 OpenAI - ChatGPT, Sora
OpenAI - ChatGPT, Sora Google - Gemini, Nano Banane
Google - Gemini, Nano Banane Anthropic - Claude
Anthropic - Claude xAI - Grok
xAI - Grok Deepseek
Deepseek Alibaba - Qwen
Alibaba - Qwen ByteDance – Das Beste von ByteDance
ByteDance – Das Beste von ByteDance Alle Modelle
Alle Modelle Unternehmenspläne
Unternehmenspläne KI-Anwendungsentwicklung
KI-Anwendungsentwicklung KI-Übersetzer-API
KI-Übersetzer-API KI-SEO/GEO-Dienst
KI-SEO/GEO-Dienst Geooptimierter PR-Service
Geooptimierter PR-Service Web-Scraping-Dienst
Web-Scraping-Dienst OpenClaw
OpenClaw Die besten KI-Tools
Die besten KI-Tools Top-KI-Roboter
Top-KI-Roboter
 Einloggen
Einloggen

















Dies ist DeepSeeks bedeutendste Veröffentlichung seit R1 im Januar 2025 die globalen Märkte aufgerüttelt hat. Hier finden Sie alles Wissenswerte.
Was ist DeepSeek V4?
DeepSeek V4 ist die vierte Generation der Flaggschiff-Modellfamilie von DeepSeek, dem KI-Labor aus Hangzhou, das im Januar 2025 mit dem kostengünstigen R1-Logikmodell die globalen Märkte revolutionierte. V4 ersetzt DeepSeek V3 und V3.2, deren Support nach dem 24. Juli 2026 eingestellt wird.
DeepSeek V4 ist eine Dual-Modell-Version, die auf einer Mixture-of-Experts-Architektur (MoE) basiert. Beide Modelle unterstützen ein Kontextfenster von 1 Million Token mit einer maximalen Ausgabemenge von 384.000 Token und werden unter der MIT-Lizenz veröffentlicht – dies bedeutet freie kommerzielle Nutzung und vollständigen Zugriff auf die Gewichtungen auf Hugging Face.
DeepSeek-V4-Pro ist das Flaggschiff: 1,6 Billionen Parameter insgesamt, 49 Milliarden aktive Token, vortrainiert mit 33 Billionen Token. DeepSeek-V4-Flash ist die effiziente Variante: 284 Milliarden Parameter insgesamt, 13 Milliarden aktive Token, trainiert mit 32 Billionen Token.
Damit ist der DeepSeek-V4-Pro das neue größte verfügbare Modell mit offener Bauform. Er ist größer als der Kimi K2.6 (1,1T) und der GLM-5.1 (754B) und mehr als doppelt so groß wie der DeepSeek V3.2 (685B).
Beide Modelle befinden sich derzeit in der Vorschauphase. Reuters berichtete, dass DeepSeek die Vorschauphase nutzt, um Feedback aus der Praxis zu sammeln, bevor das Modell finalisiert wird, und nannte keinen Zeitplan für die Fertigstellung.
Die Architektur, die dies ermöglicht
DeepSeek V4 ist nicht einfach eine größere Version von V3. V4 führt drei architektonische Änderungen ein, die es von V3.2 unterscheiden: den hybriden Aufmerksamkeitsmechanismus CSA+HCA, Manifold-Constrained Hyper-Connections (mHC) und den Muon-Optimierer. Zusammen erklären diese, wie ein so großes Modell mit einem Bruchteil der Inferenzkosten von V3.2 ausgeführt werden kann.
Hybrid-Aufmerksamkeit: CSA + HCA
Das zentrale technische Problem, das V4 angeht, sind die Aufmerksamkeitskosten bei langen Kontexten. Die Standard-Transformator-Aufmerksamkeit skaliert quadratisch mit der Sequenzlänge – die Anwendung auf 1 Million Token mit einem Modell dieser Größe wäre wirtschaftlich nicht rentabel.
Die zentrale Innovation ist ein hybrider Aufmerksamkeitsmechanismus, der Compressed Sparse Attention (CSA) und Heavily Compressed Attention (HCA) über Transformer-Schichten hinweg verschachtelt. CSA komprimiert den Key-Value-Cache von jeweils m Tokens in einen einzigen Eintrag mithilfe eines gelernten Token-Level-Kompressors und wendet anschließend eine abfrageabhängige Top-k-KV-Auswahl an. HCA optimiert die Komprimierung für Schichten, die eine höhere Approximation tolerieren.
Das praktische Ergebnis ist beeindruckend. Im Kontext von 1 Million Token benötigt DeepSeek-V4-Pro lediglich 27 % der Einzel-Token-Inferenz-FLOPs Und 10 % des KV-Caches im Vergleich zu DeepSeek-V3.2. V4-Flash steigert dies weiter auf 10 % FLOPs und 7 % KV-Cache.
Die entscheidende Erkenntnis ist, dass diese Effizienzwerte weder mit CSA noch mit HCA allein erreicht werden können – nur die verschachtelte Hybridlösung gewährleistet die Langzeitkontextqualität bei gleichzeitiger Reduzierung der FLOPs und des KV-Caches um eine Größenordnung.
Manifold-Constrained Hyper-Connections (mHC)
mHC löst ein grundlegendes Problem beim Training tiefer neuronaler Netze: Wenn Modelle Hunderte oder Tausende von Schichten erreichen, führen herkömmliche Residualverbindungen zu Instabilitäten in der Signalweiterleitung. mHC beschränkt die Mischungsmatrizen mithilfe des Sinkhorn-Knopp-Algorithmus auf das Birkhoff-Polytop, wodurch die Signalstärke im gesamten Netzwerk erhalten bleibt. Vereinfacht ausgedrückt: Es gewährleistet die Stabilität des Trainings von Modellen mit Billionen von Parametern, wo frühere Architekturen divergieren würden.
Der Myon-Optimierer
V4 wird mit dem Muon-Optimierer trainiert, der Newton-Schulz-Iterationen anwendet, um die Gradientenaktualisierungsmatrix näherungsweise zu orthogonalisieren, bevor sie als Gewichtsaktualisierung verwendet wird. Im Vergleich zu AdamW erzielt Muon eine schnellere Konvergenz und eine höhere Trainingsstabilität – besonders wichtig beim Training eines Modells mit 1,6T Parametern, bei dem eine Instabilität des Optimierers katastrophale Folgen hätte.
Drei Denkmodi
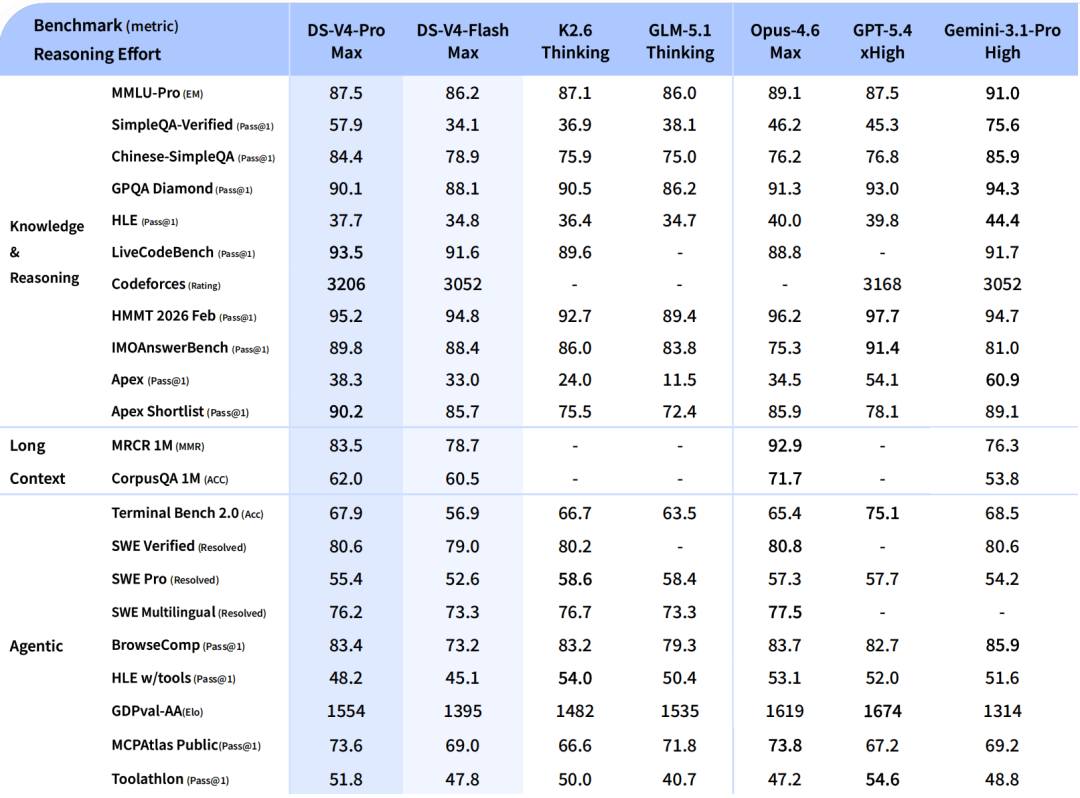
Jedes V4-Modell weist drei Ebenen des Denkaufwands auf: Nicht-Denken, Denk hoch!, Und Denk an MaxDer Modus „Max“ nutzt längere Kontexte und reduziert Längenstrafen im Reinforcement Learning und sollte für die schwierigsten Schlussfolgerungsaufgaben verwendet werden. Der Unterschied ist signifikant: Auf HLE steigt V4-Pro von 7,7 (Non-Think) auf 37,7 (Max) – ein fast fünffacher Sprung im Vergleich zum gleichen Modell, allein durch die Zuweisung von mehr Rechenkapazität für Schlussfolgerungen.
DeepSeek V4 Benchmarks: Das Gesamtbild
V4-Pro-Max-Ergebnisse 80,6 % auf SWE-bench verifiziert Und 93,5 auf LiveCodeBench — die höchste Punktzahl im Codierungs-Benchmark aller derzeit verfügbaren Modelle.
Der Wettbewerbskontext ist hier entscheidend. Claude Opus 4.6 liegt bei SWE-bench Verified leicht vorn (80,8 % vs. 80,6 %) und bei HLE (40,0 % vs. 37,7 %) sowie HMMT 2026 (96,2 % vs. 95,2 %) deutlich vorn. V4-Pro ist pro Million ausgegebener Token siebenmal günstiger.
In der formalen Mathematik sind die Ergebnisse außergewöhnlich. Auf Putnam-2025, das informelles Schließen mit formaler Verifikation und hohem Rechenaufwand kombiniert, erreicht V4 die perfekte Beweisgenauigkeit von 120/120 Punkten und liegt damit gleichauf mit Axiom und vor Aristotle (100/120) und Seed-1.5-Prover (110/120). Bei den Wettbewerbs-Benchmarks HMMT 2026 Februar mit 95,2 Punkten und IMOAnswerBench mit 89,8 Punkten liegt V4-Pro-Max im Bereich von GPT-5.4.
Im Bereich des wettbewerbsorientierten Programmierens erreicht V4-Pro eine Codeforces-Bewertung von 3.206, Platz 23 unter den menschlichen Konkurrenten.
Wo V4-Pro-Max hinter den Marktführern zurückbleibt: V4-Pro-Max liegt bei den meisten wissensintensiven Benchmarks, darunter MMLU-Pro, SimpleQA, GPQA Diamond und HLE, hinter Gemini 3.1 Pro zurück. Der Abstand hat sich zwar deutlich verringert, ist aber noch nicht aufgeholt.
DeepSeek V4 vs. GPT-5.5, Claude Opus 4.7 und Gemini 3.1 Pro
| Metrisch | DeepSeek V4-Pro | GPT-5.5 | Claude Opus 4.7 | Gemini 3.1 Pro |
|---|---|---|---|---|
| SWE-bench-verifiziert | 80,6 % | — | 80,8 % | — |
| LiveCodeBench | 93,5 | — | — | — |
| Codeforces-Bewertung | 3.206 | — | — | 3.052 |
| HMMT 2026 Feb | 95,2 % | — | 96,2 % | — |
| Terminalbank 2.0 | 67,9 % | 82,7 % | 69,4 % | 68,5 % |
| API-Ausgabepreis / 1 Mio. | 3,48 $ | 30,00 € | 75,00 € | — |
| Kontextfenster | 1 Million Token | 1 Million Token | 1 Million Token | 1 Million Token |
| Open Source | ✓ MIT | ✗ | ✗ | ✗ |
| Selbsthostbar | ✓ | ✗ | ✗ | ✗ |
Das V4 Pro-Modell kostet 0,145 US-Dollar pro Million Input-Token und 3,48 US-Dollar pro Million Output-Token und ist damit günstiger als Gemini 3.1 Pro, GPT-5.5, Claude Opus 4.7 und GPT-5.4. Die Berechnung des Preis-Leistungs-Verhältnisses ist bei diesem Preisniveau für proprietäre Konkurrenten schwer zu beantworten.
DeepSeek-V4-Pro zeigt im Vergleich zu GPT-5.2 und Gemini 3.0 Pro bei Standard-Benchmarks für logisches Denken eine überlegene Leistung, bleibt aber geringfügig hinter GPT-5.4 und Gemini 3.1 Pro zurück, was auf eine Entwicklungstendenz hindeutet, die etwa 3 bis 6 Monate hinter den modernsten Spitzenmodellen zurückliegt.
Preisgestaltung: Die Zahl, die alles verändert
Das kleinere V4-Flash-Modell kostet 0,14 US-Dollar pro Million Input-Token und 0,28 US-Dollar pro Million Output-Token und ist damit günstiger als GPT-5.4 Nano, Gemini 3.1 Flash, GPT-5.4 Mini und Claude Haiku 4.5.
Bei Cache-Fehlerraten kostet V4-Pro etwa ein Siebtel von GPT-5.5 und etwa ein Sechstel von Claude Opus 4.7 bei gleichem Durchsatz.
V4-Pro-Max erzielt bei 3,48 US-Dollar pro Million Output-Token eine SWE-Bench-Performance, die innerhalb von 0,2 Punkten der von Claude Opus 4.6 bei 75 US-Dollar pro Million Output-Token liegt. Das ist ein 21-fache Kostenreduzierung bei nahezu identischer Leistung in den Codierungs-Benchmarks. Für Teams, die täglich Tausende von agentenbasierten Codierungsaufgaben ausführen, verändert dies die wirtschaftliche Machbarkeit.
Die Preisgestaltung von V4-Flash verdient besondere Beachtung, insbesondere bei Anwendungen mit hohem Datenvolumen. Der Unterschied zwischen Flash und Pro ist gering – Flash schneidet in den meisten Benchmarks nur 1–2 Punkte schlechter ab, bietet dafür aber eine 12-fache Reduzierung der API-Kosten. Für die meisten Produktionsanwendungen, die keine Spitzenleistung erfordern, ist V4-Flash die wirtschaftlich sinnvolle Standardlösung.
So erhalten Sie heute Zugriff auf DeepSeek V4
DeepSeek V4 ist auf drei Arten verfügbar. Erstens, über chat.deepseek.com — Der Web-Chatbot stellt V4 über zwei Schalter bereit: Expertenmodus (V4-Pro) und Sofortmodus (V4-Flash). Zweitens über die DeepSeek-API mithilfe von Modell-IDs. deepseek-v4-pro Und deepseek-v4-flashDrittens, als offene Gewichte auf Hugging Face unter der MIT-Lizenz, was die freie kommerzielle Nutzung und lokale Bereitstellung ermöglicht.
Beide Modelle unterstützen 1M-Kontext und duale Modi (Denken und Nicht-Denken). Beachten Sie, dass deepseek-chat Und deepseek-reasoner wird vollständig außer Betrieb genommen und ist dann nicht mehr zugänglich 24. Juli 2026Entwickler, die bestehende Aliase verwenden, sollten vor diesem Stichtag auf die expliziten V4-Modell-IDs umsteigen.
Sowohl V4-Pro als auch V4-Flash unterstützen das OpenAI ChatCompletions-Format und das Anthropic API-Format. Für die meisten Teams bedeutet dies, dass die Integration lediglich eine Aktualisierung des Modellparameters erfordert – eine Änderung der Basis-URL ist nicht notwendig.
Für Self-Hosting: Die V4-Flash-Gewichte stellen das optimale Ziel für Self-Hosting dar. Mit 284 B Parametern und 13 B aktivierten Daten pro Token kann V4-Flash auf einem Multi-GPU-System ausgeführt werden, das sich die meisten mittelständischen Teams leisten können. V4-Pro mit insgesamt 1,6 T Parametern erfordert hingegen eine erhebliche Clusterkapazität, um die erforderliche Latenz im Produktionsbetrieb zu gewährleisten. Die meisten Teams werden daher die DeepSeek-API für Pro nutzen und Self-Hosting nur für Flash in Betracht ziehen.
Wo DeepSeek V4 seine Grenzen hat
Eine ehrliche Analyse erfordert die Anerkennung der tatsächlichen Einschränkungen, die DeepSeek selbst dokumentiert.
Sowohl V4 Flash als auch V4 Pro unterstützen ausschließlich Text, im Gegensatz zu vielen proprietären Konkurrenzprodukten, die auch die Wiedergabe von Audio, Video und Bildern ermöglichen. Für multimodale Anwendungen ist V4 derzeit nicht konkurrenzfähig.
Bei wissensintensiven Aufgaben bleibt der Abstand zu führenden proprietären Modellen bestehen. DeepSeek geht im technischen Bericht ungewöhnlich offen mit den verbleibenden Einschränkungen des V4 um: Der V4-Pro-Max bleibt in den meisten wissensintensiven Benchmarks hinter dem Gemini 3.1 Pro zurück. Der Abstand hat sich zwar deutlich verringert, ist aber noch nicht geschlossen.
Für agentenbasierte Workflows auf höchstem Niveau erreicht V4-Pro-Max bei SWE Verified (80,6) das gleiche Ergebnis wie die führenden Systeme, hinkt aber bei SWE Pro (55,4) und Terminal-Bench 2.0 hinterher. Für reine agentenbasierte Codierung auf höchstem Niveau sind GPT-5.5 und Opus 4.7 weiterhin überlegen.
DeepSeek räumt auch die architektonische Komplexität als selbstbezeichnete Einschränkung ein – das Team beschreibt die V4-Architektur als „relativ komplex“ und gibt an, dass zukünftige Versionen darauf abzielen werden, sie auf ihre wesentlichsten Designmerkmale zu reduzieren.
Die geopolitische Dimension, die Sie nicht ignorieren können
DeepSeek V4 erschien nicht ohne Grund. Die Veröffentlichung erfolgte einen Tag, nachdem die USA China beschuldigt hatten, mithilfe Tausender Proxy-Konten im industriellen Maßstab geistiges Eigentum amerikanischer KI-Labore gestohlen zu haben. DeepSeek selbst wurde von Anthropic und OpenAI beschuldigt, deren KI-Modelle „abgewandelt“, also im Wesentlichen kopiert zu haben.
Die Hardware-Entwicklung ist ebenso bedeutsam. DeepSeek ist eine Partnerschaft mit dem chinesischen Technologiekonzern Huawei eingegangen, der bestätigt hat, das KI-Startup mit seiner „Supernode“-Technologie zu unterstützen, indem er große Cluster seiner Ascend 950-Chips kombiniert, um mehr Rechenleistung bereitzustellen.
„Dadurch können KI-Systeme entwickelt und eingesetzt werden, ohne sich ausschließlich auf Nvidia zu verlassen. Aus diesem Grund könnte V4 letztendlich eine noch größere Wirkung haben als R1 – die Akzeptanz im Inland beschleunigen und insgesamt zu einer schnelleren globalen KI-Entwicklung beitragen.“
— Wei Sun, leitender Analyst, Counterpoint ResearchIvan Su, leitender Aktienanalyst bei Morningstar, erklärte gegenüber CNBC, dass der Marktstart von V4 voraussichtlich nicht dieselbe Wirkung wie der von R1 haben werde, da Händler bereits eingepreist hätten, dass chinesische KI wettbewerbsfähig und kostengünstiger sei. DeepSeeks jüngste Positionierung sieht jedoch andere chinesische Open-Source-Modelle als direkte Konkurrenten. „Eine Herangehensweise, die es bei R1 nicht gab, und allein das zeigt, wie sehr sich der Wettbewerb im Inland verschärft hat.“
Für wen ist DeepSeek V4 geeignet?
Sie führen Codierungsagenten, mehrstufige Schlussfolgerungspipelines oder komplexe Dokumentenanalysen in großem Umfang aus. Die Leistung des SWE-Benchmarks liegt innerhalb der Messgenauigkeit von Claude Opus 4.6 – und das zu einem Bruchteil der Kosten.
Sie benötigen kostenoptimierte Inferenz für hohe Datenmengen, ohne dabei nennenswerte Qualitätseinbußen hinnehmen zu müssen. Mit 0,28 US-Dollar pro Million Output-Tokens ist Flash das kosteneffizienteste Frontier-Class-Modell für Produktionsworkloads.
Sie haben Anforderungen an die Datensouveränität, unterliegen Exportkontrollbestimmungen oder möchten die volle Kontrolle über Ihre Inferenzarchitektur? Die MIT-Lizenz und die Verfügbarkeit von Hugging Face machen dies wirklich zugänglich.
Ihre Arbeitsabläufe sind auf multimodale Eingaben angewiesen, Sie benötigen höchste Leistung bei Aufgaben mit hohem Computereinsatz, oder Ihre Anwendungen beinhalten sensible Daten, bei denen das Hosting bei einem in China ansässigen Unternehmen Bedenken hinsichtlich der Einhaltung der Vorschriften aufwirft.
Häufig gestellte Fragen
DeepSeek V4 ist das Flaggschiffmodell der vierten Generation von DeepSeek und wurde am 24. April 2026 veröffentlicht. Es ist in zwei Varianten erhältlich – V4-Pro (1,6T Parameter, 49B aktiv) und V4-Flash (284B Parameter, 13B aktiv) – die beide ein Kontextfenster von 1 Million Token unter der MIT-Open-Source-Lizenz unterstützen.
Bei Programmier-Benchmarks wie SWE-bench Verified und LiveCodeBench ist V4-Pro-Max mit GPT-5.5 vergleichbar oder sogar überlegen. Bei Benchmarks zur agentenbasierten Computernutzung wie Terminal-Bench 2.0 liegt GPT-5.5 deutlich vorn (82,7 % gegenüber 67,9 %). Der entscheidende Unterschied liegt im Preis: V4-Pro kostet 3,48 US-Dollar pro Million erzeugter Token, GPT-5.5 hingegen 30 US-Dollar.
V4-Flash kostet 0,14 US-Dollar pro Million Input-Token und 0,28 US-Dollar pro Million Output-Token. V4-Pro kostet 1,74 US-Dollar pro Million Input-Token und 3,48 US-Dollar pro Million Output-Token. Beide sind deutlich günstiger als vergleichbare proprietäre Modelle.
Ja. Sowohl V4-Pro als auch V4-Flash werden unter der MIT-Lizenz veröffentlicht, die vollständigen Gewichtungen sind auf Hugging Face verfügbar. Sie können die Modelle herunterladen, ausführen und kommerziell einsetzen, ohne zusätzliche Lizenzgebühren zu zahlen.
Die Modellgewichte können kostenlos heruntergeladen und selbst gehostet werden. Die Weboberfläche unter chat.deepseek.com ist kostenlos zugänglich. Die API-Nutzung wird zu den oben genannten Preisen abgerechnet.
Beide werden am 24. Juli 2026 als veraltet markiert und vollständig eingestellt. Sie werden nun im Nicht-Denkmodus bzw. im Denkmodus auf deepseek-v4-flash abgebildet. Entwickler sollten auf die expliziten V4-Modell-IDs migrieren.
V4-Flash (284 Byte Gesamtparameter, 160 GB auf Hugging Face) ist das optimale Ziel für den lokalen Einsatz in Teams mit Multi-GPU-Systemen. V4-Pro mit 865 GB benötigt hingegen erhebliche Clusterressourcen für produktionsreife Latenzzeiten.
Nein. Version 4 unterstützt ausschließlich Texteingabe. Audio-, Bild- und Videoverarbeitung sind in der aktuellen Version nicht verfügbar.
DeepSeek V4 kann GPT-5.5 oder Claude Opus 4.7 nicht in allen Benchmarks übertreffen. Das ist auch nicht nötig. Das Hauptargument ist wirtschaftlicher Natur: nahezu Spitzenleistung beim Codieren und logischen Schließen, offene Gewichte unter einer freizügigen Lizenz und eine API-Preisgestaltung, die proprietäre Alternativen um den Faktor sieben bis einundzwanzig unterbietet.
Für die Mehrheit der Entwickler und Unternehmen, die mit LLMs arbeiten, lautete die Frage nie: „Welches Modell schneidet in einem Benchmark-Bericht am besten ab?“ Es war immer „Welches Modell bietet akzeptable Qualität zu einem Preis, der das Produkt wirtschaftlich macht?“ DeepSeek V4 verändert diese Rechnung entscheidend für einen bedeutenden Teil der realen Anwendungsfälle.
Neil Shah, Forschungsleiter bei Counterpoint Research, bezeichnete V4 als „einen echten Durchbruch“ und hob die im Vergleich zu Vorgängermodellen geringeren Inferenzkosten hervor. Diese Einschätzung hat sich bestätigt. DeepSeek hat etwas geschafft, was die meisten Beobachter vor 18 Monaten für unwahrscheinlich hielten: ein wirklich wettbewerbsfähiges Open-Source-Modell für leistungsschwache Hardware entwickelt und auf den Markt gebracht, es zu einem Preis angeboten, der die Kaufentscheidungen von Unternehmen beeinflusst, und die Gewichte für jedermann weltweit freigegeben.
Das Rennen um die beste KI verlangsamt sich nicht. Aber es wird nachweislich immer günstiger.
Offizielle API-Dokumentation von DeepSeek · Modellkarte für umarmende Gesichter · CNBC · TechCrunch · Reuters · CNN Business · BuildFastWithAI · Morph LLM · Digital Applied · FelloAI · Kingy AI