 OpenAI - ChatGPT, Sora
OpenAI - ChatGPT, Sora Google - Gemini, Nano Banana
Google - Gemini, Nano Banana Antrópico - Claude
Antrópico - Claude xAI - Grok
xAI - Grok Busca profunda
Busca profunda Alibaba - Qwen
Alibaba - Qwen ByteDance - O Melhor da ByteDance
ByteDance - O Melhor da ByteDance Todos os modelos
Todos os modelos Planos Empresariais
Planos Empresariais Desenvolvimento de aplicações de IA
Desenvolvimento de aplicações de IA API de tradução de IA
API de tradução de IA Serviço de SEO/GEO com IA
Serviço de SEO/GEO com IA Serviço de Relações Públicas Otimizado por Geolocalização
Serviço de Relações Públicas Otimizado por Geolocalização Serviço de Web Scraping
Serviço de Web Scraping OpenClaw
OpenClaw Principais ferramentas de IA
Principais ferramentas de IA Os melhores robôs de IA
Os melhores robôs de IA
 Conecte-se
Conecte-se

















Este é o lançamento mais significativo do DeepSeek desde a versão R1, que impactou os mercados globais em janeiro de 2025. Aqui está tudo o que você precisa saber.
O que é o DeepSeek V4?
O DeepSeek V4 é a quarta geração da família de modelos principais da DeepSeek, o laboratório de IA com sede em Hangzhou que revolucionou os mercados globais em janeiro de 2025 com o modelo de raciocínio de baixo custo R1. O V4 substitui o DeepSeek V3 e o V3.2, que serão descontinuados após 24 de julho de 2026.
DeepSeek V4 é uma versão de modelo duplo construída sobre uma arquitetura de Mistura de Especialistas (MoE). Ambos os modelos suportam uma janela de contexto de 1 milhão de tokens com uma saída máxima de 384 mil tokens, e ambos são lançados sob a licença MIT — o que significa uso comercial gratuito e acesso completo aos pesos no Hugging Face.
DeepSeek-V4-Pro é o carro-chefe: 1,6 trilhão de parâmetros totais, 49 bilhões de parâmetros ativos por token, pré-treinado em 33 trilhões de tokens. DeepSeek-V4-Flash é a opção mais eficiente: 284 bilhões de parâmetros totais, 13 bilhões de parâmetros ativos por token, treinado em 32 trilhões de tokens.
Isso faz do DeepSeek-V4-Pro o novo maior modelo open-weight disponível. Ele é maior que o Kimi K2.6 (1.1T) e o GLM-5.1 (754B) e tem mais que o dobro do tamanho do DeepSeek V3.2 (685B).
Ambos os modelos estão atualmente em fase de pré-visualização. A Reuters informou que a DeepSeek está utilizando o período de pré-visualização para coletar feedback do mundo real antes de finalizar o modelo, e não forneceu um cronograma para a finalização.
A arquitetura que torna isso possível
O DeepSeek V4 não é simplesmente uma versão maior do V3. O V4 introduz três mudanças arquitetônicas que o diferenciam do V3.2: o mecanismo de atenção híbrido CSA+HCA, as Hiperconexões com Restrição de Variedade (mHC) e o otimizador Muon. Juntas, essas mudanças explicam como um modelo tão grande pode ser executado com uma fração do custo de inferência do V3.2.
Atenção Híbrida: CSA + HCA
O principal problema de engenharia que o V4 aborda é o custo de atenção em contextos longos. A atenção padrão do Transformer escala quadraticamente com o comprimento da sequência — executá-la com 1 milhão de tokens em um modelo desse tamanho seria economicamente inviável.
A principal inovação reside em um mecanismo de atenção híbrido que intercala Atenção Esparsa Comprimida (CSA) e Atenção Altamente Comprimida (HCA) entre as camadas do Transformer. A CSA comprime o cache de chave-valor de cada m token em uma única entrada usando um compressor aprendido em nível de token e, em seguida, aplica a seleção dos k melhores valores de chave-valor dependente da consulta. A HCA leva a compressão ainda mais longe para camadas que toleram maior aproximação.
O resultado prático é impressionante. No contexto de 1 milhão de tokens, o DeepSeek-V4-Pro requer apenas 27% das operações de ponto flutuante de inferência de token único e 10% do cache KV Em comparação com o DeepSeek-V3.2, o V4-Flash eleva esse percentual para 10% dos FLOPs e 7% do cache KV.
A principal conclusão é que os números de eficiência não são alcançáveis apenas com CSA ou HCA — o híbrido intercalado é o que mantém a qualidade de contexto longo, reduzindo os FLOPs e o cache KV em uma ordem de magnitude.
Hiperconexões com Restrição de Variedade (mHC)
O mHC aborda um problema fundamental no treinamento de redes neurais profundas: à medida que os modelos crescem para centenas ou milhares de camadas, as conexões residuais padrão criam instabilidade na propagação do sinal. O mHC restringe as matrizes de mistura ao Polítopo de Birkhoff usando o algoritmo de Sinkhorn-Knopp, que preserva a magnitude do sinal em toda a rede. Em termos simples: ele mantém o treinamento com trilhões de parâmetros estável onde as arquiteturas anteriores divergiam.
O Otimizador de Múons
O modelo V4 é treinado usando o otimizador Muon, que aplica iterações de Newton-Schulz para ortogonalizar aproximadamente a matriz de atualização do gradiente antes de aplicá-la como uma atualização de peso. Comparado ao AdamW, o Muon produz convergência mais rápida e maior estabilidade de treinamento — particularmente importante ao treinar um modelo com 1,6 trilhão de parâmetros, onde a instabilidade do otimizador seria catastrófica.
Três modos de raciocínio
Cada modelo V4 expõe três níveis de esforço de raciocínio: Não pensar, Pense Alto, e Pense MaxO modo Max utiliza contextos mais longos e penalidades de comprimento reduzidas em RL, sendo o modo recomendado para as tarefas de raciocínio mais complexas. A diferença é significativa: no HLE, o V4-Pro passa de 7,7 (Non-Think) para 37,7 (Max) — um aumento de quase 5 vezes em relação ao mesmo modelo, simplesmente alocando mais poder computacional para o raciocínio.
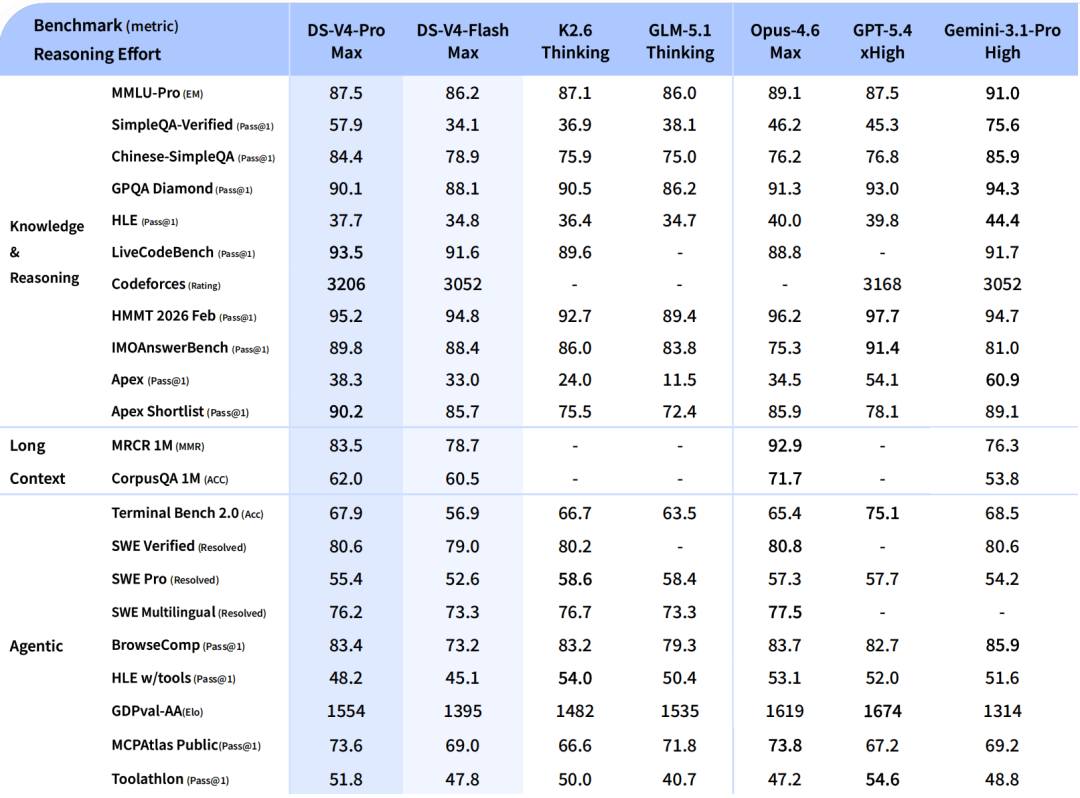
Testes de desempenho do DeepSeek V4: O panorama completo
Pontuações V4-Pro-Max 80,6% verificado no SWE-bench e 93,5 no LiveCodeBench — a pontuação de referência de codificação mais alta de qualquer modelo atualmente disponível.
O contexto da competição é importante aqui. O Claude Opus 4.6 tem uma pequena vantagem no SWE-bench Verified (80,8% vs 80,6%) e uma vantagem significativa no HLE (40,0% vs 37,7%) e no HMMT 2026 math (96,2% vs 95,2%). O V4-Pro custa 7 vezes menos por milhão de tokens de saída.
Em matemática formal, os resultados são excepcionais. No Putnam-2025, que combina raciocínio informal com verificação formal e computação mais pesada, o V4 alcança uma pontuação perfeita de 120/120, empatando com o Axiom e superando o Aristotle (100/120) e o Seed-1.5-Prover (110/120). Em benchmarks de matemática competitiva, o HMMT 2026 de fevereiro, com 95,2 pontos, e o IMOAnswerBench, com 89,8, colocam o V4-Pro-Max no mesmo nível do GPT-5.4.
Em programação competitiva, o V4-Pro alcança uma classificação no Codeforces de 3.206, ocupando a 23ª posição entre os competidores humanos.
Onde o V4-Pro-Max fica atrás dos líderes: O V4-Pro-Max fica atrás do Gemini 3.1 Pro na maioria dos benchmarks que exigem grande conhecimento, incluindo MMLU-Pro, SimpleQA, GPQA Diamond e HLE. A diferença diminuiu consideravelmente, mas não desapareceu completamente.
DeepSeek V4 vs GPT-5.5, Claude Opus 4.7 e Gemini 3.1 Pro
| Métrica | DeepSeek V4-Pro | GPT-5.5 | Claude Opus 4.7 | Gemini 3.1 Pro |
|---|---|---|---|---|
| Verificado pelo SWE-bench | 80,6% | — | 80,8% | — |
| LiveCodeBench | 93,5 | — | — | — |
| Classificação Codeforces | 3.206 | — | — | 3.052 |
| HMMT fevereiro de 2026 | 95,2% | — | 96,2% | — |
| Bancada de terminais 2.0 | 67,9% | 82,7% | 69,4% | 68,5% |
| Preço de saída da API / 1M | $ 3,48 | $ 30,00 | $ 75,00 | — |
| Janela de contexto | 1 milhão de tokens | 1 milhão de tokens | 1 milhão de tokens | 1 milhão de tokens |
| Código aberto | ✓ COM | ✗ | ✗ | ✗ |
| Autohospedagem | ✓ | ✗ | ✗ | ✗ |
O modelo V4 Pro custa US$ 0,145 por milhão de tokens de entrada e US$ 3,48 por milhão de tokens de saída, ficando abaixo do Gemini 3.1 Pro, GPT-5.5, Claude Opus 4.7 e GPT-5.4. O cálculo da relação custo-benefício nesse patamar de preço é difícil para os concorrentes de código fechado.
O DeepSeek-V4-Pro demonstra desempenho superior em relação ao GPT-5.2 e ao Gemini 3.0 Pro em benchmarks de raciocínio padrão, embora seu desempenho fique ligeiramente abaixo do GPT-5.4 e do Gemini 3.1 Pro, sugerindo uma trajetória de desenvolvimento que está cerca de 3 a 6 meses atrás dos modelos de ponta.
Preços: O Número que Muda Tudo
O modelo V4-Flash, de tamanho menor, custa US$ 0,14 por milhão de tokens de entrada e US$ 0,28 por milhão de tokens de saída, ficando abaixo dos preços do GPT-5.4 Nano, Gemini 3.1 Flash, GPT-5.4 Mini e Claude Haiku 4.5.
Considerando as taxas de falha de cache, o V4-Pro custa aproximadamente um sétimo do GPT-5.5 e cerca de um sexto do Claude Opus 4.7 para uma taxa de transferência equivalente.
O V4-Pro-Max, com um custo de US$ 3,48 por milhão de tokens de saída, apresenta um desempenho no benchmark SWE com uma diferença de apenas 0,2 pontos em relação ao Claude Opus 4.6, que custa US$ 75 por milhão de tokens de saída. Isso é um grande diferencial. Redução de custos de 21 vezes com desempenho de benchmark de codificação quase idêntico. Para equipes que executam milhares de tarefas de codificação de agentes por dia, isso altera o que é economicamente viável.
O preço do V4-Flash merece atenção especial para casos de uso de alto volume. A diferença entre o Flash e o Pro é pequena — o Flash perde cerca de 1 a 2 pontos na maioria dos benchmarks em troca de uma redução de 12 vezes no custo da API. Para a maioria das aplicações de produção que não exigem desempenho máximo de raciocínio, o V4-Flash é a opção econômica padrão correta.
Como acessar o DeepSeek V4 hoje
O DeepSeek V4 está disponível de três maneiras. Primeiro, via chat.deepseek.com — o chatbot da web expõe o V4 por meio de duas opções: Modo Especialista (V4-Pro) e Modo Instantâneo (V4-Flash). Em segundo lugar, por meio da API DeepSeek usando IDs de modelo. deepseek-v4-pro e deepseek-v4-flashTerceiro, como pesos abertos no Hugging Face sob a licença MIT, permitindo uso comercial gratuito e implantação local.
Ambos os modelos suportam 1 milhão de contextos e modos duplos (Pensamento e Não-Pensamento). Observe que bate-papo profundo e deepseek-reasoner ficará totalmente desativado e inacessível após 24 de julho de 2026Os desenvolvedores que utilizam aliases existentes devem migrar para os IDs de modelo V4 explícitos antes desse prazo.
Tanto o V4-Pro quanto o V4-Flash são compatíveis com o formato OpenAI ChatCompletions e com o formato da API Anthropic. Para a maioria das equipes, isso significa que a integração requer apenas a atualização do parâmetro do modelo — nenhuma alteração na URL base é necessária.
Para hospedagem própria: os pesos do V4-Flash representam o alvo prático para hospedagem própria. Com 284 bilhões de parâmetros e 13 bilhões ativados por token, o V4-Flash pode ser executado em uma configuração com múltiplas GPUs, acessível para a maioria das equipes de médio porte. O V4-Pro, com 1,6 trilhão de parâmetros totais, exige uma capacidade de cluster significativa para atender à latência de produção — a maioria das equipes utilizará a API DeepSeek para o V4-Pro e considerará a hospedagem própria apenas para o V4-Flash.
Onde o DeepSeek V4 deixa a desejar
Uma análise honesta exige o reconhecimento das limitações reais que o próprio DeepSeek documenta.
Tanto o Flash V4 quanto o V4 Pro suportam apenas texto, diferentemente de muitos concorrentes de código fechado que oferecem suporte para compreensão e geração de áudio, vídeo e imagens. Para aplicações multimodais, o V4 não é competitivo atualmente.
Em tarefas que exigem grande conhecimento, a diferença para os modelos proprietários de ponta ainda persiste. A DeepSeek é excepcionalmente franca no relatório técnico sobre as limitações remanescentes do V4: o V4-Pro-Max fica atrás do Gemini 3.1 Pro na maioria dos benchmarks que exigem grande conhecimento. A diferença diminuiu consideravelmente, mas não desapareceu completamente.
Para fluxos de trabalho agentivos de última geração, o V4-Pro-Max empata com os líderes no SWE Verified (80,6), mas fica atrás no SWE Pro (55,4) e no Terminal-Bench 2.0. Para codificação agentiva pura de última geração, o GPT-5.5 e o Opus 4.7 ainda se destacam.
A DeepSeek também reconhece a complexidade arquitetônica como uma limitação autoidentificada — a equipe descreve a arquitetura V4 como "relativamente complexa" e afirma que as versões futuras buscarão simplificá-la ao máximo, reduzindo-a aos seus elementos essenciais.
A dimensão geopolítica que você não pode ignorar
O DeepSeek V4 não surgiu do nada. O lançamento ocorre um dia depois de os EUA acusarem a China de roubar propriedade intelectual de laboratórios de IA americanos em escala industrial, usando milhares de contas proxy. O próprio DeepSeek foi acusado pela Anthropic e pela OpenAI de "destilar", essencialmente copiar, seus modelos de IA.
A questão do hardware é igualmente importante. A DeepSeek fez uma parceria com a gigante chinesa de tecnologia Huawei, que confirmou o apoio à startup de IA com sua tecnologia "Supernode", combinando grandes clusters de seus chips Ascend 950 para fornecer mais poder de computação.
"Isso permite que sistemas de IA sejam construídos e implementados sem depender exclusivamente da Nvidia, e é por isso que a V4 pode, em última análise, ter um impacto ainda maior do que a R1 — acelerando a adoção no mercado interno e contribuindo para um desenvolvimento global mais rápido da IA."
— Wei Sun, Analista Principal, Counterpoint ResearchIvan Su, analista sênior de ações da Morningstar, disse à CNBC que a estreia da V4 provavelmente não terá o mesmo impacto no mercado que a R1, porque os investidores já precificaram a realidade de que a IA chinesa é competitiva e mais barata de usar. No entanto, o posicionamento mais recente da DeepSeek coloca outros modelos chineses de código aberto como concorrentes diretos. "Uma estrutura que não existia com a R1, e isso por si só demonstra o quanto a competição interna se intensificou."
Quem deve usar o DeepSeek V4?
Você executa agentes de codificação, fluxos de raciocínio de várias etapas ou análises complexas de documentos em grande escala. O desempenho do SWE-bench está dentro da margem de erro de medição do Claude Opus 4.6, a uma fração do custo.
Você precisa de inferência de alto volume e custo otimizado sem sacrificar muito a qualidade. Com um custo de US$ 0,28 por milhão de tokens de saída, o Flash é o modelo de ponta mais econômico para cargas de trabalho de produção.
Você tem requisitos de soberania de dados, opera sob restrições de controle de exportação ou deseja controle total sobre sua pilha de inferência? A licença MIT e a disponibilidade na Hugging Face tornam isso verdadeiramente acessível.
Seus fluxos de trabalho dependem de entradas multimodais, você precisa do que há de mais moderno em tarefas de uso de computadores com agentes, ou seus aplicativos envolvem dados sensíveis em que a hospedagem com uma empresa domiciliada na China gera preocupações de conformidade.
Perguntas frequentes
O DeepSeek V4 é o modelo principal de quarta geração da DeepSeek, lançado em 24 de abril de 2026. Ele vem em duas variantes — V4-Pro (1,6T de parâmetros, 49B ativos) e V4-Flash (284B de parâmetros, 13B ativos) — ambas suportando uma janela de contexto de 1 milhão de tokens sob a licença de código aberto MIT.
Em benchmarks de programação como SWE-bench Verified e LiveCodeBench, o V4-Pro-Max é competitivo ou superior ao GPT-5.5. Em benchmarks de uso computacional com agentes, como o Terminal-Bench 2.0, o GPT-5.5 apresenta uma vantagem significativa (82,7% contra 67,9%). A principal diferença reside no preço: o V4-Pro custa US$ 3,48 por milhão de tokens de saída, enquanto o GPT-5.5 custa US$ 30.
O V4-Flash custa US$ 0,14 por milhão de tokens de entrada e US$ 0,28 por milhão de tokens de saída. O V4-Pro custa US$ 1,74 por milhão de tokens de entrada e US$ 3,48 por milhão de tokens de saída. Ambos são consideravelmente mais baratos do que modelos proprietários comparáveis.
Sim. Tanto o V4-Pro quanto o V4-Flash são distribuídos sob a licença MIT, com todos os pesos disponíveis no Hugging Face. Você pode baixar, executar e implantar comercialmente os modelos sem custos adicionais de licenciamento.
Os pesos do modelo podem ser baixados e hospedados gratuitamente. A interface web em chat.deepseek.com é acessível sem custos. O uso da API é cobrado de acordo com as taxas acima.
Ambos serão descontinuados e totalmente desativados em 24 de julho de 2026. Eles agora correspondem ao deepseek-v4-flash nos modos Não-Pensador e Pensador, respectivamente. Os desenvolvedores devem migrar para os IDs de modelo V4 explícitos.
O V4-Flash (com parâmetros totais de 284 bytes e 160 GB na Hugging Face) é a opção prática para implantação local em equipes com configurações multi-GPU. O V4-Pro, com 865 GB, exige recursos de cluster significativos para atingir a latência necessária para produção.
Não. A versão 4 suporta apenas entrada de texto. O processamento de áudio, imagem e vídeo não está disponível nesta versão.
O DeepSeek V4 não supera o GPT-5.5 ou o Claude Opus 4.7 em todos os benchmarks. E não precisa. O principal argumento é econômico: desempenho de codificação e raciocínio próximo ao limite, pesos abertos sob uma licença permissiva e preços de API que reduzem as alternativas de código fechado em um fator de sete a vinte e um.
Para a maioria dos desenvolvedores e empresas que criam soluções com LLMs, a questão nunca foi "qual modelo obtém a maior pontuação em uma planilha de benchmark?". Sempre foi "Qual modelo oferece qualidade aceitável a um custo que torna o produto viável?" O DeepSeek V4 altera esse cálculo de forma decisiva para uma parcela significativa de casos de uso no mundo real.
Neil Shah, vice-presidente de pesquisa da Counterpoint Research, descreveu a V4 como "uma demonstração de força considerável", destacando seus custos de inferência mais baixos em comparação com os modelos anteriores. Essa avaliação se confirma. A DeepSeek fez algo que a maioria dos observadores considerava improvável há dezoito meses: construiu e lançou um modelo de código aberto genuinamente competitivo em hardware restrito, com um preço que altera as decisões de compra corporativas, e disponibilizou os pesos para que qualquer pessoa no mundo possa executá-los.
A corrida pela inteligência artificial não está diminuindo o ritmo. Mas, comprovadamente, está ficando mais barata.
Documentação oficial da API do DeepSeek · Cartão de modelo do Hugging Face · CNBC · TechCrunch · Reuters · CNN Business · BuildFastWithAI · Morph LLM · Digital Applied · FelloAI · Kingy AI