Web Scraping
Serviço de Web Scraping OpenClaw
OpenClaw Principais ferramentas de IA
Principais ferramentas de IA Os melhores robôs de IA
Os melhores robôs de IA
 Conecte-se
Conecte-se
Isto não é um
vídeo gerador.
É um modelo mundial.
Demis Hassabis não veio ao Google I/O 2026 para anunciar um recurso. Ele veio para anunciar uma nova tipo de IA — um sistema que não apenas processa entradas e produz saídas, mas constrói uma compreensão interna da realidade tão profunda que permite simular o que deve acontecer em seguida. Eis o que o Gemini Omni realmente é, o que faz hoje e como se compara a todos os seus concorrentes — sem exageros.
Atualmente, todos os principais laboratórios de IA possuem um gerador de vídeos. Runway, Kling, Pika, Veo — todos seguem basicamente o mesmo modelo: escreva uma descrição, clique em gerar, espere e obtenha um clipe. Se não gostar, escreva uma nova descrição e tente novamente.
O Gemini Omni funciona de forma diferente. E essa diferença é mais significativa do que a maioria das reportagens do Google I/O 2026 mostrou. Essa é uma afirmação ousada — por isso, este artigo explica exatamente o que é, o que faz atualmente, como se compara a todos os seus principais concorrentes, como acessá-lo agora mesmo e para onde está realmente caminhando.

O que é Gemini Omni?
Gêmeos Omni é a nova família de modelos de IA multimodal do Google DeepMind, anunciada em 19 de maio de 2026. Sua característica principal é combinar duas coisas que antes existiam em sistemas separados: Raciocínio linguístico do Gemini e modelos de mídia generativa do Google. Demis Hassabis disse que ele combina Gemini com Veo, Nano Banana e Genie — descrevendo-o como "nosso novo modelo que pode criar qualquer coisa a partir de qualquer entrada".
Em termos simples: forneça uma foto, uma gravação de voz, um vídeo existente, uma descrição em texto ou qualquer combinação — e ele produzirá um vídeo. Depois, você continua interagindo com ele para refinar o resultado. A primeira versão disponível é Gemini Omni FlashUma versão mais completa da Gemini Omni Pro está em desenvolvimento para publicidade profissional e produção de vídeo.
O Google posiciona o Omni como um modelo do mundo real, e não como um gerador de vídeos padrão — projetado para entender ambientes físicos, prever causa e efeito e processar texto, áudio, imagens e vídeo em conjunto. Diferentemente do Sora, Runway ou Veo, que geram principalmente vídeos a partir de instruções de texto, o Omni busca simular o comportamento do mundo real com mais precisão.
Quando um objeto cai, ele cai. corretamenteQuando dois materiais colidem, a interação reflete a física real — não uma aproximação baseada em padrões de como essas interações se parecem em vídeos de treinamento.
A ressalva honesta, feita pelo próprio Google: atualizações mais substanciais do Omni "chegarão ainda este ano", o que significa que o que foi lançado é uma variante inicial e rápida — não o modelo completo do mundo que a retórica da Inteligência Artificial Geral (IAG) implica. Os recursos de física e compreensão do mundo serão significativamente aprimorados em versões posteriores.
Principais características de Gemini Omni Flash.
A maioria das ferramentas de vídeo com IA aceita um comando de texto. Algumas aceitam uma imagem de referência em conjunto. O Gemini Omni aceita todos os seguintes — simultaneamente, em um único comando:
- Texto — descrições, roteiros, instruções
- Imagens — fotos de produtos, referências de personagens, guias de estilo
- Áudio — gravações de voz, faixas musicais, som ambiente
- Vídeo existente — trechos para remixar, estender ou transformar
Em vez de combinar as entradas, o modelo raciocina sobre elas para produzir uma única saída — e então aceita alterações adicionais por meio de conversa. Carregue uma foto do produto, cole um slogan da marca, grave uma mensagem de voz descrevendo o clima, e o Omni sintetiza um único vídeo coerente a partir dos três elementos. Sem etapas de processamento separadas. Sem montagem manual.
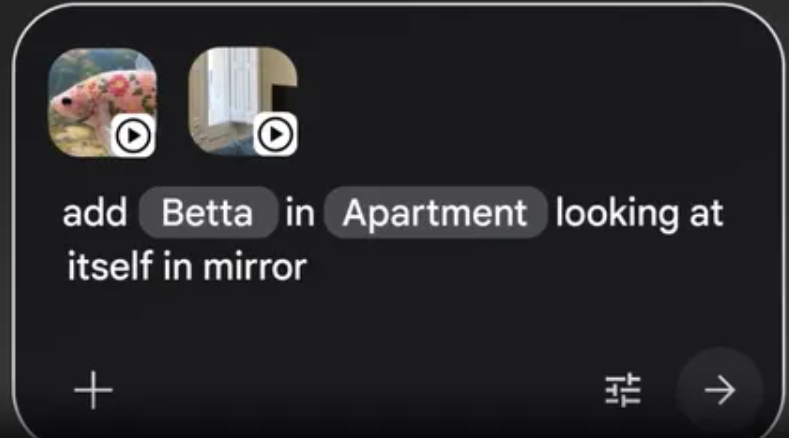
Essa é a funcionalidade mais diferenciada do Omni. Cada instrução "se baseia na anterior", e as instruções passadas persistem entre as etapas, de modo que o vídeo evolui de forma coerente à medida que você interage. Em vez de linhas do tempo e camadas clássicas, você define o que deve ser alterado:

Isso é categoricamente diferente de simplesmente reiniciar um gerador de vídeos. Veja o exemplo do próprio Google: "Quando a pessoa toca no espelho, faça com que ele ondula lindamente como um líquido, e o braço da pessoa se transforme em material espelhado refletor." — um nível de instrução específica para cada cena, levando em consideração a física do fenômeno, que exigiria edição manual quadro a quadro em qualquer ferramenta tradicional.
Hassabis apresentou o Omni exibindo um vídeo de animação em massinha que explicava o dobramento de proteínas — transformando ciência complexa em recursos visuais palpáveis. O vídeo manteve a coerência física: os materiais se comportavam como massinha, o movimento seguia a lógica da animação stop-motion e a ciência era representada com precisão. Esta é a expressão prática da abordagem de modelo-mundo: o modelo compreende por que As coisas se movem, não apenas o que Movimentos semelhantes são observados nos dados de treinamento.

O Google está adotando uma abordagem cautelosa, garantindo que cada vídeo gerado contenha um Marca d'água digital SynthID para autenticidade — de forma automática e invisível, em todas as saídas. É detectável pelas ferramentas do Google e, após o I/O 2026, também pela OpenAI, Kakao e Eleven Labs, que adotaram o padrão.
- limite de 10 segundos — O Google afirma que se trata de uma decisão de implementação, e não de uma limitação do modelo.
- Sem edição de áudio — A substituição de voz e a modificação de áudio dentro dos clipes são deliberadamente retidas até a revisão.
- API ainda não está disponível. — O acesso para desenvolvedores/empresas estará disponível "nas próximas semanas", a partir de 19 de maio.
- Restrições regionais e de idade — Requer maiores de 18 anos e está disponível nos mercados onde o aplicativo Gemini opera.
Gemini Omni vs. Veo 3.1 — Qual é a diferença?
Essa é a fonte de confusão mais comum. Veo é um modelo dedicado à geração de vídeo com raciocínio limitado. Omni é um modelo de raciocínio que por acaso gera vídeo. — interpreta instruções complexas, edita entre turnos e aceita tipos de entrada mais ricos.
| Gemini Omni Flash | Vejo 3.1 | |
|---|---|---|
| Tipos de entrada | Texto + imagem + áudio + vídeo | Texto + imagem |
| Edição conversacional | ✓ Sim | ✕ Não |
| Física / simulação mundial | ✓ Sim | Parcial |
| Comprimento máximo do clipe | 10s (atual) | ~8s |
| Acesso à API | Próximas semanas | ✓ Agora |
| Ideal para | Trabalho complexo e iterativo | de geração única de alta qualidade |
| Acesso gratuito | Vídeos curtos do YouTube | Aplicativo Gemini (aproximadamente 5 a 10 vezes por dia) |
A relação é complementar, não competitiva. Para obter a mais alta qualidade de geração única e acesso confiável à API atualmente, o Veo 3.1 continua sendo a escolha prática. Para trabalhos iterativos e orientados a conversas — especialmente para combinar diferentes tipos de entrada — o Gemini Omni é a ferramenta que não existia antes de 19 de maio.
Omni vs. o completo campo competitivo.
O Kling 3.0 Omni suporta sequências com múltiplas tomadas, com uma linha do tempo de áudio compartilhada e diálogos nativos em cinco idiomas. Para narrativas com múltiplas tomadas e áudio nativo, ele se destaca pela duração dos clipes (até 15 segundos) e pela coerência entre cenas. O diferencial do Omni está no refinamento das conversas e na profundidade da entrada multimodal.
O Runway Gen-4.5 continua sendo o padrão profissional para precisão no controle de câmeras — direção de enquadramento, comportamento da lente, coreografia de movimento. É uma ferramenta para diretores. O Omni é mais um colaborador criativo: entradas mais amplas, iteração mais natural, mas com menos controle cinematográfico cirúrgico.
O Seedance 2.0 é o vencedor indiscutível para conteúdo narrativo, com recursos nativos revolucionários de múltiplas tomadas, além de áudio e vídeo sincronizados a partir de um único comando. Para vídeos com foco na história e continuidade entre múltiplas tomadas, é a opção mais robusta atualmente. A integração nativa do Omni com o ecossistema do Google e a edição conversacional conferem a ele uma proposta de valor diferenciada — e não inferior.
Sora não é mais uma comparação relevante. A OpenAI descontinuou as experiências web e de aplicativo do Sora em 26 de abril de 2026, e a API do Sora será desativada em 24 de setembro de 2026. Qualquer pipeline que dependesse do Sora precisa ser migrado.
| Omni Flash | Kling 3.0 | Pista 4.5 | Seedance 2.0 | Vejo 3.1 | |
|---|---|---|---|---|---|
| Edição conversacional | ✓ | ✕ | ✕ | ✕ | ✕ |
| Comprimento máximo | 10s | 15s | 10s | 15–20 anos | ~8s |
| Áudio nativo | ✓ | ✓ | ✕ | ✓ | ✓ |
| Multishot | ✕ | ✓ | Parcial | ✓ | ✕ |
| API agora | Breve | ✓ | ✓ | ✓ | ✓ |
| Nível gratuito | Vídeos curtos do YouTube | 66 cr/dia | Limitado | ✕ | Aplicativo Gemini |
Como acessar o Gemini Omni agora mesmo.
O Gemini Omni Flash está sendo lançado gratuitamente no YouTube Shorts e no YouTube Create esta semana. O Google está usando a plataforma de distribuição do YouTube para levar o Omni a centenas de milhões de usuários sem custo adicional. Abra o YouTube Shorts ou o app Create e procure a opção de criação de vídeos com IA — o Omni Flash é o mecanismo subjacente. É a maneira mais rápida de experimentar, sem necessidade de assinatura.
| Plano | Mensal | Acesso Gemini Omni |
|---|---|---|
| Google AI Plus | $ 7,99 | Aplicativo Gemini + Google Flow |
| Google AI Pro | $ 19,99 | Acesso total + limites mais altos |
| Google AI Ultra | $ 100 | Acesso prioritário + quotas ampliadas |
A geração de vídeos consome uma parte significativa da cota diária — planeje sua sessão para trabalho criativo iterativo, não para produção em massa.
Nas próximas semanas, o Google lançará o Omni Flash para desenvolvedores e empresas por meio de APIs. Nenhuma data específica foi anunciada. Os desenvolvedores podem entrar na lista de espera do Google AI Studio e acompanhar as notas de lançamento da API Gemini.
- Abra o aplicativo Gemini e faça login em um plano Plus, Pro ou Ultra.
- No seletor de modelos, escolha Gemini Omni Flash (se implementado na sua região)
- Faça o upload de material de referência — imagem, clipe de áudio ou vídeo existente.
- Escreva sua primeira pergunta descrevendo o que gerar.
- Analise a saída de 10 segundos.
- Aprimore através da conversa: "mude a iluminação", "desloque a câmera para a esquerda"
- Faça o download ou compartilhe diretamente no YouTube quando estiver satisfeito.
mundo real casos de uso.
Faça o upload de uma única foto do produto, descreva a atmosfera que ele transmite, crie um vídeo curto de 10 segundos, pronto para o formato Shorts, com movimento e ambientação — e então, refine a conversa até que o resultado esteja alinhado com a estética do seu canal.
O Omni está sendo integrado ao Estúdio de ativos Para geração de ativos de vídeo dentro da plataforma Google Ads. Gere variantes de anúncios a partir de imagens e textos de produtos e, em seguida, teste-as em campanhas de geração de demanda. Sem filmagem de produção.
Vídeos explicativos gerados por IA, narrativa visual, resumos de notícias. A demonstração de animação em massinha sobre o dobramento de proteínas é exatamente isso — conceitos complexos transformados em explicações visuais precisas. Sem experiência em animação.
Crie animações preliminares a partir de uma lista de planos e, em seguida, refine os ângulos de câmera, a iluminação e a ação por meio de conversas — Comprimir dias de pré-visualização em horas.
"Use a foto do produto em anexo e crie uma imagem principal: o objeto gira 360° sobre mármore, vapor sobe, iluminação de estúdio e uma suave música de jazz." Uma imagem estática se transforma em um vídeo em loop, pronto para a web ou redes sociais.
Por que isso é importante? além do vídeo.
A mudança mais significativa é que o vídeo com IA está passando da geração única para... Criação orientada pela conversa. Isso não é apenas uma melhoria na experiência do usuário — muda fundamentalmente quem pode produzir vídeos. A barreira histórica era a habilidade técnica: linhas do tempo, quadros-chave, correção de cores, mixagem de áudio. O Omni substitui essa curva de aprendizado pela linguagem natural. Você descreve o que deseja. Você descreve o que está errado. Você descreve o que vem a seguir. O modelo cuida da tradução técnica.
A mesma capacidade de modelagem do mundo que faz um espelho gerado ondular corretamente ao ser tocado é, em um nível mais profundo, a mesma capacidade necessária para a IA operar em ambientes físicos — robótica, simulação, modelagem científica.
Hassabis descreveu o Omni como um passo em direção à Inteligência Artificial Geral (IAG), enfatizando que o verdadeiro progresso reside na compreensão do mundo físico, e não apenas na produção de imagens realistas. Por ora, a realidade prática é mais concreta: um modelo que aceita qualquer tipo de mídia, gera vídeo coerente e permite refiná-lo por meio de conversação é genuinamente novo. Não apenas incrementalmente melhor. Categoricamente diferente.
Perguntas frequentes questões.
O que é Gemini Omni?
O Gemini Omni é gratuito?
Qual a diferença entre Gemini Omni e Veo?
Qual é a duração máxima dos vídeos?
Quando a API estará disponível?
Que tipos de entrada ele aceita?
É possível fazer edição de áudio?
O Gemini Omni não é o melhor gerador de vídeos disponível atualmente. O que ele introduz é Algo que nenhuma dessas ferramentas oferece.
Em termos de qualidade bruta de geração única, o Kling 3.0 e o Veo 3.1 produzem clipes mais refinados em durações mais longas, com acesso à API já disponível. Em relação à coerência narrativa em múltiplas tomadas, o Seedance 2.0 está à frente. Em termos de precisão no controle da câmera, o Runway Gen-4.5 continua sendo o padrão profissional.
O que a Omni apresenta é um processo de criação de vídeo que funciona como uma conversa. Forneça qualquer coisa — texto, foto, áudio, filmagem — obtenha um vídeo, diga o que precisa ser alterado e continue até ficar perfeito. Sem precisar recomeçar do zero. Sem edição na linha do tempo. Sem barreiras técnicas entre sua intenção criativa e o resultado final. Essa é a mudança. Não se trata de um gerador melhor. Trata-se de um tipo diferente de criação.
Acesse o Gemini Omni — e todas as APIs de vídeo — através de uma plataforma.
Quando a API Omni for lançada, você terá duas opções: gerenciar uma conta de faturamento, chave e cota separadas do Google Cloud, juntamente com suas integrações do Kling, Runway, Seedance e Veo, ou acessar todas elas por meio de um único gateway.
ai.cc é a plataforma unificada de API de IA que oferece aos desenvolvedores e equipes de conteúdo uma única chave, um único painel de controle e uma única fatura para todos os principais modelos — Gemini Omni Flash, Veo 3.1, Seedance 2.0, GPT Image 2.0, Suno e muito mais. Quando a API empresarial da Omni for lançada, ela estará disponível imediatamente pelo ai.cc — sem necessidade de configuração adicional de conta.
Comece em www.ai.cc →