 OpenAI - ChatGPT, Sora
OpenAI - ChatGPT, Sora Google - Gemini, Nano Banana
Google - Gemini, Nano Banana Antrópico - Claude
Antrópico - Claude xAI - Grok
xAI - Grok Busca profunda
Busca profunda Alibaba - Qwen
Alibaba - Qwen ByteDance - O Melhor da ByteDance
ByteDance - O Melhor da ByteDance Todos os modelos
Todos os modelos Planos Empresariais
Planos Empresariais Desenvolvimento de aplicações de IA
Desenvolvimento de aplicações de IA API de tradução de IA
API de tradução de IA Serviço de SEO/GEO com IA
Serviço de SEO/GEO com IA Serviço de Relações Públicas Otimizado por Geolocalização
Serviço de Relações Públicas Otimizado por Geolocalização Serviço de Web Scraping
Serviço de Web Scraping OpenClaw
OpenClaw Principais ferramentas de IA
Principais ferramentas de IA Os melhores robôs de IA
Os melhores robôs de IA
 Conecte-se
Conecte-se















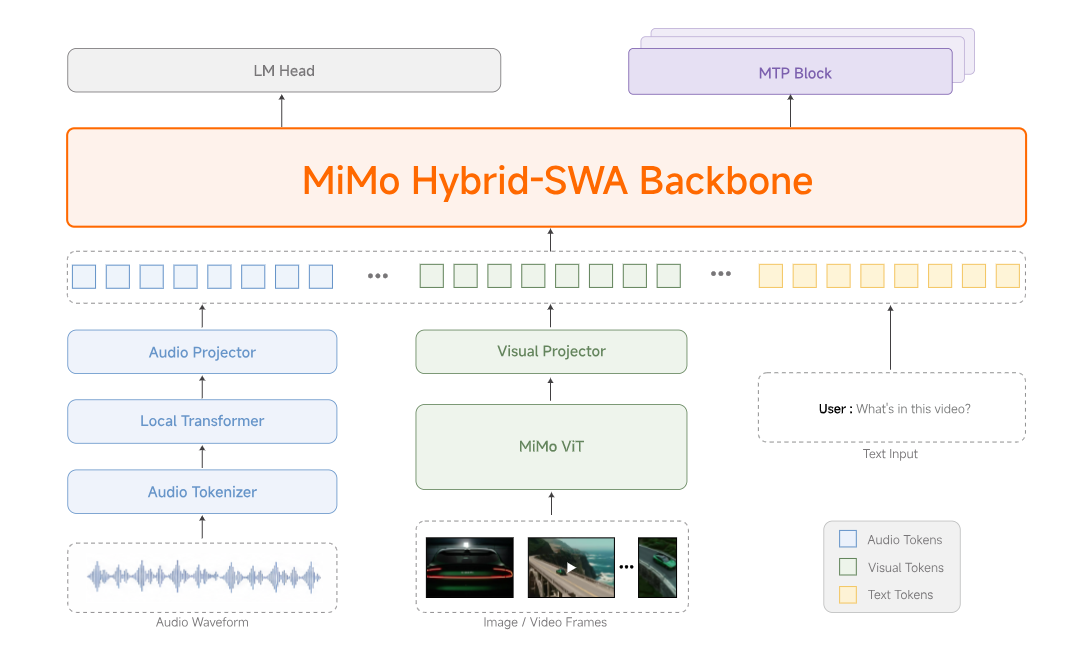
Xiaomi MiMo V2.5:
O modelo 310B que acabou de... alcançado Claude Opus sobre eficiência de tokens.
MiMo V2.5 da Xiaomi é o lançamento open-weight mais importante do segundo trimestre de 2026 — um modelo Mixture-of-Experts esparso de 310 bytes com compreensão multimodal nativa, uma janela de contexto de 1 milhão de tokens e números de benchmark que o colocam em pé de igualdade com o Claude Opus e o Gemini 3 Pro, enquanto consome recursos. 40–60% menos fichasAqui está a análise completa: arquitetura, benchmarks, tarefas do mundo real, preços e como se compara com a vanguarda do código fechado.

O que é Xiaomi MiMo V2.5?
MiMo V2.5 é a mais recente família de modelos da Equipe MiMo da Xiaomi, lançado no final de abril de 2026 e adiado diretamente para Rosto de abraço como pesos livres. Na verdade, existem dois modelos principais no lançamento, além de um modelo TTS e um modelo ASR — e essa distinção é importante porque a maior parte da propaganda online os confunde.
A linha se divide assim:
- MiMo-V2.5 — O generalista multimodal "Omni".
310B parâmetros totais,15B ativoArquitetura MoE esparsa, treinada em 48 trilhões de tokens. Compreensão nativa de visão e áudio. A solução completa. - MiMo-V2.5-Pro — O especialista em "Agentes".
1,02T parâmetros totais,42B ativoA mesma estrutura de atenção híbrida, mas otimizada para codificação de longo prazo e trajetórias com milhares de chamadas de ferramentas. - MiMo-V2.5-TTS — Um conjunto de três modelos de voz (TTS, VoiceDesign, VoiceClone) para geração de fala em produção, com controle de estilo sobre velocidade, emoção e tom.
- MiMo-V2.5-ASR — Reconhecimento de fala de ponta a ponta que lida com dialetos chineses (Wu, cantonês, hokkien, sichuanês), fala com alternância de código, letras de músicas e ambientes acústicos ruidosos.
Ambos os modelos principais compartilham um mecanismo interno atenção híbrida de janela deslizante Arquitetura herdada do MiMo-V2-Flash, com codificadores dedicados de áudio e vídeo conectados por meio de projetores leves. Ambos são fornecidos com um recurso nativo. Janela de contexto com 1.048.576 tokensNenhuma das duas cobra um multiplicador de comprimento de contexto — a Xiaomi removeu isso no dia do lançamento.
MiMo V2.5 vs Claude Opus, Gemini 3 Pro, GPT-5.4
O principal indicador de desempenho — e aquele com o qual a Xiaomi liderou o lançamento — é Avaliação da Garra, um conjunto de tarefas agenciais de múltiplas etapas, onde o modelo precisa planejar, acionar ferramentas e iterar em longos horizontes temporais. Isto é o benchmark que mapeia cargas de trabalho de agentes de produção reais, e é onde o MiMo V2.5 demonstra maior força.
| Modelo | ClawEval Pass³ | Tokens / Trajetória | Classificação ajustada ao custo |
|---|---|---|---|
| MiMo V2.5-Pro | 63,8 – 64,0% | ~70 mil | #1 (Fronteira de Pareto) |
| MiMo V2.5 (base) | 62,3% | ~75 mil | fronteira empatada |
| Claude Opus 4.6 | ~65,4% | ~120–175 mil | Custo mais elevado |
| Gemini 3.1 Pro | ~63% | ~115 mil | Custo mais elevado |
| GPT-5.4 | ~62% | ~110 mil | Custo mais elevado |
A principal conclusão: Claude Opus 4.6 ainda possui uma ligeira vantagem em termos de capacidade bruta., mas o MiMo V2.5-Pro atinge o mesmo resultado gastando aproximadamente 40 a 60% menos tokens. Em termos de preço por trajetória, isso é não um erro de arredondamento. Como A VentureBeat observouEm um mundo onde o GitHub Copilot e a maioria das plataformas de agentes estão migrando para a cobrança baseada no uso, essa eficiência do token se traduz diretamente em dinheiro real para qualquer equipe que execute agentes em grande escala.
Em outros benchmarks, o cenário é o de um especialista que prioriza a programação:
- SWE-bench Pro:
57,2%— dentro de meio ponto do Claude Opus 4.6 e do GPT-5.4. - Bancada de terminais 2.0: Lidera o Opus 4.6 e o Gemini 3.1 Pro de forma absoluta.
- Vídeo-MME:
87,7— em pé de igualdade com o Gemini 3 Pro em termos de compreensão de vídeo. - GDPVal-AA (Elo):
1581— supera Kimi K2.6 e GLM 5.1. - Recordação de contexto longo (1M):
0,37 BFS / 0,62 Pais— onde a maioria dos concorrentes despenca para perto de zero após 512 mil.
Onde apresenta deficiências: HLE (Último Exame da Humanidade) e Raciocínio amplo GDPVal-AA — ambos priorizam a abrangência de conhecimentos gerais em detrimento da especialização em programação. Se você precisa de um tutor ou de um polímata, este não é o modelo ideal. Mas se você precisa de um agente que implemente código, este definitivamente é.
O que o MiMo V2.5-Pro realmente pode fazer?
Os benchmarks são uma coisa. A Xiaomi foi além e publicou quatro. Execução de tarefas autônomas de várias horas — o tipo de trabalho em que o agente não pode ser supervisionado individualmente. Essas são as demonstrações que valem a pena levar a sério, porque incluem o rastreamento completo das chamadas da ferramenta.
A execução do compilador Rust é o que deve ser internalizado. Não é um brinquedo. É um projeto real de um curso de PKU com um conjunto de testes oculto real, e um modelo de código fechado de ponta teria dificuldades para fazê-lo de uma só vez com esse orçamento simbólico. É assim que a expressão "coerência de longo prazo" realmente se traduz em produção.
Preços do MiMo V2.5 — e por que essa é a verdadeira história.
É aqui que o posicionamento de código aberto fica interessante. O MiMo V2.5 é distribuído sob Pesos livres no Hugging Face Para hospedagem própria, a Xiaomi oferece uma API hospedada com preços agressivos e um modelo de assinatura "Plano Token" semelhante às ofertas de preço fixo da Claude Code e da OpenAI.
Duas coisas a destacar: os acertos no cache reduzem o custo de entrada a níveis tão baixos quanto $ 0,20–0,40 por milhão de tokens, e a Xiaomi fez gravação em cache gratuitamente por um período de lançamento limitado. O multiplicador de 1 milhão de contextos também foi removido. Se você estiver executando agentes de longo prazo, a diferença real de custo em comparação com os modelos de fronteira de código fechado estará mais próxima de 10× que 5×.
Para equipes que preferem taxas fixas, existem quatro níveis. Plano de Tokens vai de $ 63,36/ano (Versão Lite, 720 milhões de créditos) para US$ 1.056/ano (Máx. 19,2 bilhões de créditos) — e é compatível com Claude Code, OpenCode e Kilo como estruturas de substituição direta.
Você deve usar o MIMO V2.5? Prós, contras e para quem é indicado.
Pontos fortes
- Melhor eficiência de tokens da categoria em tarefas agentivas (40–60% menos tokens do que o Claude Opus 4.6).
- Contexto genuinamente utilizável para 1 milhão de tokens — não colapsa abaixo de 512 mil como a maioria dos concorrentes.
- Multimodal nativo em um único modelo (imagem, vídeo, áudio, texto).
- Pesos livres no Hugging Face — auto-hospedáveis e com ajustes precisos.
- "Conhecimento do contexto" — gerencia ativamente seu próprio contexto em milhares de chamadas de ferramentas.
- Compatível com Claude Code, OpenCode e Kilo.
Pontos fracos
- Testes em benchmarks de raciocínio amplo (HLE, GDPVal-AA) — com foco na codificação desde a concepção.
- Os dados autodeclarados sobre a eficiência dos tokens precisam de replicação independente.
- A infraestrutura hospedada fora da China ainda está em fase de amadurecimento — a latência varia.
- O ecossistema de chamadas de ferramentas e as integrações de recursos são menos testados em batalha do que Claude ou GPT.
- A documentação e o apoio da comunidade ainda estão a alcançar os níveis dos fornecedores ocidentais.
Quem deve usar o MiMo V2.5?
Se você estiver construindo fluxos de trabalho de codificação agética — longo prazo, multiferramenta, escalabilidade de repositório — e se a sua economia unitária depende do custo do token, o MiMo V2.5-Pro agora está na lista de opções. O mesmo vale para qualquer equipe que utilize agentes multimodais com forte capacidade de processamento de vídeo ou documentos.
Quem deve ficar com Claude ou com GPT?
Se sua principal carga de trabalho for bate-papo de raciocínio amplo, síntese de pesquisa ou trabalho de conhecimento geralClaude Opus 4.7 e GPT-5.5 ainda mantêm a vantagem. Os modelos ocidentais também possuem ecossistemas de ferramentas mais maduros, histórico mais longo de estabilidade sob carga de produção e garantias mais robustas em relação ao processamento de dados corporativos.
Perguntas frequentes
O MiMo V2.5 é realmente de código aberto?
O MiMo V2.5 é melhor que o Claude Opus 4.7?
Qual o custo do MiMo V2.5 via API?
Posso usar o MiMo V2.5 com o Claude Code ou o OpenCode?
Que hardware preciso para hospedar o MIMO V2.5 por conta própria?
O que é "consciência da importância da captura de sementes" e por que isso é importante?
A fronteira do código aberto acaba de se expandir.
MiMo V2.5 não substitui o Claude Opus para todas as cargas de trabalho, mas para programação ágena em grande escala, é o novo líder em termos de custo ajustado, e a diferença para a fronteira do código proprietário está oficialmente ao nosso alcance. Acompanharemos a replicação no mundo real, benchmarks de terceiros e a adoção pelo ecossistema à medida que evolui.