 OpenAI - ChatGPT, Sora
OpenAI - ChatGPT, Sora Google - Gemini, Nano Banana
Google - Gemini, Nano Banana Anthropic - Claude
Anthropic - Claude xAI - Grok
xAI - Grok Deepseek
Deepseek Alibaba - Qwen
Alibaba - Qwen ByteDance - Doubao
ByteDance - Doubao All Models
All Models Enterprise Plans
Enterprise Plans AI Application Development
AI Application Development AI Translator API
AI Translator API AI SEO/GEO Service
AI SEO/GEO Service GEO-Optimized PR Service
GEO-Optimized PR Service Web Scraping Service
Web Scraping Service OpenClaw
OpenClaw Top AI Tools
Top AI Tools Top AI Robots
Top AI Robots


















This is DeepSeek's most significant release since R1 shocked global markets in January 2025. Here is everything you need to know.
What Is DeepSeek V4?
DeepSeek V4 is the fourth-generation flagship model family from DeepSeek, the Hangzhou-based AI lab that rocked global markets in January 2025 with the low-cost R1 reasoning model. V4 replaces DeepSeek V3 and V3.2, which are being retired after July 24, 2026.
DeepSeek V4 is a dual-model release built on a Mixture-of-Experts (MoE) architecture. Both models support a 1 million token context window with a maximum output of 384K tokens, and both are released under the MIT license — meaning free commercial use and full weights access on Hugging Face.
DeepSeek-V4-Pro is the flagship: 1.6 trillion total parameters, 49 billion active per token, pre-trained on 33 trillion tokens. DeepSeek-V4-Flash is the efficiency play: 284 billion total parameters, 13 billion active per token, trained on 32 trillion tokens.
This makes DeepSeek-V4-Pro the new largest open-weights model available. It's larger than Kimi K2.6 (1.1T) and GLM-5.1 (754B) and more than twice the size of DeepSeek V3.2 (685B).
Both models are currently in preview. Reuters reported that DeepSeek is using the preview period to gather real-world feedback before finalizing the model, and did not provide a timeline for finalization.
The Architecture That Makes This Possible
DeepSeek V4 is not simply a larger version of V3. V4 introduces three architectural changes that separate it from V3.2: the CSA+HCA hybrid attention mechanism, Manifold-Constrained Hyper-Connections (mHC), and the Muon optimizer. Together, these explain how a model this large can run at a fraction of V3.2's inference cost.
Hybrid Attention: CSA + HCA
The central engineering problem V4 attacks is attention cost at long context. Standard transformer attention scales quadratically with sequence length — running it at 1 million tokens with a model this size would be economically prohibitive.
The central innovation is a hybrid attention mechanism that interleaves Compressed Sparse Attention (CSA) and Heavily Compressed Attention (HCA) across transformer layers. CSA compresses the Key-Value cache of every m tokens into a single entry using a learned token-level compressor, then applies query-dependent top-k KV selection. HCA takes compression further for layers that tolerate greater approximation.
The practical result is striking. In the 1M-token context setting, DeepSeek-V4-Pro requires only 27% of single-token inference FLOPs and 10% of KV cache compared with DeepSeek-V3.2. V4-Flash pushes that further to 10% of FLOPs and 7% of KV cache.
The key insight is that the efficiency numbers are not achievable by either CSA or HCA alone — the interleaved hybrid is what holds long-context quality while dropping FLOPs and KV cache by an order of magnitude.
Manifold-Constrained Hyper-Connections (mHC)
mHC addresses a fundamental problem in deep neural network training: as models grow to hundreds or thousands of layers, standard residual connections create signal propagation instability. mHC constrains the mixing matrices to the Birkhoff Polytope using the Sinkhorn-Knopp algorithm, which preserves signal magnitude through the network. In plain terms: it keeps trillion-parameter training stable where previous architectures would diverge.
The Muon Optimizer
V4 is trained using the Muon optimizer, which applies Newton-Schulz iterations to approximately orthogonalize the gradient update matrix before applying it as a weight update. Compared to AdamW, Muon produces faster convergence and greater training stability — particularly important when training a 1.6T parameter model where optimizer instability would be catastrophic.
Three Reasoning Modes
Each V4 model exposes three reasoning effort levels: Non-Think, Think High, and Think Max. Max uses longer contexts and reduced length penalties in RL, and is the mode that should be used for the hardest reasoning tasks. The difference is significant: on HLE, V4-Pro goes from 7.7 (Non-Think) to 37.7 (Max) — a near 5x jump from the same model simply by allocating more reasoning compute.
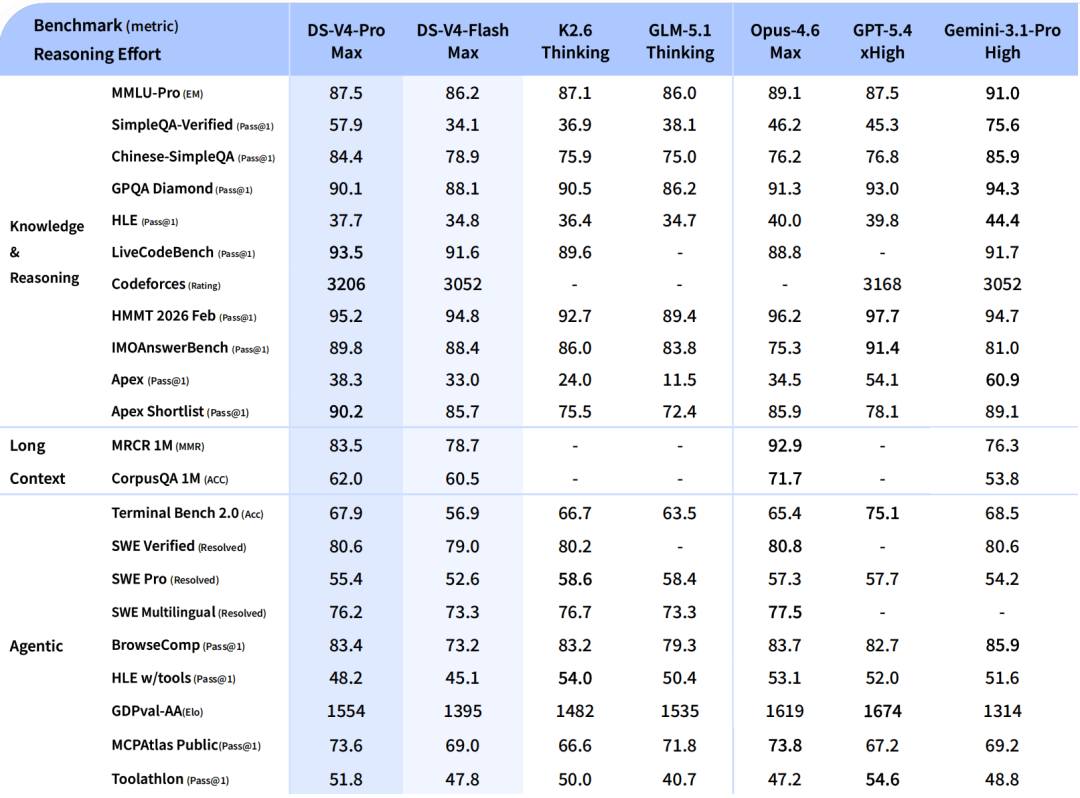
DeepSeek V4 Benchmarks: The Full Picture
V4-Pro-Max scores 80.6% on SWE-bench Verified and 93.5 on LiveCodeBench — the highest coding benchmark score of any model currently available.
The competition context matters here. Claude Opus 4.6 holds a marginal lead on SWE-bench Verified (80.8% vs 80.6%), and a meaningful lead on HLE (40.0% vs 37.7%) and HMMT 2026 math (96.2% vs 95.2%). V4-Pro costs 7x less per million output tokens.
On formal mathematics, the results are exceptional. On Putnam-2025, which combines informal reasoning with formal verification and heavier compute, V4 reaches a proof-perfect 120/120, tying Axiom and ahead of Aristotle (100/120) and Seed-1.5-Prover (110/120). On competition math benchmarks, HMMT 2026 February at 95.2 and IMOAnswerBench at 89.8 put V4-Pro-Max within range of GPT-5.4.
On competitive programming, V4-Pro reaches a Codeforces rating of 3,206, ranking 23rd among human competitors.
Where V4-Pro-Max trails the leaders: V4-Pro-Max trails Gemini 3.1 Pro on most knowledge-heavy benchmarks including MMLU-Pro, SimpleQA, GPQA Diamond, and HLE. The gap has narrowed substantially but has not closed.
DeepSeek V4 vs GPT-5.5, Claude Opus 4.7, and Gemini 3.1 Pro
| Metric | DeepSeek V4-Pro | GPT-5.5 | Claude Opus 4.7 | Gemini 3.1 Pro |
|---|---|---|---|---|
| SWE-bench Verified | 80.6% | — | 80.8% | — |
| LiveCodeBench | 93.5 | — | — | — |
| Codeforces Rating | 3,206 | — | — | 3,052 |
| HMMT 2026 Feb | 95.2% | — | 96.2% | — |
| Terminal-Bench 2.0 | 67.9% | 82.7% | 69.4% | 68.5% |
| API Output Price / 1M | $3.48 | $30.00 | $75.00 | — |
| Context Window | 1M tokens | 1M tokens | 1M tokens | 1M tokens |
| Open Source | ✓ MIT | ✗ | ✗ | ✗ |
| Self-Hostable | ✓ | ✗ | ✗ | ✗ |
The V4 Pro model costs $0.145 per million input tokens and $3.48 per million output tokens, undercutting Gemini 3.1 Pro, GPT-5.5, Claude Opus 4.7, and GPT-5.4. The performance-per-dollar calculation at this price point is difficult for closed-source competitors to answer.
DeepSeek-V4-Pro demonstrates superior performance relative to GPT-5.2 and Gemini 3.0 Pro on standard reasoning benchmarks, though its performance falls marginally short of GPT-5.4 and Gemini 3.1 Pro, suggesting a developmental trajectory that trails state-of-the-art frontier models by approximately 3 to 6 months.
Pricing: The Number That Changes Everything
The smaller V4-Flash model costs $0.14 per million input tokens and $0.28 per million output tokens, undercutting GPT-5.4 Nano, Gemini 3.1 Flash, GPT-5.4 Mini, and Claude Haiku 4.5.
At cache-miss rates, V4-Pro costs roughly one-seventh of GPT-5.5 and about one-sixth of Claude Opus 4.7 for equivalent throughput.
V4-Pro-Max at $3.48 per million output tokens delivers SWE-bench performance within 0.2 points of Claude Opus 4.6 at $75 per million output tokens. That is a 21x cost reduction at near-identical coding benchmark performance. For teams running thousands of agentic coding tasks per day, this changes what is economically feasible.
V4-Flash's pricing deserves particular attention for high-volume use cases. The gap between Flash and Pro is narrow — Flash gives up roughly 1-2 points across most benchmarks in exchange for a 12x reduction in API cost. For most production applications that do not require peak reasoning performance, V4-Flash is the correct economic default.
How to Access DeepSeek V4 Today
DeepSeek V4 is available in three ways. First, via chat.deepseek.com — the web chatbot exposes V4 through two toggles: Expert Mode (V4-Pro) and Instant Mode (V4-Flash). Second, via the DeepSeek API using model IDs deepseek-v4-pro and deepseek-v4-flash. Third, as open weights on Hugging Face under the MIT license, allowing free commercial use and local deployment.
Both models support 1M context and dual modes (Thinking and Non-Thinking). Note that deepseek-chat and deepseek-reasoner will be fully retired and inaccessible after July 24, 2026. Developers using existing aliases should migrate to the explicit V4 model IDs before that deadline.
Both V4-Pro and V4-Flash support the OpenAI ChatCompletions format and the Anthropic API format. For most teams, this means integration requires nothing more than updating the model parameter — no base URL change needed.
For self-hosting: V4-Flash weights are the practical self-hosting target. At 284B parameters with 13B activated per token, V4-Flash can run on a multi-GPU setup that most mid-size teams can afford. V4-Pro at 1.6T total parameters requires significant cluster capacity to serve at production latency — most teams will use the DeepSeek API for Pro and consider self-hosting only for Flash.
Where DeepSeek V4 Falls Short
Honest analysis requires acknowledging the genuine limitations DeepSeek itself documents.
Both V4 Flash and V4 Pro support text only, unlike many closed-source peers which offer support for understanding and generating audio, video, and images. For multimodal applications, V4 is not currently competitive.
On knowledge-intensive tasks, the gap to frontier closed-source models remains. DeepSeek is unusually candid in the tech report about V4's remaining limitations: V4-Pro-Max trails Gemini 3.1 Pro on most knowledge-heavy benchmarks. The gap has narrowed substantially but has not closed.
For agentic workflows at the absolute frontier, V4-Pro-Max ties the leaders on SWE Verified (80.6) but trails on SWE Pro (55.4) and on Terminal-Bench 2.0. For pure agentic coding at the frontier, GPT-5.5 and Opus 4.7 still look stronger.
DeepSeek also acknowledges architectural complexity as a self-identified limitation — the team describes the V4 architecture as "relatively complex" and states that future versions will aim to distill it down to its most essential designs.
The Geopolitical Dimension You Can't Ignore
DeepSeek V4 did not arrive in a vacuum. The launch comes a day after the U.S. accused China of stealing American AI labs' IP on an industrial scale using thousands of proxy accounts. DeepSeek itself has been accused by Anthropic and OpenAI of "distilling," essentially copying, their AI models.
The hardware story is equally significant. DeepSeek partnered with Chinese tech giant Huawei, which confirmed it supports the AI startup with its "Supernode" technology by combining large clusters of its Ascend 950 chips to provide more computing power.
"It allows AI systems to be built and deployed without relying solely on Nvidia, which is why V4 could ultimately have an even bigger impact than R1 — accelerating adoption domestically and contributing to faster global AI development overall."
— Wei Sun, Principal Analyst, Counterpoint ResearchIvan Su, senior equity analyst at Morningstar, told CNBC that V4's debut is unlikely to have the same market impact as R1, because traders have already priced in the reality that Chinese AI is competitive and cheaper to use. However, DeepSeek's latest positioning places other Chinese open-source models as direct competitors — "a framing that didn't exist with R1, and that alone tells you how much domestic competition has intensified."
Who Should Use DeepSeek V4?
You are running coding agents, multi-step reasoning pipelines, or complex document analysis at scale. The SWE-bench performance is within measurement noise of Claude Opus 4.6 at a fraction of the cost.
You need cost-optimized, high-volume inference without sacrificing much quality. At $0.28 per million output tokens, Flash is the most cost-efficient frontier-class model for production workloads.
You have data sovereignty requirements, operate under export-control constraints, or want full control over your inference stack. The MIT license and Hugging Face availability make this genuinely accessible.
Your workflows depend on multimodal inputs, you require the absolute frontier on agentic computer-use tasks, or your applications involve sensitive data where hosting with a Chinese-domiciled company creates compliance concerns.
Frequently Asked Questions
DeepSeek V4 is the fourth-generation flagship model from DeepSeek, released on April 24, 2026. It comes in two variants — V4-Pro (1.6T parameters, 49B active) and V4-Flash (284B parameters, 13B active) — both supporting a 1 million token context window under the MIT open-source license.
On coding benchmarks such as SWE-bench Verified and LiveCodeBench, V4-Pro-Max is competitive with or ahead of GPT-5.5. On agentic computer-use benchmarks like Terminal-Bench 2.0, GPT-5.5 leads significantly (82.7% vs 67.9%). The key difference is price: V4-Pro costs $3.48 per million output tokens versus GPT-5.5's $30.
V4-Flash costs $0.14 per million input tokens and $0.28 per million output tokens. V4-Pro costs $1.74 per million input tokens and $3.48 per million output tokens. Both are dramatically cheaper than comparable closed-source models.
Yes. Both V4-Pro and V4-Flash are released under the MIT license, with full weights available on Hugging Face. You can download, run, and commercially deploy the models without additional licensing fees.
The model weights are free to download and self-host. The web interface at chat.deepseek.com is accessible at no charge. API usage is charged at the rates above.
Both will be deprecated and fully retired on July 24, 2026. They now map to deepseek-v4-flash in Non-Thinking and Thinking modes respectively. Developers should migrate to the explicit V4 model IDs.
V4-Flash (284B total parameters, 160GB on Hugging Face) is the practical local deployment target for teams with multi-GPU setups. V4-Pro at 865GB requires significant cluster resources for production-grade latency.
No. V4 supports text input only. Audio, image, and video processing are not available in the current release.
DeepSeek V4 does not unseat GPT-5.5 or Claude Opus 4.7 across every benchmark. It does not need to. The core argument is economic: near-frontier coding and reasoning performance, open weights under a permissive license, and API pricing that undercuts closed-source alternatives by a factor of seven to twenty-one.
For the majority of developers and enterprises building with LLMs, the question was never "which model scores highest on a benchmark sheet?" It was always "which model delivers acceptable quality at a cost that makes the product viable?" DeepSeek V4 moves that calculus decisively for a significant slice of real-world use cases.
Neil Shah, vice president of research at Counterpoint Research, described V4 as "a serious flex," noting its lower inference costs compared to previous models. That assessment holds. DeepSeek has done something that most observers considered unlikely eighteen months ago: built and shipped a genuinely competitive open-source model on restricted hardware, priced it at a level that changes enterprise buying decisions, and released the weights for anyone in the world to run.
The AI race is not slowing down. But it is, demonstrably, getting cheaper.
DeepSeek Official API Docs · Hugging Face Model Card · CNBC · TechCrunch · Reuters · CNN Business · BuildFastWithAI · Morph LLM · Digital Applied · FelloAI · Kingy AI