 OpenAI - ChatGPT、Sora
OpenAI - ChatGPT、Sora Google - Gemini,Nano Banana
Google - Gemini,Nano Banana Anthropic - Claude
Anthropic - Claude xAI - Grok
xAI - Grok DeepSeek
DeepSeek 阿里巴巴 - Qwen
阿里巴巴 - Qwen 字节跳动 - 豆包
字节跳动 - 豆包 所有型号
所有型号 企业API定制计划
企业API定制计划 AI应用开发服务
AI应用开发服务 AI智能翻译API
AI智能翻译API AI SEO/GEO 服务
AI SEO/GEO 服务 GEO/AI大模型优化
GEO/AI大模型优化 网络爬虫服务
网络爬虫服务 OpenClaw
OpenClaw 顶级人工智能工具
顶级人工智能工具 顶级人工智能机器人
顶级人工智能机器人
 登录
登录














作为一名科技博主,我花了48小时在多个真实项目中对Composer 2.5进行了压力测试,现在为大家带来一份全面而深入的评测。我们将涵盖基准测试、训练细节、定价、真实用户体验、与Claude Opus 4.7和GPT-5.5的比较,以及它是否最终能让AI代理成为专业软件工程师日常工作的核心工具。
什么是 Composer 2.5?简要介绍
Cursor 的 Composer 系列是专为……而设计的 代理编码 在 Cursor IDE(及其新兴的 Glass 界面)内部。与通过 API 访问的通用模型不同,Composer 模型针对 Cursor 环境进行了端到端优化:多文件编辑、终端工具使用、代码库导航、迭代调试和长期软件工程任务。
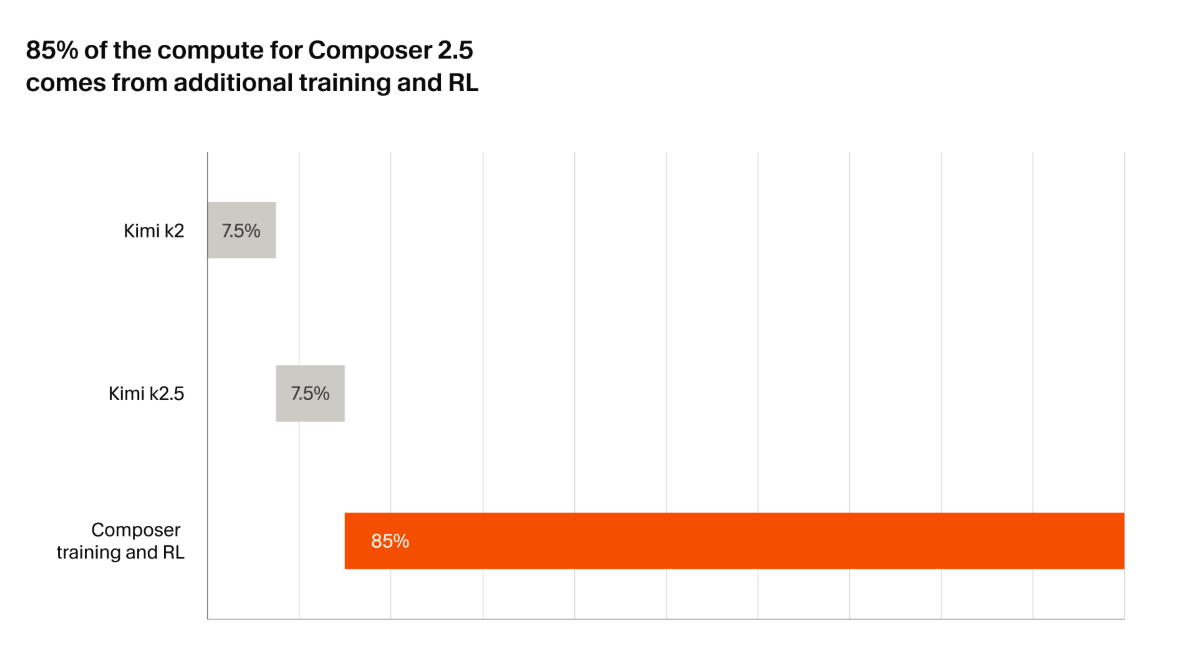
作曲家 2.5 它直接基于同一个开放重量级的 Moonshot AI 构建。 比如K2.5 Composer 2 使用的检查点。Cursor 报告称,将约 85% 的总计算预算用于训练后和强化学习 (RL),其中包括比上一版本多 25 倍的合成任务。
这并非简单的微调。它采用了诸如带有文本反馈的定向强化学习、高级合成数据生成以及专家混合模型(MoE)训练的基础设施改进等新技术。
基准测试:它到底有多好?
Cursor公布了Composer 2.5的强劲销售数据:
- SWE-Bench 多语言版: 79.8% — 与 Anthropic 的 Opus 4.7 相匹配。
- CursorBench v3.1: 63.2% — 与顶级前沿机型相比具有竞争力。
- 终端工作台 2.0有所改进,但落后于 GPT-5.5(据报道约为 69.3%,而 GPT 的准确率更高)。
对比表(根据公开报告估算):
| 基准 | 作曲家 2.5 | 作品4.7 | GPT-5.5 | 优胜者 |
|---|---|---|---|---|
| SWE-Bench 多语言版 | 79.8% | 约80% | 约78-80% | 领带 |
| CursorBench v3.1 | 63.2% | 约63-65% | 约59-63% | 领带 / 轻微作品 |
| 终端工作台 2.0 | 约69.3% | 约69.4% | 82.7% | GPT-5.5 |
考虑到成本,这些结果令人印象深刻。像 SWE-Bench 这样的公开基准测试可以跨语言测试真实的 GitHub 问题解决能力,而 CursorBench 则使用真实的 Cursor 内部工程任务(模糊提示、大型多文件更改)。
要点总结Composer 2.5 在关键的软件工程评估中达到了同等水平,而价格却低得多。它并非在所有方面都更胜一筹,但在大多数开发人员的工作流程中,它都能提供前沿级别的性能。
定价:真正的游戏规则改变者
标准
0.50美元
每 M 个输入标记
标准输出
2.50美元
每 M 个输出令牌
快速(默认)
3.00美元
每百万单位输入/15.00美元输出
这仍然比竞争对手便宜得多。作为参考,Claude Opus 的套餐价格通常在 5 美元到 25 美元以上/月之间,GPT-5.5 Pro 的价格也相差无几。此外,Cursor 还将发布后第一周的使用限额翻了一番。
分析师估算,Composer 2.5 的单项任务成本对于许多典型的工程操作而言不到 1 美元,而 Opus 或 GPT 同等质量的产品则需要几美元。这构成了一个强大的帕累托前沿:以十分之一的成本获得接近顶尖的智能水平。
实战测试:我用 Composer 2.5 构建了什么
我用 Composer 2.5 在三个实际项目中进行了全面测试:
- 全栈功能实现 (Next.js 15 + TypeScript + Supabase + Tailwind)
- 任务:构建一个人工智能驱动的任务管理应用程序,具备实时协作、拖放看板和 PDF 导出功能。
- 结果:Composer 2.5 在处理多文件脚手架方面表现出色。它创建了正确的 Supabase RLS 策略,实现了乐观的 UI 更新,并构建了一个简洁的 shadcn/ui 组件库。大多数文件都能一次性成功。对于一些特殊情况的身份验证流程,只需进行少量调整。快速模式下的速度“令人惊叹”——在类似任务中,其速度比 Opus 快 3-5 倍。
- 大型代码库重构 (传统 Python/FastAPI 单体应用,约 12 万行代码)
- 任务:将身份验证从自定义 JWT 迁移到 Auth0,更新 40 多个文件,添加全面的测试。
- 结果:性能卓越。它能正确识别依赖链,并在各个模块中保持一致的更改。偶尔需要对测试断言进行一些微调,但都能很好地恢复。对长上下文(超过 20 万个标记)的处理也十分可靠。与早期版本相比,它的“工作量校准”做得更好——不会过度编辑无关的文件。
- 终端 + 代理工作流 (Docker化微服务调试)
- 任务:诊断并修复包含 Redis、Postgres 和 Go 后端的 5 个服务设置中的网络问题。
- 结果:工具使用出色,迭代调试效果显著。它提出了
docker compose命令执行、智能检查日志并快速迭代。Terminal-Bench 的改进在此有所体现,但对于非常复杂的 shell 编排,GPT-5.5 仍然更胜一筹。
主观印象:
- 速度与响应能力快速版本令人愉悦。低延迟将工作流程从“等待人工智能”转变为“对话式配对”。
- 遵循以下说明:在处理复杂的多步骤提示时表现明显更佳。工具调用中的错误启动次数更少。
- 沟通风格更冷静、更自然。自信不再那么虚假,更善于表达“我需要更多信息”。
- 长时间任务的可靠性最大的优势在于,它能在50回合以上保持更高的专注度。
训练深度解析:2.5 版本有何不同之处
Cursor 的技术方法独树一帜:
- 利用文本反馈进行定向强化学习:通过针对特定错误(例如,无效的工具调用)插入局部提示,解决长时间部署中的积分分配问题。这可以在不引入全局噪声奖励的情况下改善性能。
- 海量合成数据任务数量增加了 25 倍,其中包括“功能删除”任务,即智能体必须在保持测试通过的前提下重新实现已删除的功能。这生成了基于真实代码库的、难度较高且可验证的问题。
- 基础设施建设致胜分片缪子优化器、MoE 双网格 HSDP、异步 RL 流水线——能够在大型集群上实现高效扩展(包括在 Colossus 2 上进行部分训练)。
他们已经与 xAI/SpaceXAI 合作,从零开始构建一个规模更大的模型,使用 10 倍的计算能力。
《奇米K2.5》的故事:透明度与争议
与 Composer 2 类似,2.5 版本也以 Moonshot 的 Kimi K2.5 为基础,并在此基础上进行了大量的 Cursor 特有的强化学习。最初的版本发布引发了关于署名权的争议,但 Cursor 此后变得更加开放,Moonshot 也通过 Fireworks 等平台承认了商业合作关系。
这种混合方法(强大的开放基础 + 特定领域的强化学习)越来越普遍且有效。最终结果明显是针对 Cursor 的智能体工作流程量身定制的。
哪些人应该使用 Composer 2.5?
是的——切换或优先处理:
- 你希望每花费一美元能获得最大的迭代次数。
- 您的工作流程涉及大量代理任务、多文件任务或长时间运行的任务。
- 你更看重速度和愉快的合作,而不是在最难的问题上追求绝对的巅峰推理能力。
- 你们的预算是团队预算(可以非常有效地节省成本)。
坚持使用 Opus/GPT:
- 超复杂的新型架构或研究级推理。
- 需要熟练掌握 Terminal-Bench 式 shell 的任务。
- 在模糊不清、风险极高的问题上取得一次性成功(尽管差距正在迅速缩小)。
许多开发者表示,他们使用 Composer 2.5 作为默认的“主力军”,同时将最难的子任务分配给高级型号——这是一种巧妙的混合策略。
优点和缺点
优势
- 超高的性价比。
- 极速模式。
- 提高了长时间任务的可靠性和性能。
- 优秀的多文件编辑能力和代码库理解能力。
- 双倍使用优惠(请查看当前限额)。
局限性
- 在某些终端/代理基准测试中仍然略逊一筹。
- IDE锁定(暂无公共API)。
- 有时需要对非常新颖或特殊情况的逻辑提供更多指导。
- 基础模型的起源在一些群体中持续引发讨论。
最终结果
9.2/10
对于大多数开发者而言
作曲家 2.5 这是迄今为止最有力的论断,表明经过专业化、高效后训练的模型能够以普通价格交付前沿成果。它并非在所有方面都优于 Claude Opus 4.7 或 GPT-5.5,但在对 80% 的实际工作至关重要的指标上,它与它们非常接近——同时成本更低,循环速度也更快。
对于独立开发者、初创公司以及从事迭代产品开发的团队而言,这可能是一项能够改变人工智能辅助工程经济模式的日常驱动力。即将推出的基于 xAI 计算训练的大型模型可能会将这种变革推向新的高度。
如果您已经在使用 Cursor,请启用 Composer 2.5(默认快速模式)并立即体验——尤其是在使用次数翻倍活动期间。对于其他用户来说,这也是认真考虑 Cursor 的又一个充分理由。
你试用过 Composer 2.5 了吗?欢迎在评论区分享你的使用体验——哪些功能好用,哪些功能不好用,以及它在你的技术栈中表现如何。我会更新这篇文章,添加更多用户数据和后续测试结果。