 OpenAI - ChatGPT、Sora
OpenAI - ChatGPT、Sora Google - Gemini,Nano Banana
Google - Gemini,Nano Banana Anthropic - Claude
Anthropic - Claude xAI - Grok
xAI - Grok DeepSeek
DeepSeek 阿里巴巴 - Qwen
阿里巴巴 - Qwen 字节跳动 - 豆包
字节跳动 - 豆包 所有型号
所有型号 企业API定制计划
企业API定制计划 AI应用开发服务
AI应用开发服务 AI智能翻译API
AI智能翻译API AI SEO/GEO 服务
AI SEO/GEO 服务 GEO/AI大模型优化
GEO/AI大模型优化 网络爬虫服务
网络爬虫服务 OpenClaw
OpenClaw 顶级人工智能工具
顶级人工智能工具 顶级人工智能机器人
顶级人工智能机器人
 登录
登录

















这是自2025年1月R1版本震惊全球市场以来,DeepSeek最重要的一次版本发布。以下是您需要了解的所有信息。
什么是 DeepSeek V4?
DeepSeek V4 是总部位于杭州的人工智能实验室 DeepSeek 推出的第四代旗舰模型系列。DeepSeek 于 2025 年 1 月凭借低成本的 R1 推理模型震撼了全球市场。V4 将取代 DeepSeek V3 和 V3.2,这两款模型将于 2026 年 7 月 24 日之后停产。
DeepSeek V4 是一个基于混合专家 (MoE) 架构的双模型版本。两个模型均支持 100 万个令牌的上下文窗口,最大输出 38.4 万个令牌,并且均以 MIT 许可证发布——这意味着可以免费用于商业用途,并且可以在 Hugging Face 上访问完整的权重。
DeepSeek-V4-Pro 是旗舰版本:总参数量 1.6 万亿,每个Tokens 490 亿个活跃参数,预训练数据为 33 万亿个Tokens。DeepSeek-V4-Flash 是高效版本:总参数量 2840 亿,每个Tokens 130 亿个活跃参数,训练数据为 32 万亿个Tokens。
这使得 DeepSeek-V4-Pro 成为目前市面上尺寸最大的开放式配重型号。它比 Kimi K2.6 (1.1T) 和 GLM-5.1 (754B) 更大,是 DeepSeek V3.2 (685B) 的两倍多。
这两个模型目前都处于预览阶段。路透社报道称,DeepSeek正在利用预览期收集真实世界的反馈意见,然后再最终确定模型,但并未提供最终定稿的时间表。
使这一切成为可能的架构
DeepSeek V4 并非 V3 的简单放大版。V4 引入了三项架构上的改进,使其与 V3.2 截然不同:CSA+HCA 混合注意力机制、流形约束超连接 (mHC) 以及 Muon 优化器。这些改进共同解释了为何如此庞大的模型能够以远低于 V3.2 的推理成本运行。
混合注意力:CSA + HCA
V4 攻击的核心工程问题是长上下文下的注意力成本。标准的 Transformer 注意力机制的计算量与序列长度呈二次方关系——对于这种规模的模型来说,在处理 100 万个 token 时运行它,在经济上是无法承受的。
核心创新在于一种混合注意力机制,它在Transformer层中交错使用压缩稀疏注意力(CSA)和重压缩注意力(HCA)。CSA使用学习到的词级压缩器将每m个词元的键值缓存压缩成单个条目,然后应用查询相关的top-k键值选择。HCA则进一步压缩那些能够容忍更大近似值的层。
实际结果令人瞩目。在 100 万个令牌的场景下,DeepSeek-V4-Pro 仅需 单词推理 FLOPs 的 27%。 和 10% 的 KV 缓存 与 DeepSeek-V3.2 相比,V4-Flash 将 FLOPs 提升至 10%,KV 缓存提升至 7%。
关键在于,仅靠 CSA 或 HCA 都无法达到这样的效率——交错混合算法能够在保持长上下文质量的同时,将 FLOPs 和 KV 缓存降低一个数量级。
流形约束超连接(mHC)
mHC 解决了深度神经网络训练中的一个根本问题:随着模型层数增长到数百甚至数千层,标准的残差连接会导致信号传播不稳定。mHC 使用 Sinkhorn-Knopp 算法将混合矩阵约束到 Birkhoff 多面体,从而保持网络内部信号幅度的稳定。简而言之:它能够使万亿参数的训练保持稳定,而之前的架构则会出现发散现象。
缪子优化器
V4 使用 Muon 优化器进行训练,该优化器应用牛顿-舒尔茨迭代法对梯度更新矩阵进行近似正交化,然后再将其作为权重更新。与 AdamW 相比,Muon 能够实现更快的收敛速度和更高的训练稳定性——这在训练 1.6T 参数规模的模型时尤为重要,因为优化器的不稳定性会造成灾难性后果。
三种推理模式
每个 V4 模型都展现了三种推理难度级别: 非思考, 志存高远, 和 思考麦克斯Max 模式在强化学习中使用更长的上下文并降低长度惩罚,是处理最难推理任务的理想模式。差异显著:在 HLE 数据集上,V4-Pro 的得分从 7.7(非思考模式)提升到 37.7(Max 模式)——仅仅通过增加推理计算资源,同一模型的得分就提升了近 5 倍。
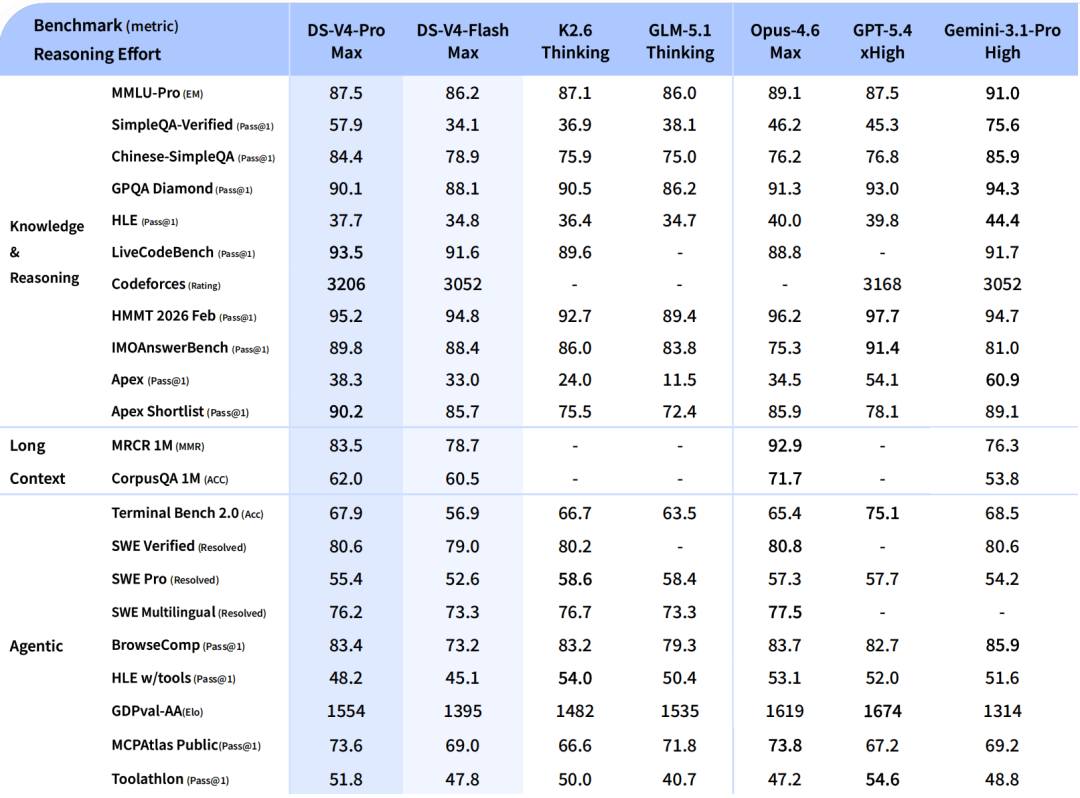
DeepSeek V4 基准测试:全面概览
V4-Pro-Max 得分 SWE-bench 验证通过率 80.6% 和 LiveCodeBench 得分 93.5 — 目前所有模型中编码基准测试得分最高。
竞争环境在此至关重要。Claude Opus 4.6 在 SWE-bench Verified 测试中略微领先(80.8% 对 80.6%),但在 HLE(40.0% 对 37.7%)和 HMMT 2026 数学测试(96.2% 对 95.2%)中则拥有显著优势。V4-Pro 每百万个输出Tokens的成本仅为 V4-Pro 的七分之一。
在形式数学方面,V4 的表现堪称卓越。在结合了非正式推理、形式验证和更高计算量的 Putnam-2025 测试中,V4 取得了完美的 120/120 分,与 Axiom 并驾齐驱,并超越了 Aristotle (100/120) 和 Seed-1.5-Prover (110/120)。在竞赛数学基准测试中,V4-Pro-Max 在 HMMT 2026 February 测试中取得了 95.2 分,在 IMOAnswerBench 测试中取得了 89.8 分,其性能已接近 GPT-5.4。
在竞技编程方面,V4-Pro 的 Codeforces 评分为 3,206,在人类竞争者中排名第 23 位。
V4-Pro-Max 落后于领先者的方面:在大多数知识密集型基准测试中,包括 MMLU-Pro、SimpleQA、GPQA Diamond 和 HLE,V4-Pro-Max 的表现均逊于 Gemini 3.1 Pro。差距已大幅缩小,但尚未完全消除。
DeepSeek V4 与 GPT-5.5、Claude Opus 4.7 和 Gemini 3.1 Pro 的对比
| 指标 | DeepSeek V4-Pro | GPT-5.5 | Claude作品 4.7 | Gemini 3.1 Pro |
|---|---|---|---|---|
| SWE-bench 已验证 | 80.6% | — | 80.8% | — |
| LiveCodeBench | 93.5 | — | — | — |
| Codeforces 评分 | 3,206 | — | — | 3,052 |
| HMMT 2026年2月 | 95.2% | — | 96.2% | — |
| 终端工作台 2.0 | 67.9% | 82.7% | 69.4% | 68.5% |
| API 输出价格/100万 | 3.48美元 | 30.00美元 | 75.00美元 | — |
| 上下文窗口 | 100万个Tokens | 100万个Tokens | 100万个Tokens | 100万个Tokens |
| 开源 | ✓ 附带 | ✗ | ✗ | ✗ |
| 自托管 | ✓ | ✗ | ✗ | ✗ |
V4 Pro 型号的输入Tokens成本为每百万个Tokens 0.145 美元,输出Tokens成本为每百万个Tokens 3.48 美元,低于 Gemini 3.1 Pro、GPT-5.5、Claude Opus 4.7 和 GPT-5.4。在这个价位上,闭源竞争对手很难与之匹敌。
DeepSeek-V4-Pro 在标准推理基准测试中表现出优于 GPT-5.2 和 Gemini 3.0 Pro 的性能,但其性能略逊于 GPT-5.4 和 Gemini 3.1 Pro,这表明其发展轨迹比最先进的前沿模型落后约 3 到 6 个月。
定价:改变一切的数字
较小的 V4-Flash 型号每百万输入令牌的成本为 0.14 美元,每百万输出令牌的成本为 0.28 美元,低于 GPT-5.4 Nano、Gemini 3.1 Flash、GPT-5.4 Mini 和 Claude Haiku 4.5。
在缓存未命中率下,V4-Pro 的成本约为 GPT-5.5 的七分之一,约为 Claude Opus 4.7 的六分之一,吞吐量相当。
V4-Pro-Max 每百万个输出Tokens售价 3.48 美元,其 SWE-bench 性能与 Claude Opus 4.6(每百万个输出Tokens售价 75 美元)的差距仅为 0.2 分。 成本降低 21 倍 在几乎相同的编码基准性能下,对于每天运行数千个智能编码任务的团队来说,这改变了经济可行性的考量。
对于大批量使用场景,V4-Flash 的定价尤其值得关注。Flash 和 Pro 之间的差距很小——Flash 在大多数基准测试中仅损失大约 1-2 分,但 API 成本却降低了 12 倍。对于大多数不需要极致推理性能的生产应用而言,V4-Flash 是经济实惠的首选方案。
如何立即访问 DeepSeek V4
DeepSeek V4 可通过三种方式获取。首先,通过 chat.deepseek.com — 该网页聊天机器人通过两个开关公开 V4 版本:专家模式 (V4-Pro) 和即时模式 (V4-Flash)。其次,通过 DeepSeek API 使用模型 ID。 deepseek-v4-pro 和 deepseek-v4-flash第三,这些权重以 MIT 许可证在 Hugging Face 上开源,允许免费商业使用和本地部署。
两种模型均支持 100 万种情境和双模式(思考模式和非思考模式)。请注意: 深度搜索聊天 和 deepseek-reasoner 之后将完全退役且无法进入 2026年7月24日使用现有别名的开发者应在此截止日期前迁移到明确的 V4 模型 ID。
V4-Pro 和 V4-Flash 都支持 OpenAI ChatCompletions 格式和 Anthropic API 格式。对于大多数团队而言,这意味着集成只需更新模型参数即可,无需更改基本 URL。
对于自托管:V4-Flash 的权重是实际可行的自托管目标。V4-Flash 参数量为 2840 亿,每个令牌激活 130 亿,因此可以在大多数中型团队能够负担得起的多 GPU 配置上运行。V4-Pro 总参数量为 1.6 万亿,需要大量的集群容量才能达到生产级延迟——大多数团队会使用 DeepSeek API 来处理 Pro 部分,而只考虑对 Flash 部分进行自托管。
DeepSeek V4 的不足之处
诚实的分析需要承认 DeepSeek 自身记录的真正局限性。
V4 Flash 和 V4 Pro 都只支持文本,这与许多闭源同类产品不同,后者支持理解和生成音频、视频和图像。对于多模态应用,V4 目前不具备竞争力。
在知识密集型任务方面,V4 与前沿闭源模型之间的差距依然存在。DeepSeek 在技术报告中坦率地指出了 V4 的剩余局限性:在大多数知识密集型基准测试中,V4-Pro-Max 的表现逊于 Gemini 3.1 Pro。尽管差距已大幅缩小,但尚未完全消除。
对于处于绝对前沿的智能体工作流程,V4-Pro-Max 在 SWE Verified (80.6) 测试中与领先者并驾齐驱,但在 SWE Pro (55.4) 和 Terminal-Bench 2.0 测试中落后。对于处于前沿的纯智能体编码,GPT-5.5 和 Opus 4.7 仍然更胜一筹。
DeepSeek 也承认架构的复杂性是其自身认定的一个限制——该团队将 V4 架构描述为“相对复杂”,并表示未来的版本将力求将其简化为最基本的设计。
你无法忽视的地缘政治层面
DeepSeek V4 的发布并非孤立事件。就在美国指责中国利用数千个代理账户大规模窃取美国人工智能实验室知识产权的第二天,DeepSeek 便发布了该版本。而 Anthropic 和 OpenAI 也指责 DeepSeek “提炼”——实际上是抄袭——他们的 AI 模型。
硬件方面同样意义重大。DeepSeek与中国科技巨头华为达成合作,华为确认将通过其“超级节点”技术为这家人工智能初创公司提供支持,该技术将大量Ascend 950芯片组合成集群,从而提供更强大的计算能力。
“它使得人工智能系统的构建和部署不再完全依赖英伟达,因此 V4 最终可能会比 R1 产生更大的影响——加速国内的普及应用,并促进全球人工智能的整体快速发展。”
——孙伟,Counterpoint Research首席分析师晨星公司高级股票分析师苏伊凡(Ivan Su)告诉CNBC,V4的发布不太可能像R1那样对市场产生巨大影响,因为交易员们已经消化了中国人工智能具有竞争力且使用成本更低的现实。然而,DeepSeek最新的定位将其他中国开源模型视为直接竞争对手。 “这是R1时代所没有的框架,仅此一点就足以说明国内竞争已经加剧了多少。”
哪些用户应该使用DeepSeek V4?
您正在大规模运行编码代理、多步骤推理管道或复杂的文档分析。SWE-bench 的性能与 Claude Opus 4.6 的性能相差无几,而成本却低得多。
您需要成本优化、高容量的推理,同时又不能牺牲太多质量。Flash 的每百万个输出令牌成本仅为 0.28 美元,是生产工作负载中最具成本效益的前沿模型。
如果您有数据主权要求、受出口管制限制,或者希望完全掌控推理堆栈,那么 MIT 许可证和 Hugging Face 的可用性将使之真正易于获取。
您的工作流程依赖于多模态输入,您需要代理计算机使用任务的绝对前沿技术,或者您的应用程序涉及敏感数据,而托管在中国的公司会引发合规性问题。
常见问题解答
DeepSeek V4 是 DeepSeek 的第四代旗舰型号,于 2026 年 4 月 24 日发布。它有两个版本——V4-Pro(1.6T 参数,49B 活动)和 V4-Flash(284B 参数,13B 活动)——两者都支持 100 万个令牌上下文窗口,并采用 MIT 开源许可证。
在 SWE-bench Verified 和 LiveCodeBench 等编码基准测试中,V4-Pro-Max 与 GPT-5.5 性能相当甚至更胜一筹。但在 Terminal-Bench 2.0 等智能体计算机使用基准测试中,GPT-5.5 则显著领先(82.7% 对 67.9%)。关键区别在于价格:V4-Pro 每百万个输出Tokens的成本为 3.48 美元,而 GPT-5.5 则为 30 美元。
V4-Flash 的成本为每百万个输入令牌 0.14 美元,每百万个输出令牌 0.28 美元。V4-Pro 的成本为每百万个输入令牌 1.74 美元,每百万个输出令牌 3.48 美元。两者都比同类闭源产品便宜得多。
是的。V4-Pro 和 V4-Flash 均以 MIT 许可证发布,Hugging Face 上提供了完整的权重文件。您可以下载、运行这些模型,并将其用于商业用途,无需支付额外的许可费用。
模型权重可免费下载并自行托管。chat.deepseek.com 上的网页界面免费访问。API 使用按上述费率收费。
两者都将于 2026 年 7 月 24 日弃用并完全停用。它们现在分别映射到非思考模式和思考模式下的 deepseek-v4-flash。开发者应迁移到明确的 V4 模型 ID。
V4-Flash(总参数 284B,Hugging Face 上 160GB)是拥有多 GPU 配置的团队进行本地部署的理想选择。V4-Pro(865GB)需要大量的集群资源才能达到生产级的低延迟。
V4版本仅支持文本输入,暂不支持音频、图像和视频处理。
DeepSeek V4 并非在所有基准测试中都能超越 GPT-5.5 或 Claude Opus 4.7,但它也无需如此。其核心优势在于经济性:接近前沿的编码和推理性能、宽松许可下的开源权重,以及比闭源替代方案低 7 到 21 倍的 API 定价。
对于大多数使用 LLM 进行构建的开发者和企业来说,问题从来都不是“哪个模型在基准测试中得分最高?”而是始终 “哪种模式能够在保证产品质量的前提下,将产品成本控制在可接受的范围内?” DeepSeek V4 显著改变了现实世界中相当一部分应用场景的计算方式。
Counterpoint Research 的研究副总裁 Neil Shah 将 V4 描述为“一次重大突破”,并指出其推理成本低于之前的模型。这一评价依然成立。DeepSeek 完成了一项大多数观察人士在 18 个月前认为不太可能的事情:在受限硬件上构建并发布了一款真正具有竞争力的开源模型,其定价足以改变企业的采购决策,并且向全球用户开放了模型权重。
人工智能竞赛并未放缓,但其成本显然正在降低。
DeepSeek 官方 API 文档 · Hugging Face 模型卡 · CNBC · TechCrunch · 路透社 · CNN 商业频道 · BuildFastWithAI · Morph LLM · Digital Applied · FelloAI · Kingy AI