 OpenAI - ChatGPT、Sora
OpenAI - ChatGPT、Sora Google - Gemini,Nano Banana
Google - Gemini,Nano Banana Anthropic - Claude
Anthropic - Claude xAI - Grok
xAI - Grok DeepSeek
DeepSeek 阿里巴巴 - Qwen
阿里巴巴 - Qwen 字节跳动 - 豆包
字节跳动 - 豆包 所有型号
所有型号 企业API定制计划
企业API定制计划 AI应用开发服务
AI应用开发服务 AI智能翻译API
AI智能翻译API AI SEO/GEO 服务
AI SEO/GEO 服务 GEO/AI大模型优化
GEO/AI大模型优化 网络爬虫服务
网络爬虫服务 OpenClaw
OpenClaw 顶级人工智能工具
顶级人工智能工具 顶级人工智能机器人
顶级人工智能机器人
 登录
登录














小米 MiMo V2.5:
310B 型号 赶上 Claude·奥普斯谈Tokens效率。
小米的 MiMo V2.5 这是 2026 年第二季度最重要的开源版本——一个 3100 亿稀疏混合专家模型,具备原生多模态理解能力、100 万个词元的上下文窗口,其基准测试结果使其与 Claude Opus 和 Gemini 3 Pro 不相上下,同时还具备烧录能力。 Tokens数量减少 40-60%以下是完整的分析:架构、基准测试、实际任务、定价,以及它与闭源前沿技术的对比。

什么是小米 MiMo V2.5?
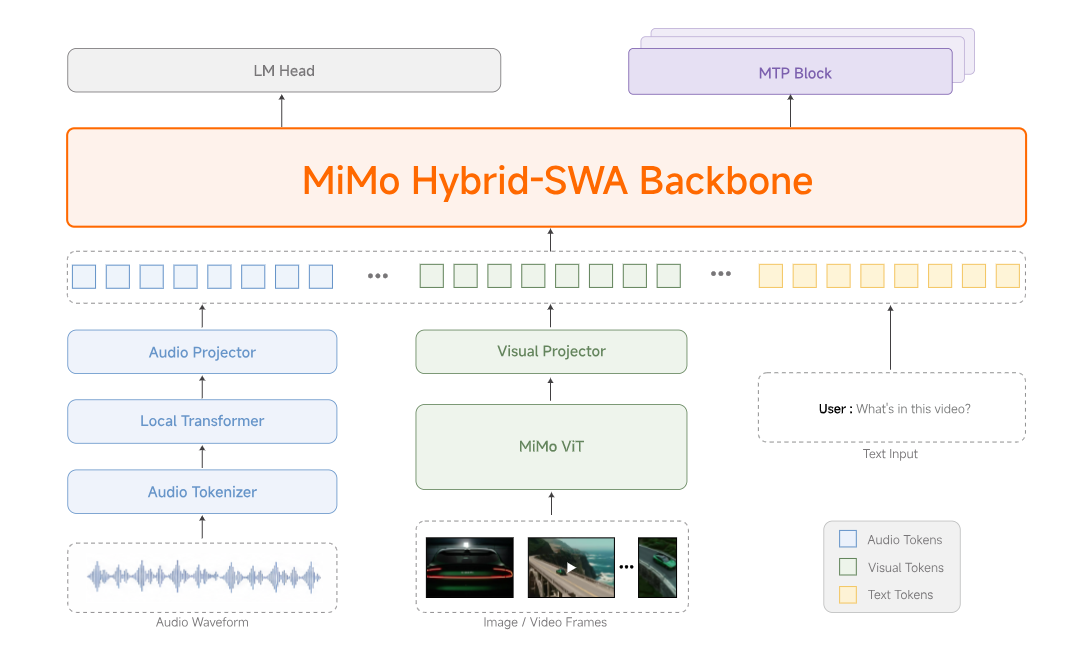
MiMo V2.5 是该系列的最新型号。 小米的MiMo团队于 2026 年 4 月下旬发布,并直接推向 拥抱脸 作为开放重量级耳机。实际上,此次发布包含两款旗舰型号,外加一套TTS耳机和一款ASR耳机——这种区别很重要,因为网上大多数宣传都将它们混为一谈。
这条线是这样分开的:
- MiMo-V2.5 — “全能型”多模态通才。
310B 总参数,15B 活跃采用稀疏 MoE 架构,基于 48T 个 token 进行训练。原生支持视觉和音频理解。全能型模型。 - MiMo-V2.5-Pro — “特工”专家。
1.02T 总参数,42B 活跃. 相同的混合注意力机制,但针对长时程编码和数千次工具调用轨迹进行了深度调整。 - MiMo-V2.5-TTS — 包含三种语音模式(TTS、VoiceDesign、VoiceClone)的语音套件,用于生成生产语音,并可通过风格指令控制速度、情感和语调。
- MiMo-V2.5-ASR — 端到端语音识别,可处理中文方言(吴语、粤语、闽南语、四川语)、语码转换语音、歌词和嘈杂的声学环境。
这两款旗舰机型都采用了自主研发的处理器。 混合滑动窗口注意力机制 架构继承自 MiMo-V2-Flash,配备专用的视频和音频编码器,并通过轻型投影仪连接。两者均带有原生功能。 1,048,576 个令牌的上下文窗口两者都不收取上下文长度倍增费用——小米在发布当天就取消了这项功能。
MiMo V2.5 对比 Claude Opus、Gemini 3 Pro、GPT-5.4
小米此次发布会重点宣传的基准测试是: ClawEval这是一个多轮智能体任务套件,其中模型需要进行规划、调用工具并在较长的时间范围内迭代。 这 该基准测试与实际生产代理工作负载相对应,而 MiMo V2.5 在这方面表现最为出色。
| 模型 | ClawEval Pass³ | Tokens/轨迹 | 成本调整排名 |
|---|---|---|---|
| MiMo V2.5-Pro | 63.8% – 64.0% | 约7万 | #1(帕累托前沿) |
| MiMo V2.5(基础版) | 62.3% | 约7.5万 | 边界 |
| Claude作品 4.6 | 约65.4% | 约120–175K | 成本更高 |
| Gemini 3.1 Pro | 约63% | 约11.5万 | 成本更高 |
| GPT-5.4 | 约62% | 约11万 | 成本更高 |
要点: Claude Opus 4.6 在原始性能方面仍然略胜一筹。但 MiMo V2.5-Pro 达到相同效果的同时,所需Tokens数量却减少了约 40-60%。按每条轨迹的价格计算,这是 不是 舍入误差。 VentureBeat 指出在 GitHub Copilot 和大多数代理平台都转向按使用量计费的世界里,这种Tokens效率对于任何大规模运行代理的团队来说,都能直接转化为真金白银。
在其他方面,这则展现出一位以编码为先的专家形象:
- SWE-bench Pro:
57.2%— 与 Claude Opus 4.6 和 GPT-5.4 的差距在 0.5 分以内。 - Terminal-Bench 2.0: 完全领先于 Opus 4.6 和 Gemini 3.1 Pro。
- 视频-MME:
87.7— 视频理解能力与 Gemini 3 Pro 相当。 - GDPVal-AA(Elo):
1581— 超越 Kimi K2.6 和 GLM 5.1。 - 长时程回忆(1M):
0.37 BFS / 0.62 父母— 大多数竞争对手在 512K 之后销量就几乎跌至零。
它的不足之处: HLE(人类的最后考试) 和 GDPVal-AA 广泛推理 两者都更注重通用技能的广度,而非编程专长的深度。如果你需要一位导师或博学之士,这种模式并不适用。但如果你需要的是一位能够交付代码的代理人,那它绝对是最佳选择。
MiMo V2.5-Pro 究竟能做什么?
跑分是一回事,小米更进一步,发布了四项跑分数据。 数小时自主任务运行 ——这类工作无法对代理进行全程指导。这些演示值得认真对待,因为它们包含了完整的工具调用跟踪记录。
真正需要深入理解的是 Rust 编译器的运行过程。它并非儿戏,而是北大一个真正的课程项目,拥有完整的隐藏测试套件。在如此有限的预算下,传统的闭源模式很难一次性完成。这才是“长期一致性”在生产环境中的实际应用。
MiMo V2.5 的定价——以及为什么这才是真正的故事
开源定位的有趣之处就在这里。MiMo V2.5 的发布价格低于 在拥抱脸上摆出开放的重量 对于自托管用户,小米还运营着一个托管 API,定价极具竞争力——以及一个类似于 Claude Code 和 OpenAI 的固定费率订阅模式的“Tokens计划”。
需要注意两点:缓存命中率将输入成本降低到极低水平 0.20-0.40美元 每百万个Tokens,小米进行了缓存写入 免费 仅限有限的发布窗口。100万上下文乘数也已取消。如果您运行的是长期代理,那么与闭源前沿模型相比,实际成本差距更接近于 10倍 比 5倍。
对于偏好固定费率的团队,四级费率方案可供选择。 Tokens计划 从 每年 63.36 美元 (精简版,7.2亿积分) 每年1056美元 (最多 192 亿积分)——并且与 Claude Code、OpenCode 和 Kilo 兼容,可作为即插即用的脚手架。
你应该使用MiMo V2.5吗? 优点、缺点以及适用人群。
优势
- 在代理任务中具有一流的令牌效率(比 Claude Opus 4.6 少 40-60% 的令牌)。
- 真正的 100 万Tokens可用上下文——不会像大多数竞争对手那样在 51.2 万Tokens以下崩溃。
- 单个模型中的原生多模态(图像、视频、音频、文本)。
- Hugging Face 上的开放重量 - 可自托管,可微调。
- “利用感知能力”——在数千次工具调用中主动管理自身的上下文。
- 可直接与 Claude Code、OpenCode、Kilo 兼容。
弱点
- 在广泛推理基准测试(HLE、GDPVal-AA)中表现优异——以编码为先的设计理念。
- 自我报告的Tokens效率数据需要独立验证。
- 中国境外的托管基础设施仍在发展完善中,延迟情况不一。
- 工具调用生态系统和集成不如 Claude 或 GPT 那样经过实战检验。
- 文档和社区支持方面仍落后于西方医疗机构。
哪些人应该使用 MiMo V2.5
如果你正在建造 智能体编码工作流程 如果您需要具备长期、多工具、仓库规模等特性,并且您的单位经济效益取决于Tokens成本,那么 MiMo V2.5-Pro 现在已列入候选名单。对于任何运行具有大量视频或文档理解能力的多模态代理的团队来说,情况也是如此。
谁应该继续使用 Claude 还是 GPT?
如果你的主要工作是 广泛推理的聊天、研究综合或一般知识工作Claude Opus 4.7 和 GPT-5.5 仍然占据优势。西方模型还拥有更成熟的工具生态系统、更长的生产负载稳定性记录以及更强的企业数据处理保障。
常见问题解答
MiMo V2.5 真的是开源的吗?
MiMo V2.5 比 Claude Opus 4.7 更好吗?
MiMo V2.5 通过 API 提供的价格是多少?
MiMo V2.5 可以与 Claude Code 或 OpenCode 一起使用吗?
我需要哪些硬件才能自行运行 MiMo V2.5?
什么是“提升意识”?它为什么重要?
开源前沿阵地已经转移了。
MiMo V2.5 并非适用于所有工作负载的 Claude Opus 替代品,但对于大规模智能编码而言,它已成为成本调整后的全新领先者,并且与闭源技术之间的差距已微乎其微。我们将持续追踪其在实际应用中的复现情况、第三方基准测试以及生态系统的采纳情况。