 OpenAI - ChatGPT, Sora
OpenAI - ChatGPT, Sora Google - Gemini, Nano Banana
Google - Gemini, Nano Banana Anthropic - Claude
Anthropic - Claude xAI - Grok
xAI - Grok Deepseek
Deepseek Alibaba - Qwen
Alibaba - Qwen ByteDance - Doubao
ByteDance - Doubao All Models
All Models Enterprise Plans
Enterprise Plans AI Application Development
AI Application Development AI Translator API
AI Translator API AI SEO/GEO Service
AI SEO/GEO Service GEO-Optimized PR Service
GEO-Optimized PR Service Web Scraping Service
Web Scraping Service OpenClaw
OpenClaw Top AI Tools
Top AI Tools Top AI Robots
Top AI Robots
 Log in
Log in















As a tech blogger who's spent the last 48 hours stress-testing Composer 2.5 across multiple real projects, I'm here with a comprehensive, hands-on review. We'll cover benchmarks, training details, pricing, real-user experiences, comparisons to Claude Opus 4.7 and GPT-5.5, and whether this is the model that finally makes AI agents a daily driver for professional software engineering.
What Is Composer 2.5? Quick Context
Cursor's Composer series is purpose-built for agentic coding inside the Cursor IDE (and its emerging Glass interface). Unlike general-purpose models accessed via API, Composer models are optimized end-to-end for the Cursor environment: multi-file editing, terminal tool use, codebase navigation, iterative debugging, and long-horizon software engineering tasks.
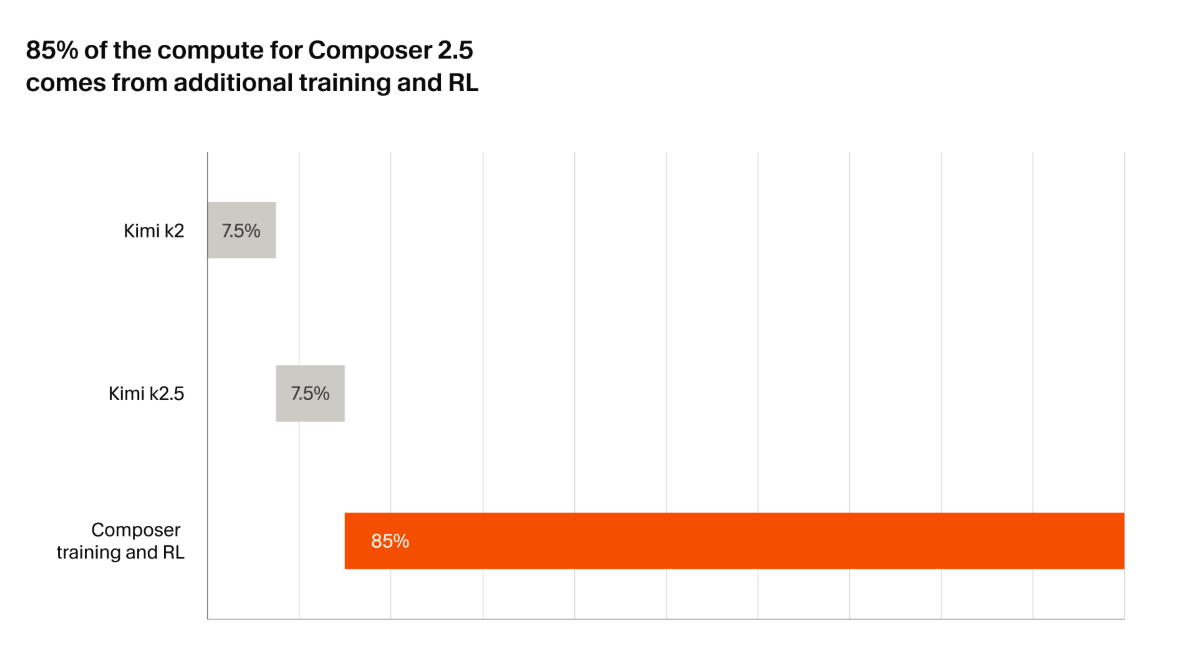
Composer 2.5 builds directly on the same open-weight Moonshot AI Kimi K2.5 checkpoint used for Composer 2. Cursor reports spending ~85% of the total compute budget on post-training and reinforcement learning (RL), including 25x more synthetic tasks than the previous version.
This isn't a simple fine-tune. It features new techniques like targeted RL with textual feedback, advanced synthetic data generation, and infrastructure improvements for Mixture-of-Experts (MoE) training.
Benchmarks: How Good Is It Really?
Cursor published strong numbers for Composer 2.5:
- SWE-Bench Multilingual: 79.8% — matching Anthropic's Opus 4.7.
- CursorBench v3.1: 63.2% — competitive with top frontier models.
- Terminal-Bench 2.0: Improved but trails GPT-5.5 (reported around 69.3% vs. higher for GPT).
Comparison Table (Approximate from public reports):
| Benchmark | Composer 2.5 | Opus 4.7 | GPT-5.5 | Winner |
|---|---|---|---|---|
| SWE-Bench Multilingual | 79.8% | ~80% | ~78-80% | Tie |
| CursorBench v3.1 | 63.2% | ~63-65% | ~59-63% | Tie / Slight Opus |
| Terminal-Bench 2.0 | ~69.3% | ~69.4% | 82.7% | GPT-5.5 |
These are impressive, especially considering cost. Public benchmarks like SWE-Bench test real GitHub issue resolution across languages, while CursorBench uses real internal Cursor engineering tasks (ambiguous prompts, large multi-file changes).
Key takeaway: Composer 2.5 reaches parity on key software engineering evals at a fraction of the price. It's not universally superior, but it delivers frontier-level performance where it counts for most developer workflows.
Pricing: The Real Game-Changer
Standard
$0.50
per M input tokens
Standard Output
$2.50
per M output tokens
Fast (Default)
$3.00
per M input / $15.00 output
This remains dramatically cheaper than competitors. For context, Claude Opus tiers often run $5–$25+/M, and GPT-5.5 Pro is similarly expensive. Cursor also doubled usage allowances for the first week post-launch.
Per-task cost estimates from analysts put Composer 2.5 at under $1 for many typical engineering actions, versus several dollars for equivalent quality from Opus or GPT. This creates a powerful Pareto frontier: near-top intelligence at 1/10th the cost.
Hands-On Testing: What I Built With Composer 2.5
I put Composer 2.5 through its paces on three real projects:
- Full-Stack Feature Implementation (Next.js 15 + TypeScript + Supabase + Tailwind)
- Task: Build an AI-powered task management app with real-time collaboration, drag-and-drop Kanban, and PDF export.
- Result: Composer 2.5 handled multi-file scaffolding exceptionally well. It created correct Supabase RLS policies, implemented optimistic UI updates, and wired up a clean shadcn/ui component library. One-shot success on most files. Minor tweaks needed for edge-case auth flows. Speed in Fast mode was “mind-blowing” — generations felt 3-5x snappier than Opus in similar tasks.
- Large Codebase Refactor (Legacy Python/FastAPI monolith, ~120k LOC)
- Task: Migrate authentication from custom JWT to Auth0, update 40+ files, add comprehensive tests.
- Result: Strong performance. It correctly identified dependency chains and made consistent changes across modules. It occasionally needed gentle nudges on test assertions, but recovered well. Long-context handling (200k+ tokens) felt reliable. Better “effort calibration” than earlier versions — it didn't over-edit unrelated files.
- Terminal + Agentic Workflow (Dockerized microservices debugging)
- Task: Diagnose and fix a networking issue in a 5-service setup with Redis, Postgres, and a Go backend.
- Result: Excellent tool use and iterative debugging. It proposed
docker composecommands, inspected logs intelligently, and iterated quickly. Terminal-Bench improvements showed here, though GPT-5.5 still feels stronger for very complex shell orchestration.
Subjective Impressions:
- Speed & Responsiveness: Fast variant is a joy. Low latency changes the workflow from “wait for AI” to “conversational pairing.”
- Instruction Following: Noticeably better at complex, multi-step prompts. Fewer false starts on tool calls.
- Communication Style: Calmer, more natural. Less hallucinated confidence, better at saying “I need more info here.”
- Reliability on Long Tasks: The biggest win. It sustains focus better over 50+ turns.
Training Deep Dive: What Makes 2.5 Different
Cursor's technical approach stands out:
- Targeted RL with Textual Feedback: Solves credit assignment in long rollouts by inserting localized hints for specific mistakes (e.g., invalid tool calls). This improves behavior without noisy global rewards.
- Massive Synthetic Data: 25x more tasks, including “feature deletion” where the agent must reimplement removed functionality while keeping tests green. This generates hard, verifiable problems grounded in real codebases.
- Infrastructure Wins: Sharded Muon optimizer, dual-mesh HSDP for MoE, async RL pipelines — enabling efficient scaling on large clusters (including partial training on Colossus 2).
They're already partnering with xAI/SpaceXAI for a much larger from-scratch model using 10x more compute.
The Kimi K2.5 Story: Transparency & Controversy
Like Composer 2, 2.5 uses Moonshot's Kimi K2.5 as the base checkpoint with heavy Cursor-specific RL on top. Initial launches sparked debate around attribution, but Cursor has since been more open, and Moonshot has acknowledged commercial partnerships via platforms like Fireworks.
This hybrid approach (strong open base + domain-specific RL) is increasingly common and effective. The end result feels distinctly tuned for Cursor's agent workflows.
Who Should Use Composer 2.5?
Yes — Switch or Prioritize If:
- You want maximum iterations per dollar.
- Your workflow involves lots of agentic, multi-file, or long-running tasks.
- You value speed and pleasant collaboration over absolute peak reasoning on the hardest problems.
- You're on a team budget (dramatic cost savings scale beautifully).
Stick with Opus/GPT For:
- Ultra-complex novel architecture or research-level reasoning.
- Tasks where Terminal-Bench-style shell mastery is critical.
- Maximum one-shot success on ambiguous, high-stakes problems (though the gap is narrowing fast).
Many developers report using Composer 2.5 as the default “workhorse” while routing hardest subtasks to premium models — a smart hybrid strategy.
Pros and Cons
Advantages
- Insane price/performance ratio.
- Blazing Fast mode.
- Improved reliability and behavior on long tasks.
- Excellent multi-file editing and codebase understanding.
- Doubled usage promo (check current limits).
Limitations
- Still trails slightly on some terminal/agent benchmarks.
- IDE-locked (no public API yet).
- Occasional need for more guidance on very novel or edge-case logic.
- Base model origins continue to spark discussion in some communities.
Final Verdict
9.2/10
For Most Developers
Composer 2.5 is the strongest statement yet that specialized, efficiently post-trained models can deliver frontier results at commodity prices. It doesn't universally beat Claude Opus 4.7 or GPT-5.5, but it matches them closely enough on the metrics that matter for 80% of real work — while costing a fraction as much and feeling faster in the loop.
For solo developers, startups, and teams doing iterative product work, this is a potential daily driver that changes the economics of AI-assisted engineering. The upcoming larger model trained with xAI compute could push things even further.
If you're already in Cursor, enable Composer 2.5 (Fast by default) and try it today — especially while the doubled usage lasts. For everyone else, it's another compelling reason to give Cursor a serious look.
Have you tried Composer 2.5 yet? Drop your experiences in the comments — what worked, what didn't, and how it compares in your stack. I'll be updating this post with more user data and follow-up tests.