 OpenAI - ChatGPT, Sora
OpenAI - ChatGPT, Sora Google - Gemini, Nano Banana
Google - Gemini, Nano Banana Antrópico - Claude
Antrópico - Claude xAI - Grok
xAI - Grok Búsqueda profunda
Búsqueda profunda Alibaba - Reina
Alibaba - Reina ByteDance - Lo mejor de ByteDance
ByteDance - Lo mejor de ByteDance Todos los modelos
Todos los modelos Planes empresariales
Planes empresariales Desarrollo de aplicaciones de IA
Desarrollo de aplicaciones de IA API de traducción de IA
API de traducción de IA Servicio de SEO/GEO con IA
Servicio de SEO/GEO con IA Servicio de relaciones públicas geooptimizado
Servicio de relaciones públicas geooptimizado Servicio de extracción de datos web
Servicio de extracción de datos web OpenClaw
OpenClaw Las mejores herramientas de IA
Las mejores herramientas de IA Los mejores robots de IA
Los mejores robots de IA
 Acceso
Acceso

















Este es el lanzamiento más importante de DeepSeek desde que R1 conmocionó los mercados globales en enero de 2025. Aquí tienes todo lo que necesitas saber.
¿Qué es DeepSeek V4?
DeepSeek V4 es la cuarta generación de la familia de modelos insignia de DeepSeek, el laboratorio de IA con sede en Hangzhou que revolucionó los mercados globales en enero de 2025 con el modelo de razonamiento R1 de bajo costo. V4 reemplaza a DeepSeek V3 y V3.2, que dejarán de recibir soporte después del 24 de julio de 2026.
DeepSeek V4 es una versión de doble modelo basada en una arquitectura de mezcla de expertos (MoE). Ambos modelos admiten una ventana de contexto de 1 millón de tokens con una salida máxima de 384 000 tokens, y ambos se publican bajo la licencia MIT, lo que significa que su uso comercial es gratuito y que se puede acceder a todos los pesos en Hugging Face.
DeepSeek-V4-Pro es el producto estrella: 1,6 billones de parámetros totales, 49 mil millones de parámetros activos por token, preentrenado con 33 billones de tokens. DeepSeek-V4-Flash es la opción más eficiente: 284 mil millones de parámetros totales, 13 mil millones de parámetros activos por token, entrenado con 32 billones de tokens.
Esto convierte al DeepSeek-V4-Pro en el nuevo modelo de peso abierto más grande disponible. Es más grande que el Kimi K2.6 (1,1 T) y el GLM-5.1 (754 B), y más del doble del tamaño del DeepSeek V3.2 (685 B).
Ambos modelos se encuentran actualmente en fase de prueba. Reuters informó que DeepSeek está utilizando este período para recopilar comentarios de usuarios reales antes de finalizar el modelo, pero no proporcionó un cronograma para su finalización.
La arquitectura que lo hace posible
DeepSeek V4 no es simplemente una versión ampliada de V3. V4 introduce tres cambios arquitectónicos que la distinguen de V3.2: el mecanismo de atención híbrido CSA+HCA, las hiperconexiones con restricciones de variedad (mHC) y el optimizador Muon. En conjunto, estos cambios explican cómo un modelo de este tamaño puede ejecutarse con un coste de inferencia mucho menor que el de V3.2.
Atención híbrida: CSA + HCA
El principal problema de ingeniería que aborda V4 es el costo de atención en contextos largos. La atención del transformador estándar aumenta cuadráticamente con la longitud de la secuencia; ejecutarla con un millón de tokens en un modelo de este tamaño sería económicamente prohibitivo.
La innovación principal reside en un mecanismo de atención híbrido que intercala la Atención Dispersa Comprimida (CSA) y la Atención Altamente Comprimida (HCA) en las capas transformadoras. CSA comprime la caché de clave-valor de cada m tokens en una sola entrada mediante un compresor a nivel de token aprendido, y luego aplica una selección de clave-valor top-k dependiente de la consulta. HCA lleva la compresión aún más lejos para las capas que toleran una mayor aproximación.
El resultado práctico es sorprendente. En el contexto de 1 millón de tokens, DeepSeek-V4-Pro solo requiere 27% de las operaciones de punto flotante (FLOP) de inferencia de un solo token y 10% de caché KV En comparación con DeepSeek-V3.2, V4-Flash lo lleva aún más lejos, alcanzando el 10% de las operaciones de punto flotante (FLOPs) y el 7% de la caché KV.
La clave reside en que las cifras de eficiencia no se pueden lograr solo con CSA o HCA; el sistema híbrido intercalado es el que mantiene la calidad de contexto largo al tiempo que reduce las operaciones de punto flotante (FLOPs) y la caché KV en un orden de magnitud.
Hiperconexiones con restricciones de variedad (mHC)
mHC aborda un problema fundamental en el entrenamiento de redes neuronales profundas: a medida que los modelos crecen hasta alcanzar cientos o miles de capas, las conexiones residuales estándar generan inestabilidad en la propagación de la señal. mHC restringe las matrices de mezcla al politopo de Birkhoff mediante el algoritmo de Sinkhorn-Knopp, que preserva la magnitud de la señal a través de la red. En otras palabras: mantiene la estabilidad del entrenamiento con billones de parámetros, donde las arquitecturas anteriores divergían.
El optimizador de muones
V4 se entrena utilizando el optimizador Muon, que aplica iteraciones de Newton-Schulz para ortogonalizar aproximadamente la matriz de actualización del gradiente antes de aplicarla como actualización de pesos. En comparación con AdamW, Muon produce una convergencia más rápida y una mayor estabilidad de entrenamiento, algo especialmente importante al entrenar un modelo con 1,6 T parámetros, donde la inestabilidad del optimizador sería catastrófica.
Tres modos de razonamiento
Cada modelo V4 expone tres niveles de esfuerzo de razonamiento: No pensar, Piensa en grande, y Piensa en MaxMax utiliza contextos más largos y penalizaciones de longitud reducidas en RL, y es el modo que debería utilizarse para las tareas de razonamiento más difíciles. La diferencia es significativa: en HLE, V4-Pro pasa de 7,7 (Non-Think) a 37,7 (Max), un salto de casi 5 veces con respecto al mismo modelo simplemente asignando más capacidad de procesamiento para el razonamiento.
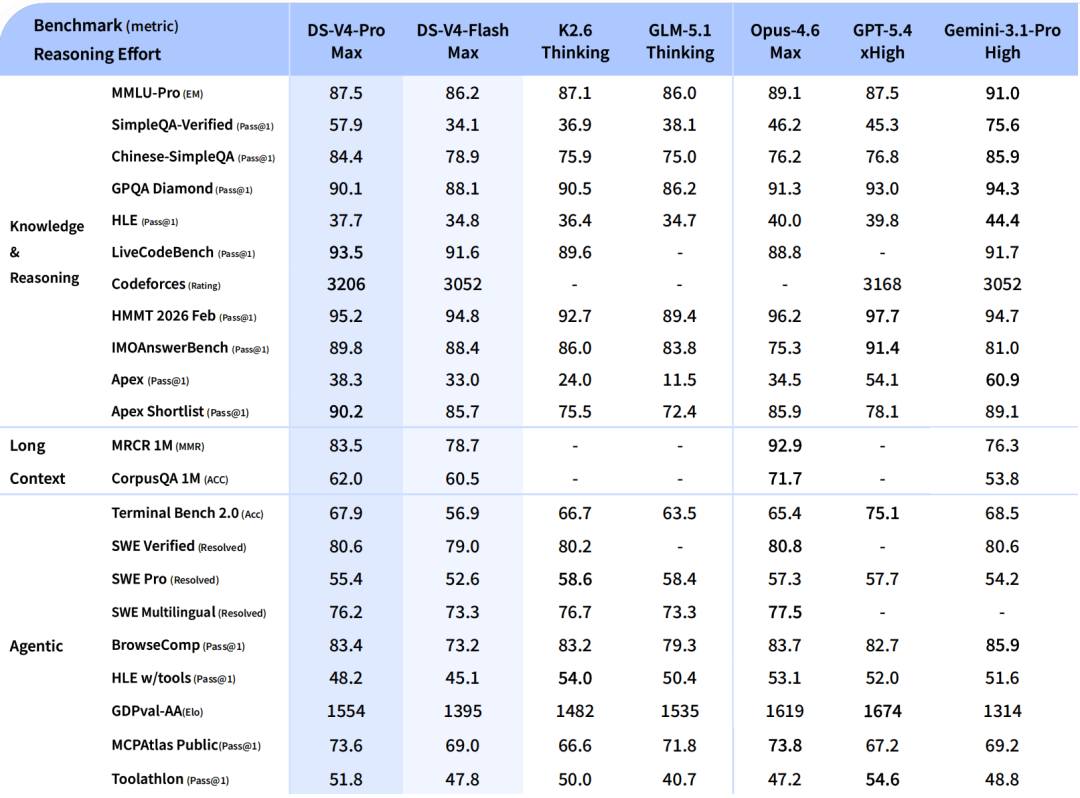
Pruebas de rendimiento de DeepSeek V4: Panorama completo
Puntuaciones V4-Pro-Max 80,6% en SWE-bench verificado y 93,5 en LiveCodeBench — la puntuación de referencia de codificación más alta de cualquier modelo disponible actualmente.
El contexto de la competencia es importante aquí. Claude Opus 4.6 tiene una ligera ventaja en SWE-bench Verified (80,8 % frente a 80,6 %), y una ventaja significativa en HLE (40,0 % frente a 37,7 %) y HMMT 2026 math (96,2 % frente a 95,2 %). V4-Pro cuesta 7 veces menos por millón de tokens de salida.
En matemáticas formales, los resultados son excepcionales. En Putnam-2025, que combina razonamiento informal con verificación formal y mayor capacidad de cálculo, V4 alcanza una puntuación perfecta de 120/120, igualando a Axiom y superando a Aristotle (100/120) y Seed-1.5-Prover (110/120). En pruebas de rendimiento matemático para competiciones, HMMT 2026 de febrero (95,2) e IMOAnswerBench (89,8) sitúan a V4-Pro-Max dentro del rango de GPT-5.4.
En programación competitiva, V4-Pro alcanza una calificación de Codeforces de 3.206, ocupando el puesto 23 entre los competidores humanos.
En qué aspectos V4-Pro-Max se queda atrás de los líderes: V4-Pro-Max se queda atrás de Gemini 3.1 Pro en la mayoría de las pruebas de rendimiento que requieren mucha información, incluidas MMLU-Pro, SimpleQA, GPQA Diamond y HLE. La diferencia se ha reducido considerablemente, pero aún no se ha eliminado por completo.
DeepSeek V4 frente a GPT-5.5, Claude Opus 4.7 y Gemini 3.1 Pro
| Métrico | DeepSeek V4-Pro | GPT-5.5 | Claude Opus 4.7 | Gemini 3.1 Pro |
|---|---|---|---|---|
| SWE-bench verificado | 80,6% | — | 80,8% | — |
| LiveCodeBench | 93.5 | — | — | — |
| Calificación de Codeforces | 3.206 | — | — | 3.052 |
| HMMT 2026 febrero | 95,2% | — | 96,2% | — |
| Terminal-Bench 2.0 | 67,9% | 82,7% | 69,4% | 68,5% |
| Precio de salida de la API / 1M | $3.48 | $30.00 | $75.00 | — |
| Ventana de contexto | 1 millón de tokens | 1 millón de tokens | 1 millón de tokens | 1 millón de tokens |
| Código abierto | ✓ CON | ✗ | ✗ | ✗ |
| Autogestionable | ✓ | ✗ | ✗ | ✗ |
El modelo V4 Pro cuesta 0,145 dólares por millón de tokens de entrada y 3,48 dólares por millón de tokens de salida, lo que supone un precio inferior al de Gemini 3.1 Pro, GPT-5.5, Claude Opus 4.7 y GPT-5.4. A este precio, resulta difícil para los competidores de código cerrado responder al cálculo de la relación rendimiento-precio.
DeepSeek-V4-Pro demuestra un rendimiento superior en comparación con GPT-5.2 y Gemini 3.0 Pro en pruebas de razonamiento estándar, aunque su rendimiento es ligeramente inferior al de GPT-5.4 y Gemini 3.1 Pro, lo que sugiere una trayectoria de desarrollo que se sitúa entre 3 y 6 meses por detrás de los modelos de vanguardia.
Precios: El número que lo cambia todo
El modelo V4-Flash, más pequeño, cuesta 0,14 dólares por millón de tokens de entrada y 0,28 dólares por millón de tokens de salida, lo que supone un precio inferior al de GPT-5.4 Nano, Gemini 3.1 Flash, GPT-5.4 Mini y Claude Haiku 4.5.
En términos de tasas de fallos de caché, V4-Pro cuesta aproximadamente una séptima parte de GPT-5.5 y alrededor de una sexta parte de Claude Opus 4.7 para un rendimiento equivalente.
V4-Pro-Max a $3.48 por millón de tokens de salida ofrece un rendimiento SWE-bench dentro de 0.2 puntos de Claude Opus 4.6 a $75 por millón de tokens de salida. Eso es un Reducción de costos de 21 veces con un rendimiento de referencia de codificación casi idéntico. Para los equipos que ejecutan miles de tareas de codificación automatizada al día, esto cambia lo que es económicamente viable.
El precio de V4-Flash merece especial atención para casos de uso de alto volumen. La diferencia entre Flash y Pro es mínima: Flash ofrece un rendimiento ligeramente inferior en la mayoría de las pruebas comparativas, a cambio de una reducción de 12 veces en el coste de la API. Para la mayoría de las aplicaciones de producción que no requieren un rendimiento de razonamiento máximo, V4-Flash es la opción más económica.
Cómo acceder a DeepSeek V4 hoy
DeepSeek V4 está disponible de tres maneras. Primero, a través de chat.deepseek.com — el chatbot web expone V4 a través de dos interruptores: Modo experto (V4-Pro) y Modo instantáneo (V4-Flash). Segundo, a través de la API DeepSeek usando ID de modelo deepseek-v4-pro y deepseek-v4-flash. En tercer lugar, como pesos abiertos en Hugging Face bajo la licencia MIT, lo que permite el uso comercial gratuito y la implementación local.
Ambos modelos admiten contexto 1M y modos duales (Pensamiento y No Pensamiento). Tenga en cuenta que chat de búsqueda profunda y Razonador de búsqueda profunda estará completamente retirado e inaccesible después 24 de julio de 2026Los desarrolladores que utilicen alias existentes deberán migrar a los identificadores de modelo V4 explícitos antes de esa fecha límite.
Tanto V4-Pro como V4-Flash son compatibles con el formato OpenAI ChatCompletions y el formato de la API de Anthropic. Para la mayoría de los equipos, esto significa que la integración solo requiere actualizar el parámetro del modelo; no es necesario modificar la URL base.
Para el autoalojamiento: V4-Flash es la opción más práctica. Con 284 mil millones de parámetros y 13 mil millones activados por token, V4-Flash puede ejecutarse en una configuración multi-GPU que la mayoría de los equipos medianos pueden permitirse. V4-Pro, con 1,6 billones de parámetros totales, requiere una capacidad de clúster considerable para funcionar con la latencia de producción; la mayoría de los equipos usarán la API de DeepSeek para Pro y considerarán el autoalojamiento solo para Flash.
Dónde se queda corto DeepSeek V4
Un análisis honesto exige reconocer las limitaciones reales que la propia DeepSeek documenta.
Tanto V4 Flash como V4 Pro solo admiten texto, a diferencia de muchos programas de código cerrado que ofrecen compatibilidad para comprender y generar audio, vídeo e imágenes. Para aplicaciones multimodales, V4 no es competitivo actualmente.
En tareas que requieren un alto nivel de conocimiento, la brecha con los modelos de código cerrado de última generación persiste. DeepSeek es inusualmente sincero en su informe técnico sobre las limitaciones que aún presenta V4: V4-Pro-Max se queda atrás de Gemini 3.1 Pro en la mayoría de las pruebas de rendimiento que exigen un alto nivel de conocimiento. La brecha se ha reducido considerablemente, pero no se ha eliminado por completo.
Para flujos de trabajo basados en agentes en la frontera absoluta, V4-Pro-Max iguala a los líderes en SWE Verified (80,6), pero se queda atrás en SWE Pro (55,4) y en Terminal-Bench 2.0. Para codificación puramente basada en agentes en la frontera, GPT-5.5 y Opus 4.7 siguen pareciendo más fuertes.
DeepSeek también reconoce la complejidad arquitectónica como una limitación propia: el equipo describe la arquitectura V4 como "relativamente compleja" y afirma que las versiones futuras tendrán como objetivo simplificarla hasta sus elementos de diseño más esenciales.
La dimensión geopolítica que no puedes ignorar
DeepSeek V4 no surgió de la nada. Su lanzamiento se produce un día después de que Estados Unidos acusara a China de robar propiedad intelectual de laboratorios de IA estadounidenses a escala industrial mediante miles de cuentas proxy. DeepSeek, por su parte, ha sido acusada por Anthropic y OpenAI de "extraer", es decir, copiar, sus modelos de IA.
La historia del hardware es igualmente importante. DeepSeek se asoció con el gigante tecnológico chino Huawei, que confirmó su apoyo a la startup de IA con su tecnología "Supernode", combinando grandes clústeres de sus chips Ascend 950 para proporcionar mayor potencia de cálculo.
"Permite crear e implementar sistemas de IA sin depender exclusivamente de Nvidia, razón por la cual V4 podría tener, en última instancia, un impacto aún mayor que R1, acelerando su adopción a nivel nacional y contribuyendo a un desarrollo global de la IA más rápido en general."
— Wei Sun, analista principal de Counterpoint ResearchIvan Su, analista sénior de renta variable de Morningstar, declaró a CNBC que es improbable que el debut de V4 tenga el mismo impacto en el mercado que el de R1, porque los operadores ya han tenido en cuenta que la IA china es competitiva y más barata de usar. Sin embargo, el último posicionamiento de DeepSeek sitúa a otros modelos chinos de código abierto como competidores directos. "Un enfoque que no existía con R1, y eso por sí solo demuestra cuánto se ha intensificado la competencia nacional."
¿Quién debería usar DeepSeek V4?
Usted está ejecutando agentes de codificación, pipelines de razonamiento de múltiples pasos o análisis de documentos complejos a gran escala. El rendimiento de SWE-bench se encuentra dentro del margen de error de medición de Claude Opus 4.6 a una fracción del costo.
Necesitas una inferencia de alto volumen y con costes optimizados sin sacrificar demasiada calidad. Con un precio de 0,28 dólares por millón de tokens de salida, Flash es el modelo de vanguardia más rentable para cargas de trabajo de producción.
Si tiene requisitos de soberanía de datos, opera bajo restricciones de control de exportaciones o desea tener control total sobre su pila de inferencia, la licencia MIT y la disponibilidad de Hugging Face hacen que esto sea realmente accesible.
Sus flujos de trabajo dependen de entradas multimodales, usted requiere lo último en tareas de uso de computadoras con capacidad de interacción, o sus aplicaciones involucran datos confidenciales donde el alojamiento con una empresa domiciliada en China genera problemas de cumplimiento normativo.
Preguntas frecuentes
DeepSeek V4 es el modelo insignia de cuarta generación de DeepSeek, lanzado el 24 de abril de 2026. Viene en dos variantes: V4-Pro (1,6 T de parámetros, 49 B activos) y V4-Flash (284 B de parámetros, 13 B activos), ambas compatibles con una ventana de contexto de 1 millón de tokens bajo la licencia de código abierto MIT.
En pruebas de rendimiento de codificación como SWE-bench Verified y LiveCodeBench, V4-Pro-Max compite con GPT-5.5 o incluso lo supera. En pruebas de uso de computadoras con agentes, como Terminal-Bench 2.0, GPT-5.5 lidera significativamente (82,7 % frente a 67,9 %). La diferencia clave radica en el precio: V4-Pro cuesta 3,48 dólares por millón de tokens generados, frente a los 30 dólares de GPT-5.5.
V4-Flash cuesta 0,14 dólares por millón de tokens de entrada y 0,28 dólares por millón de tokens de salida. V4-Pro cuesta 1,74 dólares por millón de tokens de entrada y 3,48 dólares por millón de tokens de salida. Ambos son considerablemente más económicos que los modelos de código cerrado comparables.
Sí. Tanto V4-Pro como V4-Flash se distribuyen bajo la licencia MIT, y todos los pesos están disponibles en Hugging Face. Puedes descargar, ejecutar y distribuir comercialmente los modelos sin costes de licencia adicionales.
Los pesos del modelo se pueden descargar y alojar en servidores propios de forma gratuita. La interfaz web en chat.deepseek.com es accesible sin costo alguno. El uso de la API se cobra según las tarifas indicadas anteriormente.
Ambas funciones quedarán obsoletas y se retirarán definitivamente el 24 de julio de 2026. Actualmente, se corresponden con deepseek-v4-flash en los modos Non-Thinking y Thinking, respectivamente. Los desarrolladores deben migrar a los identificadores de modelo V4 explícitos.
La V4-Flash (284 B de parámetros totales, 160 GB en Hugging Face) es la opción práctica para la implementación local en equipos con configuraciones multi-GPU. La V4-Pro, con 865 GB, requiere importantes recursos de clúster para lograr una latencia de nivel de producción.
No. La versión V4 solo admite entrada de texto. El procesamiento de audio, imagen y video no está disponible en la versión actual.
DeepSeek V4 no supera a GPT-5.5 ni a Claude Opus 4.7 en todas las pruebas de rendimiento. Y no lo necesita. El argumento principal es económico: un rendimiento de codificación y razonamiento cercano a la frontera, ponderaciones abiertas bajo una licencia permisiva y precios de API que son entre siete y veintiuno veces más bajos que las alternativas de código cerrado.
Para la mayoría de los desarrolladores y empresas que trabajan con LLM, la pregunta nunca fue "¿qué modelo obtiene la puntuación más alta en una hoja de referencia?". Siempre fue "¿Qué modelo ofrece una calidad aceptable a un coste que haga viable el producto?" DeepSeek V4 cambia ese cálculo de manera decisiva para una parte significativa de los casos de uso del mundo real.
Neil Shah, vicepresidente de investigación de Counterpoint Research, describió V4 como "una demostración de fuerza", destacando sus menores costos de inferencia en comparación con los modelos anteriores. Esta valoración se mantiene. DeepSeek ha logrado algo que la mayoría de los observadores consideraban improbable hace dieciocho meses: ha desarrollado y lanzado un modelo de código abierto realmente competitivo en hardware restringido, con un precio que influye en las decisiones de compra de las empresas, y ha liberado los pesos para que cualquier persona en el mundo pueda utilizarlos.
La carrera por la inteligencia artificial no se está ralentizando. Pero, sin duda, se está abaratando.
Documentación oficial de la API de DeepSeek · Tarjeta del modelo Hugging Face · CNBC · TechCrunch · Reuters · CNN Business · BuildFastWithAI · Morph LLM · Digital Applied · FelloAI · Kingy AI