 OpenAI - ChatGPT, Sora
OpenAI - ChatGPT, Sora Google - Gemini, Nano Banana
Google - Gemini, Nano Banana Antrópico - Claude
Antrópico - Claude xAI - Grok
xAI - Grok Busca profunda
Busca profunda Alibaba - Qwen
Alibaba - Qwen ByteDance - O Melhor da ByteDance
ByteDance - O Melhor da ByteDance Todos os modelos
Todos os modelos Planos Empresariais
Planos Empresariais Desenvolvimento de aplicações de IA
Desenvolvimento de aplicações de IA API de tradução de IA
API de tradução de IA Serviço de SEO/GEO com IA
Serviço de SEO/GEO com IA Serviço de Relações Públicas Otimizado por Geolocalização
Serviço de Relações Públicas Otimizado por Geolocalização Serviço de Web Scraping
Serviço de Web Scraping OpenClaw
OpenClaw Principais ferramentas de IA
Principais ferramentas de IA Os melhores robôs de IA
Os melhores robôs de IA
 Conecte-se
Conecte-se















Como blogueiro de tecnologia que passou as últimas 48 horas testando o Composer 2.5 em diversos projetos reais, trago aqui uma análise completa e prática. Abordaremos benchmarks, detalhes de treinamento, preços, experiências de usuários reais, comparações com o Claude Opus 4.7 e o GPT-5.5, e se este é o modelo que finalmente tornará os agentes de IA uma ferramenta essencial no dia a dia da engenharia de software profissional.
O que é o Composer 2.5? Breve contexto
A série Composer da Cursor foi desenvolvida especificamente para codificação agentiva Dentro do ambiente de desenvolvimento integrado Cursor (e sua interface Glass emergente). Ao contrário dos modelos de propósito geral acessados via API, os modelos do Composer são otimizados de ponta a ponta para o ambiente Cursor: edição de múltiplos arquivos, uso de ferramentas de terminal, navegação no código-fonte, depuração iterativa e tarefas de engenharia de software de longo prazo.
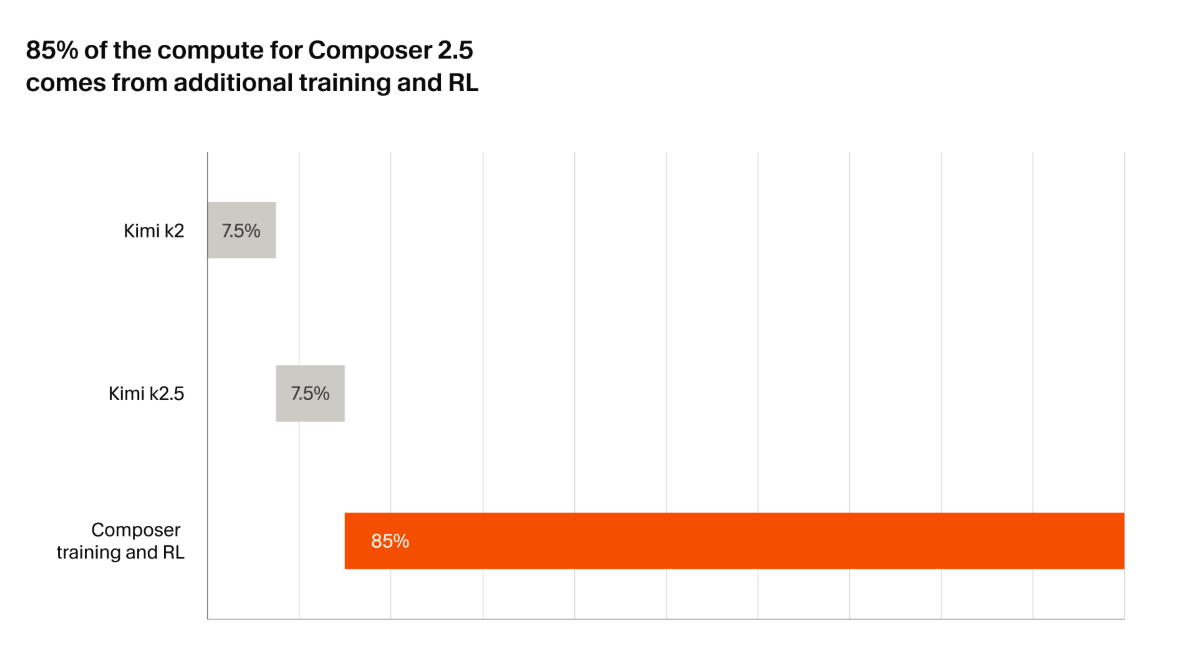
Compositor 2.5 Baseia-se diretamente na mesma IA Moonshot de código aberto. Como o K2.5 Ponto de verificação usado para o Composer 2. O Cursor relata gastar cerca de 85% do orçamento computacional total em pós-treinamento e aprendizado por reforço (RL), incluindo 25 vezes mais tarefas sintéticas do que a versão anterior.
Não se trata de um simples ajuste fino. Inclui novas técnicas como aprendizado por reforço direcionado com feedback textual, geração avançada de dados sintéticos e melhorias na infraestrutura para treinamento de Mistura de Especialistas (MoE).
Critérios de avaliação: quão bom é realmente?
A Cursor divulgou números expressivos para o Composer 2.5:
- SWE-Bench Multilíngue: 79,8% — correspondendo ao Opus 4.7 da Anthropic.
- CursorBench v3.1: 63,2% — competitivo com os melhores modelos de vanguarda.
- Bancada de terminais 2.0Melhorou, mas fica atrás do GPT-5.5 (que apresentou uma taxa de acerto de cerca de 69,3%, contra uma taxa maior do GPT).
Tabela comparativa (Aproximada com base em relatórios públicos):
| Referência | Compositor 2.5 | Opus 4.7 | GPT-5.5 | Ganhador |
|---|---|---|---|---|
| SWE-Bench Multilíngue | 79,8% | ~80% | ~78-80% | Gravata |
| CursorBench v3.1 | 63,2% | ~63-65% | ~59-63% | Gravata / Obra Leve |
| Bancada de terminais 2.0 | ~69,3% | ~69,4% | 82,7% | GPT-5.5 |
Esses resultados são impressionantes, especialmente considerando o custo. Benchmarks públicos como o SWE-Bench testam a resolução de problemas reais do GitHub em diversas linguagens, enquanto o CursorBench utiliza tarefas reais de engenharia interna da Cursor (prompts ambíguos, grandes alterações em vários arquivos).
Ponto principalO Composer 2.5 atinge a paridade em avaliações importantes de engenharia de software por uma fração do preço. Não é universalmente superior, mas oferece desempenho de ponta onde realmente importa para a maioria dos fluxos de trabalho de desenvolvedores.
Preços: O Verdadeiro Fator de Mudança
Padrão
$ 0,50
por M tokens de entrada
Saída padrão
$ 2,50
por M tokens de saída
Rápido (Padrão)
$ 3,00
por M de entrada / $15,00 de saída
Isso continua sendo consideravelmente mais barato do que os concorrentes. Para contextualizar, os planos do Claude Opus geralmente custam de US$ 5 a US$ 25 ou mais por mês, e o GPT-5.5 Pro tem um preço semelhante. A Cursor também dobrou o limite de uso na primeira semana após o lançamento.
As estimativas de custo por tarefa, feitas por analistas, colocam o Composer 2.5 em menos de US$ 1 para muitas ações típicas de engenharia, em comparação com vários dólares para qualidade equivalente no Opus ou GPT. Isso cria uma poderosa fronteira de Pareto: inteligência quase perfeita a 1/10 do custo.
Testes práticos: o que eu construí com o Composer 2.5
Testei o Composer 2.5 em três projetos reais:
- Implementação de funcionalidades Full-Stack (Next.js 15 + TypeScript + Supabase + Tailwind)
- Tarefa: Criar um aplicativo de gerenciamento de tarefas com inteligência artificial, colaboração em tempo real, Kanban com recurso de arrastar e soltar e exportação para PDF.
- Resultado: O Composer 2.5 lidou excepcionalmente bem com a geração de código com múltiplos arquivos. Criou políticas RLS do Supabase corretas, implementou atualizações de interface do usuário otimistas e configurou uma biblioteca de componentes shadcn/ui limpa. Sucesso na primeira tentativa na maioria dos arquivos. Pequenos ajustes foram necessários para fluxos de autenticação em casos extremos. A velocidade no modo Rápido foi "impressionante" — as gerações pareceram de 3 a 5 vezes mais rápidas do que o Opus em tarefas semelhantes.
- Grande refatoração de código (Monólito Python/FastAPI legado, ~120 mil linhas de código)
- Tarefa: Migrar a autenticação de JWT personalizado para Auth0, atualizar mais de 40 arquivos e adicionar testes abrangentes.
- Resultado: Desempenho sólido. Identificou corretamente as cadeias de dependência e realizou alterações consistentes entre os módulos. Ocasionalmente, precisou de pequenos ajustes nas asserções de teste, mas se recuperou bem. O gerenciamento de contextos longos (mais de 200 mil tokens) mostrou-se confiável. Melhor "calibração de esforço" do que as versões anteriores — não editou arquivos não relacionados em excesso.
- Terminal + Fluxo de Trabalho Agente (Depuração de microsserviços em Docker)
- Tarefa: Diagnosticar e corrigir um problema de rede em uma configuração de 5 serviços com Redis, Postgres e um backend em Go.
- Resultado: Excelente uso de ferramentas e depuração iterativa. Foi proposto.
docker composeOs comandos foram executados, os registros foram inspecionados de forma inteligente e a iteração foi rápida. As melhorias no Terminal-Bench ficaram evidentes aqui, embora o GPT-5.5 ainda pareça mais robusto para orquestração de shell muito complexa.
Impressões subjetivas:
- Velocidade e capacidade de respostaA variante rápida é uma maravilha. A baixa latência transforma o fluxo de trabalho de "esperar pela IA" para "emparelhamento conversacional".
- Instruções a seguirApresenta desempenho notavelmente melhor em instruções complexas e com várias etapas. Menos erros de inicialização em chamadas de ferramentas.
- Estilo de comunicaçãoMais calmo, mais natural. Menos confiança ilusória, melhor em dizer "Preciso de mais informações aqui".
- Confiabilidade em tarefas de longa duraçãoA maior vantagem. Mantém o foco por mais de 50 turnos.
Análise Detalhada do Treinamento: O Que Torna o 2.5 Diferente
A abordagem técnica da Cursor se destaca:
- Aprendizagem por reforço direcionada com feedback textualResolve a atribuição de créditos em implementações de longa duração inserindo dicas localizadas para erros específicos (por exemplo, chamadas de ferramentas inválidas). Isso melhora o desempenho sem recompensas globais ruidosas.
- Dados sintéticos massivos25 vezes mais tarefas, incluindo a "exclusão de funcionalidades", onde o agente deve reimplementar a funcionalidade removida, mantendo os testes passando. Isso gera problemas complexos e verificáveis, baseados em códigos reais.
- Infraestrutura VenceOtimizador de múons fragmentado, HSDP de malha dupla para MoE, pipelines de RL assíncronos — permitindo escalonamento eficiente em grandes clusters (incluindo treinamento parcial no Colossus 2).
Eles já estão em parceria com a xAI/SpaceXAI para um modelo muito maior, desenvolvido do zero, usando 10 vezes mais poder computacional.
A história do Kimi K2.5: Transparência e controvérsia
Assim como o Composer 2, o 2.5 usa o Kimi K2.5 da Moonshot como base, com um sistema de aprendizado por reforço (RL) específico para o Cursor. Os lançamentos iniciais geraram debates sobre a atribuição, mas desde então a Cursor tem se mostrado mais transparente, e a Moonshot reconheceu parcerias comerciais por meio de plataformas como o Fireworks.
Essa abordagem híbrida (base aberta robusta + aprendizado por reforço específico do domínio) está se tornando cada vez mais comum e eficaz. O resultado final parece perfeitamente otimizado para os fluxos de trabalho de agentes do Cursor.
Quem deve usar o Composer 2.5?
Sim — Alternar ou priorizar se:
- Você quer o máximo de iterações por dólar.
- Seu fluxo de trabalho envolve muitas tarefas com múltiplos arquivos, que exigem interação com agentes ou que são de longa duração.
- Você valoriza a rapidez e a colaboração agradável em detrimento do raciocínio absolutamente preciso nos problemas mais difíceis.
- Você está trabalhando com um orçamento de equipe (reduções drásticas de custos são facilmente escaláveis).
Continue usando Opus/GPT para:
- Arquitetura inovadora ultracomplexa ou raciocínio de nível de pesquisa.
- Tarefas em que o domínio do shell no estilo Terminal-Bench é fundamental.
- Máximo sucesso em uma única tentativa em problemas ambíguos e de alto risco (embora a diferença esteja diminuindo rapidamente).
Muitos desenvolvedores relatam usar o Composer 2.5 como a ferramenta principal padrão, enquanto encaminham as subtarefas mais complexas para modelos premium — uma estratégia híbrida inteligente.
Prós e contras
Vantagens
- Relação preço/desempenho incrível.
- Modo extremamente rápido.
- Melhoria na confiabilidade e no desempenho em tarefas de longa duração.
- Excelente capacidade de edição de múltiplos arquivos e compreensão do código-fonte.
- Promoção de uso dobrado (verifique os limites atuais).
Limitações
- Ainda apresenta ligeiras desvantagens em alguns benchmarks de terminal/agente.
- Acesso restrito ao IDE (ainda sem API pública).
- Ocasionalmente, há necessidade de mais orientação sobre lógica muito inovadora ou casos extremos.
- As origens do modelo base continuam a suscitar debates em algumas comunidades.
Veredicto final
9.2/10
Para a maioria dos desenvolvedores
Compositor 2.5 Esta é a afirmação mais contundente até o momento de que modelos especializados e pós-treinados de forma eficiente podem entregar resultados de ponta a preços acessíveis. Embora não supere universalmente o Claude Opus 4.7 ou o GPT-5.5, ele se equipara a eles de forma bastante precisa nas métricas que importam para 80% do trabalho real — custando uma fração do preço e proporcionando uma sensação de maior velocidade no processo.
Para desenvolvedores individuais, startups e equipes que trabalham em processos iterativos de desenvolvimento de produtos, essa é uma ferramenta potencialmente essencial para o dia a dia, capaz de mudar a economia da engenharia assistida por IA. O modelo maior, que será desenvolvido em breve com a computação xAI, poderá impulsionar ainda mais esse cenário.
Se você já usa o Cursor, habilite o Composer 2.5 (Fast por padrão) e experimente hoje mesmo — especialmente enquanto durar o desconto de uso dobrado. Para todos os outros, é mais um motivo convincente para considerar seriamente o Cursor.
Você já experimentou o Composer 2.5? Compartilhe sua experiência nos comentários — o que funcionou, o que não funcionou e como ele se compara ao seu conjunto de ferramentas. Atualizarei esta publicação com mais dados de usuários e testes complementares.