 OpenAI - ChatGPT, Sora
OpenAI - ChatGPT, Sora Google - Gemini, Nano Banana
Google - Gemini, Nano Banana Anthropique - Claude
Anthropique - Claude xAI - Grok
xAI - Grok Recherche profonde
Recherche profonde Alibaba - Qwen
Alibaba - Qwen ByteDance - Le meilleur de ByteDance
ByteDance - Le meilleur de ByteDance Tous les modèles
Tous les modèles Plans d'entreprise
Plans d'entreprise Développement d'applications d'IA
Développement d'applications d'IA API de traduction IA
API de traduction IA Service SEO/GEO IA
Service SEO/GEO IA Service de relations publiques géo-optimisé
Service de relations publiques géo-optimisé Service de web scraping
Service de web scraping OpenClaw
OpenClaw Meilleurs outils d'IA
Meilleurs outils d'IA Les meilleurs robots IA
Les meilleurs robots IA
 Se connecter
Se connecter

















Il s'agit de la mise à jour la plus importante de DeepSeek depuis que R1 a bouleversé les marchés mondiaux en janvier 2025. Voici tout ce que vous devez savoir.
Qu'est-ce que DeepSeek V4 ?
DeepSeek V4 est la quatrième génération de la gamme phare de DeepSeek, le laboratoire d'IA basé à Hangzhou qui a bouleversé les marchés mondiaux en janvier 2025 avec son modèle de raisonnement R1 à bas coût. V4 remplace DeepSeek V3 et V3.2, dont le support est arrêté après le 24 juillet 2026.
DeepSeek V4 est une version à double modèle basée sur une architecture Mixture-of-Experts (MoE). Les deux modèles prennent en charge une fenêtre de contexte d'un million de jetons avec une sortie maximale de 384 000 jetons, et sont distribués sous licence MIT, ce qui garantit une utilisation commerciale gratuite et un accès complet aux pondérations sur Hugging Face.
DeepSeek-V4-Pro est la version phare : 1 600 milliards de paramètres au total, 49 milliards actifs par jeton, pré-entraînée sur 33 000 milliards de jetons. DeepSeek-V4-Flash est la version optimisée : 284 milliards de paramètres au total, 13 milliards actifs par jeton, entraînée sur 32 000 milliards de jetons.
Le DeepSeek-V4-Pro est ainsi le plus grand modèle open weight disponible. Il est plus volumineux que le Kimi K2.6 (1,1T) et le GLM-5.1 (754B), et plus de deux fois plus grand que le DeepSeek V3.2 (685B).
Les deux modèles sont actuellement en phase de prévisualisation. Reuters a indiqué que DeepSeek utilise cette période pour recueillir des retours d'expérience concrets avant de finaliser le modèle, sans toutefois préciser de calendrier de finalisation.
L'architecture qui rend cela possible
DeepSeek V4 n'est pas simplement une version plus grande de V3. V4 introduit trois changements architecturaux qui la distinguent de V3.2 : le mécanisme d'attention hybride CSA+HCA, les hyperconnexions à contrainte de variété (mHC) et l'optimiseur Muon. Ensemble, ces éléments expliquent comment un modèle aussi volumineux peut s'exécuter à un coût d'inférence considérablement inférieur à celui de V3.2.
Attention hybride : CSA + HCA
Le principal problème technique que pose la version 4 est le coût de l'attention pour les contextes longs. L'attention des transformateurs standard évolue quadratiquement avec la longueur de la séquence ; l'exécuter sur un million de jetons avec un modèle de cette taille serait économiquement prohibitif.
L'innovation centrale réside dans un mécanisme d'attention hybride qui entrelace l'attention parcimonieuse compressée (CSA) et l'attention fortement compressée (HCA) au sein des couches de transformation. La CSA compresse le cache clé-valeur de chaque groupe de m jetons en une seule entrée grâce à un compresseur appris au niveau du jeton, puis applique une sélection des k meilleurs jetons en fonction de la requête. La HCA pousse la compression plus loin pour les couches tolérant une plus grande approximation.
Le résultat pratique est frappant. Dans le contexte d'un million de jetons, DeepSeek-V4-Pro ne nécessite que 27 % des FLOP d'inférence à jeton unique et 10 % du cache KV par rapport à DeepSeek-V3.2, V4-Flash pousse encore plus loin avec 10 % des FLOPs et 7 % du cache KV.
L'idée clé est que les chiffres d'efficacité ne peuvent être atteints ni par CSA ni par HCA seuls — c'est l'hybride entrelacé qui maintient la qualité du contexte long tout en réduisant les FLOPs et le cache KV d'un ordre de grandeur.
Hyperconnexions à contrainte de variété (mHC)
mHC résout un problème fondamental de l'entraînement des réseaux de neurones profonds : lorsque les modèles atteignent des centaines, voire des milliers de couches, les connexions résiduelles classiques engendrent une instabilité de la propagation du signal. mHC contraint les matrices de mélange au polytope de Birkhoff grâce à l'algorithme de Sinkhorn-Knopp, préservant ainsi l'amplitude du signal à travers le réseau. En d'autres termes : il assure la stabilité de l'entraînement pour des réseaux comportant des milliards de paramètres, là où les architectures précédentes divergeaient.
L'optimiseur de muons
Le modèle V4 est entraîné à l'aide de l'optimiseur Muon, qui utilise la méthode de Newton-Schulz pour approximativement orthogonaliser la matrice de mise à jour du gradient avant de l'appliquer à la mise à jour des poids. Comparé à AdamW, Muon offre une convergence plus rapide et une meilleure stabilité d'entraînement, un atout particulièrement important pour l'entraînement d'un modèle à 1,6 T de paramètres où une instabilité de l'optimiseur serait catastrophique.
Trois modes de raisonnement
Chaque modèle V4 expose trois niveaux d'effort de raisonnement : Ne pas penser, Pensez haut, et Pensez MaxLe mode Max utilise des contextes plus longs et des pénalités de longueur réduites en apprentissage par renforcement ; il est donc recommandé pour les tâches de raisonnement les plus complexes. La différence est significative : sur HLE, le score de V4-Pro passe de 7,7 (sans Think) à 37,7 (Max), soit un gain de près de 5 fois par rapport au même modèle, simplement en allouant davantage de ressources de calcul au raisonnement.
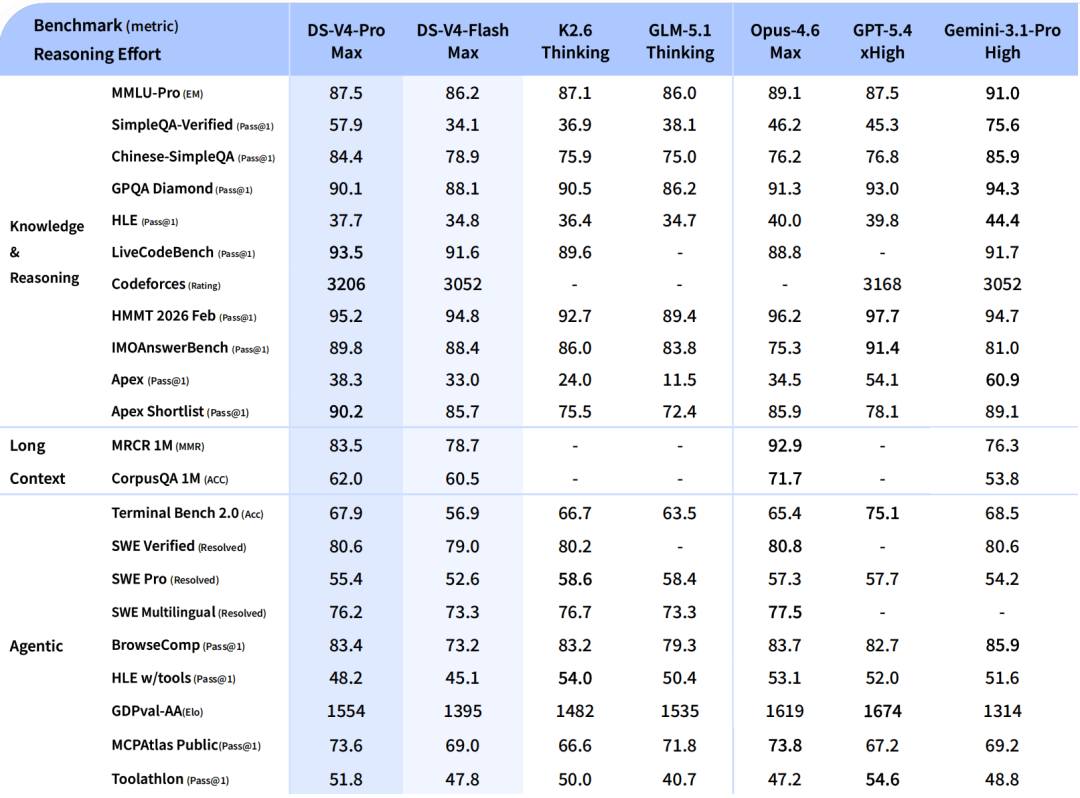
Tests de performance de DeepSeek V4 : Vue d’ensemble
Scores V4-Pro-Max 80,6 % sur le banc d'essai SWE (vérifié) et 93,5 sur LiveCodeBench — le score de référence de codage le plus élevé de tous les modèles actuellement disponibles.
Le contexte concurrentiel est ici déterminant. Claude Opus 4.6 devance légèrement SWE-bench Verified (80,8 % contre 80,6 %) et nettement HLE (40,0 % contre 37,7 %) ainsi que HMMT 2026 Math (96,2 % contre 95,2 %). V4-Pro coûte sept fois moins cher par million de jetons produits.
En mathématiques formelles, les résultats sont exceptionnels. Sur Putnam-2025, qui combine raisonnement informel, vérification formelle et calculs intensifs, V4 atteint un score parfait de 120/120, égalant Axiom et devançant Aristotle (100/120) et Seed-1.5-Prover (110/120). Sur les benchmarks de compétition mathématique, avec un score de 95,2 à HMMT 2026 (février) et de 89,8 à IMOAnswerBench, V4-Pro-Max se situe au même niveau que GPT-5.4.
En programmation compétitive, V4-Pro atteint un classement Codeforces de 3 206, se classant 23e parmi les concurrents humains.
Points faibles du V4-Pro-Max par rapport aux leaders : le V4-Pro-Max est devancé par le Gemini 3.1 Pro sur la plupart des benchmarks exigeants en termes de connaissances, notamment MMLU-Pro, SimpleQA, GPQA Diamond et HLE. L’écart s’est considérablement réduit, mais n’est pas encore comblé.
Comparaison entre DeepSeek V4, GPT-5.5, Claude Opus 4.7 et Gemini 3.1 Pro
| Métrique | DeepSeek V4-Pro | GPT-5.5 | Claude Opus 4.7 | Gemini 3.1 Pro |
|---|---|---|---|---|
| Vérifié par SWE-bench | 80,6% | — | 80,8% | — |
| LiveCodeBench | 93,5 | — | — | — |
| Évaluation Codeforces | 3 206 | — | — | 3 052 |
| HMMT 2026 février | 95,2% | — | 96,2% | — |
| Terminal-Bench 2.0 | 67,9% | 82,7% | 69,4% | 68,5% |
| Prix de sortie de l'API / 1M | 3,48 $ | 30,00 $ | 75,00 $ | — |
| Fenêtre contextuelle | 1 million de jetons | 1 million de jetons | 1 million de jetons | 1 million de jetons |
| Source libre | ✓ AVEC | ✗ | ✗ | ✗ |
| Auto-hébergement | ✓ | ✗ | ✗ | ✗ |
Le modèle V4 Pro coûte 0,145 $ par million de jetons d'entrée et 3,48 $ par million de jetons de sortie, ce qui le rend moins cher que Gemini 3.1 Pro, GPT-5.5, Claude Opus 4.7 et GPT-5.4. À ce niveau de prix, il est difficile pour les concurrents proposant des solutions propriétaires de répondre à cette question concernant le rapport performance/prix.
DeepSeek-V4-Pro démontre des performances supérieures à celles de GPT-5.2 et Gemini 3.0 Pro sur les benchmarks de raisonnement standard, bien que ses performances soient légèrement inférieures à celles de GPT-5.4 et Gemini 3.1 Pro, ce qui suggère une trajectoire de développement qui accuse un retard d'environ 3 à 6 mois par rapport aux modèles de pointe les plus récents.
Prix : le chiffre qui change tout
Le modèle V4-Flash plus petit coûte 0,14 $ par million de jetons d'entrée et 0,28 $ par million de jetons de sortie, ce qui est inférieur aux modèles GPT-5.4 Nano, Gemini 3.1 Flash, GPT-5.4 Mini et Claude Haiku 4.5.
Avec des taux d'échec de cache, V4-Pro coûte environ un septième de GPT-5.5 et environ un sixième de Claude Opus 4.7 pour un débit équivalent.
V4-Pro-Max, à 3,48 $ par million de jetons de production, offre des performances comparables à celles de Claude Opus 4.6 (75 $ par million de jetons de production) à seulement 0,2 point près. Réduction des coûts de 21 fois avec des performances de référence en matière de codage quasi identiques. Pour les équipes exécutant des milliers de tâches de codage automatisé par jour, cela change la donne en matière de faisabilité économique.
Le prix de V4-Flash mérite une attention particulière pour les cas d'utilisation à fort volume. L'écart entre Flash et Pro est faible : Flash concède environ 1 à 2 points de moins sur la plupart des benchmarks, en échange d'un coût d'API 12 fois inférieur. Pour la plupart des applications de production ne nécessitant pas des performances de raisonnement maximales, V4-Flash représente le choix économique optimal.
Comment accéder à DeepSeek V4 aujourd'hui
DeepSeek V4 est disponible de trois manières. Premièrement, via chat.deepseek.com — Le chatbot web expose V4 via deux options : le mode Expert (V4-Pro) et le mode Instantané (V4-Flash). Deuxièmement, via l’API DeepSeek à l’aide des identifiants de modèle. deepseek-v4-pro et deepseek-v4-flashTroisièmement, en tant que poids libres sur Hugging Face sous licence MIT, permettant une utilisation commerciale gratuite et un déploiement local.
Les deux modèles prennent en charge un contexte 1M et deux modes (pensée et non-pensée). Notez que chat deepseek et deepseek-reasoner sera totalement mis hors service et inaccessible après 24 juillet 2026Les développeurs utilisant des alias existants doivent migrer vers les identifiants de modèle V4 explicites avant cette date limite.
Les versions V4-Pro et V4-Flash prennent toutes deux en charge les formats OpenAI ChatCompletions et API Anthropic. Pour la plupart des équipes, l'intégration se limite donc à la mise à jour d'un paramètre du modèle ; aucune modification de l'URL de base n'est nécessaire.
Pour l'auto-hébergement : les poids V4-Flash constituent la cible idéale. Avec 284 milliards de paramètres et 13 milliards activés par jeton, V4-Flash peut fonctionner sur une configuration multi-GPU accessible à la plupart des équipes de taille moyenne. V4-Pro, avec 1,6 T de paramètres au total, exige une capacité de cluster importante pour garantir une latence de production ; la plupart des équipes utiliseront l'API DeepSeek pour la version Pro et envisageront l'auto-hébergement uniquement pour la version Flash.
Points faibles de DeepSeek V4
Une analyse honnête exige de reconnaître les véritables limites que DeepSeek documente elle-même.
V4 Flash et V4 Pro ne prennent en charge que le texte, contrairement à de nombreux logiciels propriétaires qui permettent la lecture et la génération d'audio, de vidéo et d'images. Pour les applications multimodales, V4 n'est actuellement pas compétitif.
Pour les tâches exigeant une forte intensité de connaissances, l'écart avec les modèles propriétaires de pointe persiste. DeepSeek fait preuve d'une franchise inhabituelle dans son rapport technique concernant les limitations restantes de la V4 : la V4-Pro-Max est devancée par la Gemini 3.1 Pro sur la plupart des benchmarks nécessitant une intensité de connaissances élevée. L'écart s'est considérablement réduit, mais n'est pas encore comblé.
Pour les flux de travail d'agents à la frontière absolue, V4-Pro-Max égale les leaders sur SWE Verified (80,6) mais est à la traîne sur SWE Pro (55,4) et sur Terminal-Bench 2.0. Pour le codage d'agents purs à la frontière, GPT-5.5 et Opus 4.7 semblent toujours plus forts.
DeepSeek reconnaît également la complexité architecturale comme une limitation qu'elle s'est elle-même identifiée — l'équipe décrit l'architecture V4 comme « relativement complexe » et déclare que les versions futures viseront à la réduire à ses conceptions les plus essentielles.
La dimension géopolitique que vous ne pouvez ignorer
DeepSeek V4 n'est pas apparu de nulle part. Son lancement intervient au lendemain des accusations américaines contre la Chine, soupçonnée de vol à grande échelle de la propriété intellectuelle de laboratoires d'IA américains via des milliers de comptes proxy. DeepSeek est elle-même accusée par Anthropic et OpenAI de « distiller », c'est-à-dire de copier, leurs modèles d'IA.
L'aspect matériel est tout aussi important. DeepSeek s'est associé au géant technologique chinois Huawei, qui a confirmé son soutien à la start-up spécialisée en IA grâce à sa technologie « Supernode », qui combine de grands clusters de ses puces Ascend 950 pour fournir une puissance de calcul accrue.
« Cela permet de construire et de déployer des systèmes d'IA sans dépendre uniquement de Nvidia, c'est pourquoi la V4 pourrait finalement avoir un impact encore plus important que la R1 — en accélérant l'adoption au niveau national et en contribuant à un développement mondial de l'IA plus rapide dans son ensemble. »
— Wei Sun, analyste principal, Counterpoint ResearchIvan Su, analyste actions senior chez Morningstar, a déclaré à CNBC que le lancement de V4 n'aura probablement pas le même impact sur le marché que celui de R1, car les investisseurs ont déjà intégré le fait que l'IA chinoise est compétitive et moins coûteuse à utiliser. Cependant, le dernier positionnement de DeepSeek place d'autres modèles open source chinois en concurrence directe. « Un cadre qui n'existait pas avec R1, et cela seul en dit long sur l'intensification de la concurrence intérieure. »
Qui devrait utiliser DeepSeek V4 ?
Vous exécutez des agents de codage, des pipelines de raisonnement multi-étapes ou des analyses documentaires complexes à grande échelle. Les performances de SWE-bench sont comparables à celles de Claude Opus 4.6, à un coût bien inférieur.
Vous avez besoin d'une inférence à haut volume optimisée en termes de coûts, sans trop sacrifier la qualité. À 0,28 $ par million de jetons de sortie, Flash est le modèle de pointe le plus rentable pour les charges de travail en production.
Vous avez des exigences en matière de souveraineté des données, vous êtes soumis à des contraintes de contrôle des exportations ou vous souhaitez un contrôle total sur votre pile d'inférence ? La licence MIT et la disponibilité de Hugging Face rendent cette solution véritablement accessible.
Vos flux de travail dépendent d'entrées multimodales, vous avez besoin d'une maîtrise absolue des tâches d'utilisation d'ordinateurs automatisés, ou vos applications impliquent des données sensibles pour lesquelles l'hébergement auprès d'une société domiciliée en Chine soulève des problèmes de conformité.
Foire aux questions
DeepSeek V4 est le modèle phare de quatrième génération de DeepSeek, sorti le 24 avril 2026. Il existe en deux variantes : V4-Pro (1,6 T de paramètres, 49 B actifs) et V4-Flash (284 B de paramètres, 13 B actifs), toutes deux prenant en charge une fenêtre de contexte de 1 million de jetons sous la licence open-source MIT.
Sur les benchmarks de programmation tels que SWE-bench Verified et LiveCodeBench, V4-Pro-Max rivalise avec GPT-5.5, voire le surpasse. Sur les benchmarks d'utilisation d'ordinateurs automatisés comme Terminal-Bench 2.0, GPT-5.5 prend une nette avance (82,7 % contre 67,9 %). La principale différence réside dans le prix : V4-Pro coûte 3,48 $ par million de jetons produits, contre 30 $ pour GPT-5.5.
V4-Flash coûte 0,14 $ par million de jetons d'entrée et 0,28 $ par million de jetons de sortie. V4-Pro coûte 1,74 $ par million de jetons d'entrée et 3,48 $ par million de jetons de sortie. Ces deux solutions sont nettement moins chères que les modèles propriétaires comparables.
Oui. Les modèles V4-Pro et V4-Flash sont distribués sous licence MIT et leurs poids complets sont disponibles sur Hugging Face. Vous pouvez les télécharger, les exécuter et les utiliser commercialement sans frais de licence supplémentaires.
Les poids du modèle sont téléchargeables et hébergeables gratuitement. L'interface web, accessible à l'adresse chat.deepseek.com, est gratuite. L'utilisation de l'API est facturée aux tarifs indiqués ci-dessus.
Ces deux composants seront obsolètes et définitivement supprimés le 24 juillet 2026. Ils correspondent désormais à deepseek-v4-flash en modes Non-Thinking et Thinking respectivement. Les développeurs doivent migrer vers les identifiants de modèle V4 explicites.
La V4-Flash (284 octets de paramètres au total, 160 Go sur Hugging Face) est la solution idéale pour un déploiement local dans les équipes disposant de configurations multi-GPU. La V4-Pro, avec ses 865 Go, nécessite d'importantes ressources de cluster pour une latence optimale en production.
Non, la version V4 prend uniquement en charge la saisie de texte. Le traitement audio, image et vidéo n'est pas disponible dans cette version.
DeepSeek V4 ne surpasse pas GPT-5.5 ni Claude Opus 4.7 sur tous les benchmarks. Ce n'est pas nécessaire. Son principal atout est économique : des performances de codage et de raisonnement quasi-optimales, des poids ouverts sous une licence permissive et une API dont le prix est sept à vingt et un fois inférieur à celui des alternatives propriétaires.
Pour la majorité des développeurs et des entreprises qui utilisent des LLM, la question n'a jamais été « quel modèle obtient le meilleur score sur une fiche de référence ? » C'était toujours « Quel modèle offre une qualité acceptable à un coût qui rend le produit viable ? » DeepSeek V4 fait évoluer ce calcul de manière décisive pour une part importante des cas d'utilisation concrets.
Neil Shah, vice-président de la recherche chez Counterpoint Research, a qualifié la version V4 de « véritable prouesse technique », soulignant ses coûts d'inférence inférieurs à ceux des modèles précédents. Cette appréciation se confirme. DeepSeek a accompli ce que la plupart des observateurs jugeaient improbable il y a dix-huit mois : concevoir et commercialiser un modèle open source véritablement compétitif sur du matériel aux capacités limitées, le proposer à un prix susceptible d'influencer les décisions d'achat des entreprises et mettre les poids à la disposition de tous.
La course à l'IA ne ralentit pas. Mais elle devient, de façon manifeste, moins coûteuse.
Documentation officielle de l'API DeepSeek · Carte du modèle Hugging Face · CNBC · TechCrunch · Reuters · CNN Business · BuildFastWithAI · Morph LLM · Digital Applied · FelloAI · Kingy AI