 OpenAI - ChatGPT, Sora
OpenAI - ChatGPT, Sora Google - Gemini, Nano Banana
Google - Gemini, Nano Banana Anthropic - Claude
Anthropic - Claude xAI - Grok
xAI - Grok Deepseek
Deepseek Alibaba - Qwen
Alibaba - Qwen ByteDance - Doubao
ByteDance - Doubao All Models
All Models Enterprise Plans
Enterprise Plans AI Application Development
AI Application Development AI Translator API
AI Translator API AI SEO/GEO Service
AI SEO/GEO Service GEO-Optimized PR Service
GEO-Optimized PR Service Web Scraping Service
Web Scraping Service OpenClaw
OpenClaw Top AI Tools
Top AI Tools Top AI Robots
Top AI Robots
 Log in
Log in














Xiaomi MiMo V2.5:
The 310B model that just caught up ate Claude Opus on token efficiency.
Xiaomi's MiMo V2.5 is the most consequential open-weight release of Q2 2026 — a 310B sparse Mixture-of-Experts model with native multimodal understanding, a 1M-token context window, and benchmark numbers that put it neck-and-neck with Claude Opus and Gemini 3 Pro while burning 40–60% fewer tokens. Here is the full breakdown: architecture, benchmarks, real-world tasks, pricing, and how it stacks up against the closed-source frontier.

What is Xiaomi MiMo V2.5?
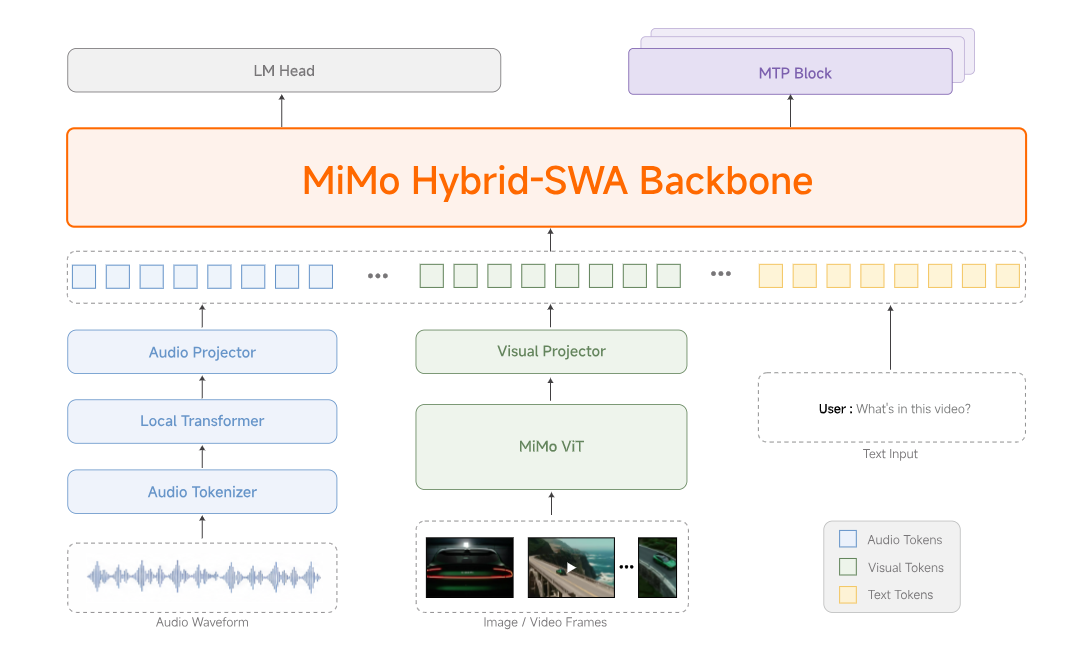
MiMo V2.5 is the latest model family from Xiaomi's MiMo team, released in late April 2026 and pushed straight to Hugging Face as open weights. There are actually two flagship models in the drop, plus a TTS suite and an ASR model — and that distinction matters because most of the hype online conflates them.
The line splits like this:
- MiMo-V2.5 — The "Omni" multimodal generalist.
310B total params,15B active, sparse MoE architecture, trained on 48T tokens. Native vision and audio understanding. The all-rounder. - MiMo-V2.5-Pro — The "Agent" specialist.
1.02T total params,42B active. Same hybrid attention backbone but tuned hard for long-horizon coding and thousands-of-tool-calls trajectories. - MiMo-V2.5-TTS — A three-model voice suite (TTS, VoiceDesign, VoiceClone) for production speech generation, with style-instruction control over speed, emotion, and tone.
- MiMo-V2.5-ASR — End-to-end speech recognition that handles Chinese dialects (Wu, Cantonese, Hokkien, Sichuanese), code-switched speech, song lyrics, and noisy acoustic environments.
Both flagship models share an in-house hybrid sliding-window attention architecture inherited from MiMo-V2-Flash, with dedicated visual and audio encoders connected through lightweight projectors. Both ship with a native 1,048,576-token context window. Neither charges a context-length multiplier — Xiaomi removed that on launch day.
MiMo V2.5 vs Claude Opus, Gemini 3 Pro, GPT-5.4
The headline benchmark — and the one Xiaomi led the launch with — is ClawEval, a multi-turn agentic task suite where the model has to plan, call tools, and iterate over long horizons. This is the benchmark that maps to actual production agentic workloads, and it is where MiMo V2.5 looks the strongest.
| Model | ClawEval Pass³ | Tokens / Trajectory | Cost-Adjusted Rank |
|---|---|---|---|
| MiMo V2.5-Pro | 63.8 – 64.0% | ~70K | #1 (Pareto frontier) |
| MiMo V2.5 (base) | 62.3% | ~75K | Tied frontier |
| Claude Opus 4.6 | ~65.4% | ~120–175K | Higher cost |
| Gemini 3.1 Pro | ~63% | ~115K | Higher cost |
| GPT-5.4 | ~62% | ~110K | Higher cost |
The takeaway: Claude Opus 4.6 still has a slight edge on raw capability, but MiMo V2.5-Pro hits the same neighborhood while spending roughly 40–60% fewer tokens to get there. On a pricing-per-trajectory basis, this is not a rounding error. As VentureBeat noted, in a world where GitHub Copilot and most agent platforms are moving to usage-based billing, this token efficiency translates directly into real money for any team running agents at scale.
On other benchmarks, the picture is a coding-first specialist:
- SWE-bench Pro:
57.2%— within half a point of Claude Opus 4.6 and GPT-5.4. - Terminal-Bench 2.0: Leads Opus 4.6 and Gemini 3.1 Pro outright.
- Video-MME:
87.7— on par with Gemini 3 Pro on video understanding. - GDPVal-AA (Elo):
1581— surpasses Kimi K2.6 and GLM 5.1. - Long-context recall (1M):
0.37 BFS / 0.62 Parents— where most competitors collapse to near-zero past 512K.
Where it lacks: HLE (Humanity's Last Exam) and GDPVal-AA broad reasoning — both reward general-purpose breadth over coding-specialist depth. If you need a tutor or a polymath, this is not your model. If you need an agent that ships code, it absolutely is.
What can MiMo V2.5-Pro actually do?
Benchmarks are one thing. Xiaomi went further and published four multi-hour autonomous task runs — the kind of work where the agent can't be hand-held. These are the demos worth taking seriously, because they include the full tool-call trace.
The Rust compiler run is the one to internalize. It is not a toy. It is a real PKU course project with a real hidden test suite, and a frontier closed-source model would have struggled to do it in one shot at that token budget. This is what the phrase "long-horizon coherence" actually looks like in production.
MiMo V2.5 pricing — and why it's the real story
Here is where the open-source positioning gets interesting. MiMo V2.5 ships under open weights on Hugging Face for self-hosting, but Xiaomi also runs a hosted API with aggressive pricing — and a "Token Plan" subscription model that mirrors Claude Code and OpenAI's flat-rate offerings.
Two things to flag: cache hits drop input cost as low as $0.20–0.40 per million tokens, and Xiaomi made cache writing free of charge for a limited launch window. The 1M-context multiplier is also gone. If you are running long-horizon agents, the real cost gap versus closed-source frontier models is closer to 10× than 5×.
For teams that prefer flat-rate, the four-tier Token Plan goes from $63.36/yr (Lite, 720M credits) to $1,056/yr (Max, 19.2B credits) — and is compatible with Claude Code, OpenCode, and Kilo as drop-in scaffolds.
Should you use MiMo V2.5? Pros, cons, and who it's for.
Strengths
- Best-in-class token efficiency on agentic tasks (40–60% fewer tokens than Claude Opus 4.6).
- Genuine 1M-token usable context — doesn't collapse past 512K like most rivals.
- Native multimodal in a single model (image, video, audio, text).
- Open weights on Hugging Face — self-hostable, fine-tunable.
- "Harness awareness" — actively manages its own context across thousands of tool calls.
- Drop-in compatible with Claude Code, OpenCode, Kilo.
Weaknesses
- Trails on broad-reasoning benchmarks (HLE, GDPVal-AA) — coding-first by design.
- Self-reported figures on token efficiency need independent replication.
- Hosted infrastructure outside China is still maturing — latency varies.
- Tool-call ecosystem and harness integrations less battle-tested than Claude or GPT.
- Documentation and community support still catching up to Western providers.
Who should use MiMo V2.5
If you are building agentic coding workflows — long-horizon, multi-tool, repo-scale — and your unit economics depend on token cost, MiMo V2.5-Pro is now on the shortlist. Same goes for any team running multimodal agents with heavy video or document understanding.
Who should stick with Claude or GPT
If your primary workload is broad-reasoning chat, research synthesis, or general knowledge work, Claude Opus 4.7 and GPT-5.5 still hold the edge. The Western models also have more mature tool ecosystems, longer track records of stability under production load, and stronger guarantees around enterprise data handling.
Frequently asked questions
Is MiMo V2.5 actually open source?
Is MiMo V2.5 better than Claude Opus 4.7?
How much does MiMo V2.5 cost via API?
Can I use MiMo V2.5 with Claude Code or OpenCode?
What hardware do I need to self-host MiMo V2.5?
What is "harness awareness" and why does it matter?
The open-source frontier just moved.
MiMo V2.5 is not a Claude Opus replacement for every workload — but for agentic coding at scale, it is the new cost-adjusted leader, and the gap to closed-source frontier is officially within rounding distance. We will be tracking real-world replication, third-party benchmarks, and ecosystem adoption as it evolves.