 OpenAI - ChatGPT, Sora
OpenAI - ChatGPT, Sora Google - Gemini, Nano Banana
Google - Gemini, Nano Banana Антропический - Клод
Антропический - Клод xAI - Grok
xAI - Grok Глубокий поиск
Глубокий поиск Alibaba - Qwen
Alibaba - Qwen ByteDance - Лучшее от ByteDance
ByteDance - Лучшее от ByteDance Все модели
Все модели Планы предприятия
Планы предприятия Разработка приложений на основе искусственного интеллекта
Разработка приложений на основе искусственного интеллекта API для перевода с помощью ИИ
API для перевода с помощью ИИ Услуги SEO/ГЕ с использованием ИИ
Услуги SEO/ГЕ с использованием ИИ Географически оптимизированная PR-служба
Географически оптимизированная PR-служба Сервис веб-скрейпинга
Сервис веб-скрейпинга OpenClaw
OpenClaw Лучшие инструменты ИИ
Лучшие инструменты ИИ Лучшие роботы с искусственным интеллектом
Лучшие роботы с искусственным интеллектом
 Авторизоваться
Авторизоваться
















Это самый значительный релиз DeepSeek с тех пор, как R1 потряс мировые рынки в январе 2025 года. Вот все, что вам нужно знать.
Что такое DeepSeek V4?
DeepSeek V4 — это флагманское семейство моделей четвертого поколения от DeepSeek, расположенной в Ханчжоу лаборатории искусственного интеллекта, которая в январе 2025 года произвела фурор на мировых рынках благодаря недорогой модели логического мышления R1. V4 заменяет DeepSeek V3 и V3.2, которые будут сняты с производства после 24 июля 2026 года.
DeepSeek V4 — это двухмодельная версия, построенная на архитектуре «смешанных экспертов» (Mixture-of-Experts, MoE). Обе модели поддерживают контекстное окно в 1 миллион токенов с максимальным выходом в 384 000 токенов, и обе распространяются под лицензией MIT, что означает бесплатное коммерческое использование и полный доступ к весам на Hugging Face.
DeepSeek-V4-Pro — флагманская модель: 1,6 триллиона параметров, 49 миллиардов активных токенов на токен, предварительно обучена на 33 триллионах токенов. DeepSeek-V4-Flash — модель, ориентированная на эффективность: 284 миллиарда параметров, 13 миллиардов активных токенов на токен, обучена на 32 триллионах токенов.
Таким образом, DeepSeek-V4-Pro становится самой большой моделью с открытыми грузиками из доступных на рынке. Она больше, чем Kimi K2.6 (1,1 Тл) и GLM-5.1 (754 Бл), и более чем в два раза превышает размер DeepSeek V3.2 (685 Бл).
Обе модели в настоящее время находятся на стадии предварительного просмотра. Агентство Reuters сообщило, что DeepSeek использует период предварительного просмотра для сбора отзывов от реальных пользователей перед окончательной доработкой модели, и не предоставило сроков завершения разработки.
Архитектура, которая делает это возможным
DeepSeek V4 — это не просто увеличенная версия V3. V4 вносит три архитектурных изменения, которые отличают её от V3.2: гибридный механизм внимания CSA+HCA, гиперсвязи с ограничениями на многообразии (mHC) и оптимизатор Muon. Вместе они объясняют, как такая большая модель может работать с гораздо меньшими затратами на вывод, чем V3.2.
Гибридное внимание: CSA + HCA
Основная инженерная проблема, решаемая V4, — это стоимость внимания при работе с длинным контекстом. Стандартное внимание трансформеров масштабируется квадратично с длиной последовательности — запуск модели такого размера с 1 миллионом токенов был бы экономически нецелесообразен.
Ключевое нововведение — это гибридный механизм внимания, который чередует сжатое разреженное внимание (CSA) и сильно сжатое внимание (HCA) в слоях трансформера. CSA сжимает кэш «ключ-значение» для каждых m токенов в одну запись с помощью обученного компрессора на уровне токенов, а затем применяет зависящий от запроса выбор k лучших значений «ключ-значение». HCA обеспечивает дальнейшее сжатие для слоев, допускающих более высокую степень аппроксимации.
Практический результат впечатляет. В контексте с 1 миллионом токенов DeepSeek-V4-Pro требует всего лишь... 27% операций вывода с одним токеном и 10% кэша KV По сравнению с DeepSeek-V3.2, V4-Flash позволяет достичь еще более высоких показателей: 10% от общего числа операций с плавающей запятой и 7% от объема кэша ключ-значение.
Ключевой вывод заключается в том, что показатели эффективности недостижимы ни с помощью CSA, ни с помощью HCA по отдельности — именно чередующийся гибридный подход обеспечивает сохранение качества долговременного контекста, одновременно снижая количество операций с плавающей запятой и размер кэша ключ-значение на порядок.
Гиперсвязи с ограничениями на уровне многообразий (mHC)
mHC решает фундаментальную проблему в обучении глубоких нейронных сетей: по мере роста моделей до сотен или тысяч слоев стандартные остаточные связи создают нестабильность распространения сигнала. mHC ограничивает матрицы смешивания политопом Биркхофа с помощью алгоритма Синкхорна-Кноппа, который сохраняет величину сигнала в сети. Проще говоря: он обеспечивает стабильность обучения с триллионом параметров, в то время как предыдущие архитектуры давали бы сбой.
Оптимизатор мюонов
V4 обучается с использованием оптимизатора Muon, который применяет итерации Ньютона-Шульца для приблизительной ортогонализации матрицы обновления градиента перед применением ее в качестве обновления весов. По сравнению с AdamW, Muon обеспечивает более быструю сходимость и большую стабильность обучения — что особенно важно при обучении модели с 1,6T параметрами, где нестабильность оптимизатора была бы катастрофической.
Три режима рассуждения
Каждая модель V4 предлагает три уровня сложности рассуждений: Не-Мыслить, Думай высоко, и Думай, МаксВ режиме Max используются более длинные контексты и уменьшены штрафы за длину в задачах обучения с подкреплением, и именно этот режим следует использовать для самых сложных задач рассуждения. Разница существенна: в HLE V4-Pro показывает результат от 7,7 (без размышлений) до 37,7 (Max) — почти пятикратный скачок по сравнению с той же моделью просто за счет выделения большего объема вычислительных ресурсов для рассуждений.
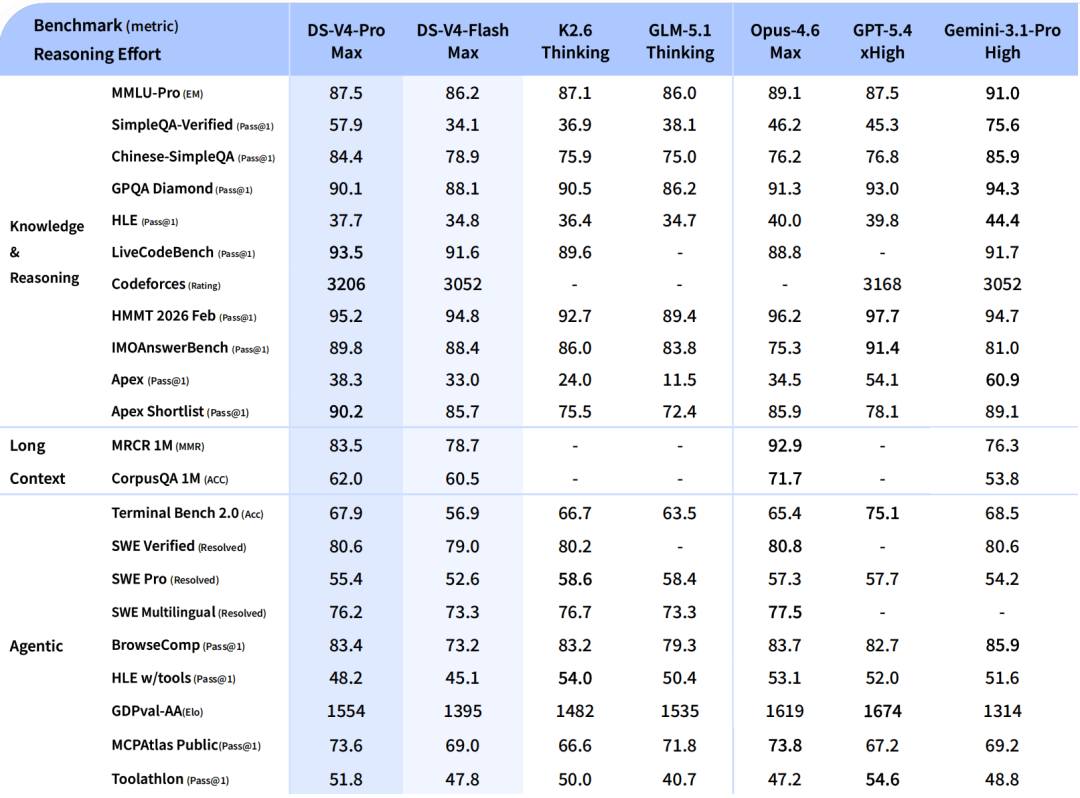
Результаты тестов DeepSeek V4: полная картина
Показатели V4-Pro-Max 80,6% подтверждено на SWE-bench и 93,5 на LiveCodeBench — наивысший результат в тестах на точность кодирования среди всех доступных в настоящее время моделей.
В данном случае важен контекст конкуренции. Claude Opus 4.6 имеет незначительное преимущество перед SWE-bench Verified (80,8% против 80,6%) и существенное преимущество перед HLE (40,0% против 37,7%) и HMMT 2026 math (96,2% против 95,2%). Стоимость V4-Pro в 7 раз ниже за миллион токенов.
В области формальной математики результаты исключительны. На Putnam-2025, который сочетает неформальные рассуждения с формальной проверкой и более сложными вычислениями, V4 достигает безупречного доказательства 120/120, сравнявшись с Axiom и опередив Aristotle (100/120) и Seed-1.5-Prover (110/120). В математических бенчмарках для соревнований HMMT 2026 (февраль) с результатом 95,2 и IMOAnswerBench (89,8) V4-Pro-Max находится в пределах диапазона GPT-5,4.
В соревновательном программировании V4-Pro получает рейтинг Codeforces: 3206, 23-е место среди участников-людей.
В чем V4-Pro-Max отстает от лидеров: V4-Pro-Max уступает Gemini 3.1 Pro в большинстве ресурсоемких тестов, включая MMLU-Pro, SimpleQA, GPQA Diamond и HLE. Разрыв существенно сократился, но не исчез полностью.
Сравнение DeepSeek V4, GPT-5.5, Claude Opus 4.7 и Gemini 3.1 Pro
| Метрическая система | DeepSeek V4-Pro | ГПТ-5.5 | Клод Опус 4.7 | Gemini 3.1 Pro |
|---|---|---|---|---|
| Проверено с помощью SWE-bench | 80,6% | — | 80,8% | — |
| LiveCodeBench | 93,5 | — | — | — |
| Рейтинг Codeforces | 3206 | — | — | 3052 |
| HMMT 2026 февраль | 95,2% | — | 96,2% | — |
| Терминальный стенд 2.0 | 67,9% | 82,7% | 69,4% | 68,5% |
| Цена выходных данных API / 1 млн. | 3,48 доллара | 30,00 долларов | 75,00 долларов США | — |
| Контекстное окно | 1 млн токенов | 1 млн токенов | 1 млн токенов | 1 млн токенов |
| Открытый исходный код | ✓ С | ✗ | ✗ | ✗ |
| Самостоятельное размещение | ✓ | ✗ | ✗ | ✗ |
Модель V4 Pro стоит 0,145 доллара за миллион входных токенов и 3,48 доллара за миллион выходных токенов, что дешевле, чем Gemini 3.1 Pro, GPT-5.5, Claude Opus 4.7 и GPT-5.4. Расчет соотношения производительности и цены при такой стоимости представляет собой сложную задачу для конкурентов с закрытым исходным кодом.
DeepSeek-V4-Pro демонстрирует превосходные результаты по сравнению с GPT-5.2 и Gemini 3.0 Pro в стандартных тестах логического мышления, хотя его производительность немного уступает GPT-5.4 и Gemini 3.1 Pro, что указывает на то, что разработка этой модели отстает от передовых моделей примерно на 3-6 месяцев.
Цена: цифра, которая меняет всё.
Меньшая по размеру модель V4-Flash стоит 0,14 доллара за миллион входных токенов и 0,28 доллара за миллион выходных токенов, что дешевле, чем GPT-5.4 Nano, Gemini 3.1 Flash, GPT-5.4 Mini и Claude Haiku 4.5.
При частоте промахов кэша V4-Pro обходится примерно в одну седьмую часть от GPT-5.5 и около одной шестой части от Claude Opus 4.7 при эквивалентной пропускной способности.
V4-Pro-Max по цене 3,48 доллара за миллион токенов обеспечивает производительность в SWE-bench, отличающуюся всего на 0,2 пункта от Claude Opus 4.6 по цене 75 долларов за миллион токенов. Это 21-кратное снижение затрат При практически идентичных результатах в тестах на программирование. Для команд, выполняющих тысячи задач по программированию с использованием агентов в день, это меняет представление об экономической целесообразности.
Ценовая политика V4-Flash заслуживает особого внимания для сценариев с большими объемами данных. Разница между Flash и Pro невелика — Flash уступает примерно 1-2 пункта в большинстве бенчмарков в обмен на 12-кратное снижение стоимости API. Для большинства производственных приложений, не требующих максимальной производительности, V4-Flash является оптимальным экономическим вариантом по умолчанию.
Как получить доступ к DeepSeek V4 уже сегодня
DeepSeek V4 доступен тремя способами. Во-первых, через chat.deepseek.com — Веб-чат-бот предоставляет доступ к V4 через два переключателя: экспертный режим (V4-Pro) и мгновенный режим (V4-Flash). Во-вторых, через API DeepSeek с использованием идентификаторов моделей. deepseek-v4-pro и deepseek-v4-flashВо-третьих, в виде открытых весов в Hugging Face под лицензией MIT, что позволяет использовать их в коммерческих целях и развертывать локально.
Обе модели поддерживают контекст 1M и два режима (мышление и немышление). Обратите внимание, что deepseek-chat и deepseek-reasoner После этого он будет полностью выведен из эксплуатации и станет недоступным. 24 июля 2026 г.Разработчикам, использующим существующие псевдонимы, следует перейти на явные идентификаторы моделей V4 до указанного срока.
И V4-Pro, и V4-Flash поддерживают формат OpenAI ChatCompletions и формат Anthropic API. Для большинства команд это означает, что интеграция требует лишь обновления параметра модели — изменение базового URL-адреса не требуется.
Для самостоятельного размещения: весовые коэффициенты V4-Flash являются практической целью для самостоятельного размещения. При 284 байтах параметров с 13 байтами активированных параметров на токен, V4-Flash может работать на многопроцессорной конфигурации, доступной большинству средних команд. V4-Pro с общим количеством параметров 1,6 ТБ требует значительной мощности кластера для обеспечения задержки в производственной среде — большинство команд будут использовать API DeepSeek для Pro и рассматривать самостоятельное размещение только для Flash.
В чём недостатки DeepSeek V4
Для честного анализа необходимо признать реальные ограничения, которые сама DeepSeek документирует.
Как V4 Flash, так и V4 Pro поддерживают только текст, в отличие от многих закрытых аналогов, которые предлагают поддержку распознавания и генерации аудио, видео и изображений. Для многомодальных приложений V4 в настоящее время не является конкурентоспособным.
В задачах, требующих больших объемов знаний, разрыв с передовыми моделями с закрытым исходным кодом сохраняется. DeepSeek в своем техническом отчете необычно откровенно говорит о сохраняющихся ограничениях V4: V4-Pro-Max отстает от Gemini 3.1 Pro в большинстве тестов, требующих больших объемов знаний. Разрыв существенно сократился, но не исчез полностью.
Для передовых методов агентского программирования V4-Pro-Max делит первое место по показателю SWE Verified (80,6), но отстает по SWE Pro (55,4) и Terminal-Bench 2.0. Для чисто агентского программирования на переднем крае технологий GPT-5.5 и Opus 4.7 по-прежнему выглядят более перспективными.
DeepSeek также признает архитектурную сложность как собственное ограничение — команда описывает архитектуру V4 как «относительно сложную» и заявляет, что в будущих версиях будет предпринята попытка свести ее к наиболее важным элементам.
Геополитический аспект, который нельзя игнорировать
DeepSeek V4 появился не на пустом месте. Его запуск состоялся на следующий день после того, как США обвинили Китай в краже интеллектуальной собственности американских лабораторий искусственного интеллекта в промышленных масштабах с использованием тысяч прокси-аккаунтов. Саму компанию DeepSeek обвинили Anthropic и OpenAI в «дистилляции», по сути, копировании их моделей ИИ.
Не менее важна и история с аппаратным обеспечением. DeepSeek заключила партнерство с китайским технологическим гигантом Huawei, который подтвердил свою поддержку стартапа в области искусственного интеллекта с помощью своей технологии «Supernode», объединяющей большие кластеры чипов Ascend 950 для обеспечения большей вычислительной мощности.
«Это позволяет создавать и развертывать системы искусственного интеллекта, не полагаясь исключительно на Nvidia, поэтому версия V4 в конечном итоге может оказать еще большее влияние, чем R1 — ускорив внедрение внутри страны и способствуя ускорению глобального развития ИИ в целом».
— Вэй Сунь, главный аналитик, Counterpoint ResearchИван Су, старший аналитик по акциям в Morningstar, заявил CNBC, что дебют V4 вряд ли окажет такое же влияние на рынок, как R1, поскольку трейдеры уже учли тот факт, что китайский ИИ конкурентоспособен и дешевле в использовании. Однако последняя позиция DeepSeek ставит другие китайские модели с открытым исходным кодом в качестве прямых конкурентов. «Такой подход не существовал в случае с R1, и уже одно это говорит о том, насколько усилилась конкуренция на внутреннем рынке».
Кому следует использовать DeepSeek V4?
Вы запускаете агенты кодирования, многоэтапные конвейеры рассуждений или проводите сложный анализ документов в больших масштабах. Производительность SWE-bench находится в пределах погрешности измерений, сопоставимой с Claude Opus 4.6, при значительно меньших затратах.
Вам необходима оптимизированная по стоимости и высокопроизводительная обработка данных без существенного снижения качества. При цене 0,28 доллара за миллион выходных токенов Flash является наиболее экономически эффективной моделью нового поколения для производственных задач.
Вам необходимы гарантии суверенитета данных, вы работаете в условиях ограничений экспортного контроля или хотите получить полный контроль над своим стеком обработки данных. Лицензия MIT и доступность Hugging Face делают это действительно возможным.
Ваши рабочие процессы зависят от многомодальных входных данных, вам необходимы самые передовые технологии в задачах, требующих активного использования вычислительных ресурсов, или ваши приложения работают с конфиденциальными данными, размещение которых в китайской компании создает проблемы с соблюдением нормативных требований.
Часто задаваемые вопросы
DeepSeek V4 — это флагманская модель четвертого поколения от DeepSeek, выпущенная 24 апреля 2026 года. Она выпускается в двух вариантах — V4-Pro (1,6 ТБ параметров, 49 байт активных) и V4-Flash (284 байта параметров, 13 байт активных) — оба поддерживают контекстное окно в 1 миллион токенов и распространяются под открытой лицензией MIT.
В тестах производительности, таких как SWE-bench Verified и LiveCodeBench, V4-Pro-Max показывает результаты, сопоставимые или даже превосходящие GPT-5.5. В тестах производительности на виртуальных компьютерах, таких как Terminal-Bench 2.0, GPT-5.5 значительно опережает его (82,7% против 67,9%). Ключевое различие заключается в цене: V4-Pro стоит 3,48 доллара за миллион токенов, тогда как GPT-5.5 — 30 долларов.
Стоимость V4-Flash составляет 0,14 доллара за миллион входных токенов и 0,28 доллара за миллион выходных токенов. Стоимость V4-Pro составляет 1,74 доллара за миллион входных токенов и 3,48 доллара за миллион выходных токенов. Обе модели значительно дешевле, чем аналогичные модели с закрытым исходным кодом.
Да. И V4-Pro, и V4-Flash распространяются под лицензией MIT, а полные веса доступны на Hugging Face. Вы можете скачивать, запускать и использовать модели в коммерческих целях без дополнительных лицензионных сборов.
Весовые коэффициенты модели можно бесплатно скачать и разместить на собственном сервере. Веб-интерфейс по адресу chat.deepseek.com доступен бесплатно. Использование API оплачивается по указанным выше тарифам.
Обе версии будут устарели и полностью выведены из эксплуатации 24 июля 2026 года. Теперь они соответствуют deepseek-v4-flash в режимах Non-Thinking и Thinking соответственно. Разработчикам следует перейти на использование явных идентификаторов моделей V4.
V4-Flash (284 байта общих параметров, 160 ГБ на Hugging Face) — это практичный вариант для локального развертывания в командах с многопроцессорными конфигурациями. V4-Pro объемом 865 ГБ требует значительных ресурсов кластера для обеспечения задержки производственного уровня.
Нет. Версия V4 поддерживает только текстовый ввод. Обработка аудио, изображений и видео в текущей версии недоступна.
DeepSeek V4 не превосходит GPT-5.5 или Claude Opus 4.7 по всем показателям производительности. В этом нет необходимости. Главный аргумент — экономический: почти граничная производительность кодирования и логического вывода, открытые веса под разрешительной лицензией и цена API, которая в семь-двадцать один раз ниже, чем у альтернатив с закрытым исходным кодом.
Для большинства разработчиков и предприятий, использующих LLM-модели в качестве основы для разработки, вопрос никогда не заключался в том, «какая модель показывает лучшие результаты в сравнительном анализе?». Вопрос всегда был в другом: «Какая модель обеспечивает приемлемое качество по цене, которая делает продукт рентабельным?» DeepSeek V4 кардинально меняет этот подход для значительной части реальных сценариев использования.
Нил Шах, вице-президент по исследованиям в Counterpoint Research, назвал V4 «серьезным достижением», отметив более низкие затраты на вывод данных по сравнению с предыдущими моделями. Эта оценка остается верной. DeepSeek сделала то, что большинство наблюдателей еще восемнадцать месяцев назад считали маловероятным: создала и выпустила действительно конкурентоспособную модель с открытым исходным кодом на оборудовании с ограниченными возможностями, установила цену, которая меняет решения о закупках для предприятий, и предоставила веса для запуска любому желающему в мире.
Гонка за искусственным интеллектом не замедляется. Но, как показывает практика, он становится дешевле.
Официальная документация API DeepSeek · Карта модели «Обнимающее лицо» · CNBC · TechCrunch · Reuters · CNN Business · BuildFastWithAI · Morph LLM · Digital Applied · FelloAI · Kingy AI