 OpenAI - ChatGPT, Sora
OpenAI - ChatGPT, Sora Google - Gemini, Nano Banana
Google - Gemini, Nano Banana Antrópico - Claude
Antrópico - Claude xAI - Grok
xAI - Grok Búsqueda profunda
Búsqueda profunda Alibaba - Reina
Alibaba - Reina ByteDance - Lo mejor de ByteDance
ByteDance - Lo mejor de ByteDance Todos los modelos
Todos los modelos Planes empresariales
Planes empresariales Desarrollo de aplicaciones de IA
Desarrollo de aplicaciones de IA API de traducción de IA
API de traducción de IA Servicio de SEO/GEO con IA
Servicio de SEO/GEO con IA Servicio de relaciones públicas geooptimizado
Servicio de relaciones públicas geooptimizado Servicio de extracción de datos web
Servicio de extracción de datos web OpenClaw
OpenClaw Las mejores herramientas de IA
Las mejores herramientas de IA Los mejores robots de IA
Los mejores robots de IA
 Acceso
Acceso














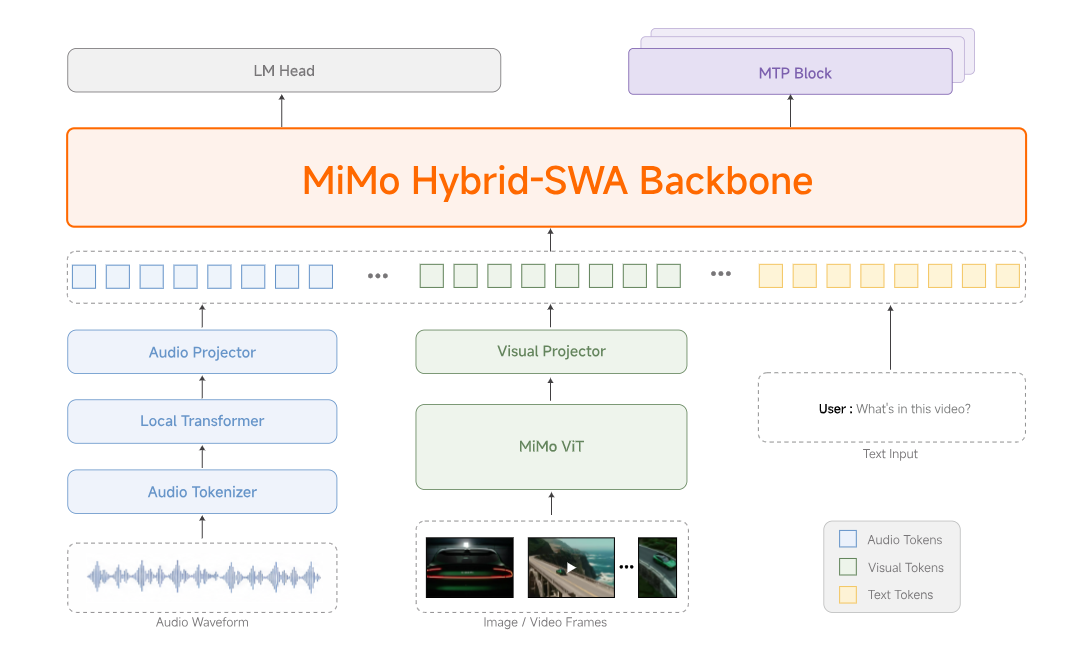
Xiaomi MiMo V2.5:
El modelo 310B que simplemente alcanzado Claude Opus habló sobre la eficiencia de los tokens.
MiMo V2.5 de Xiaomi es el lanzamiento de peso abierto más trascendental del segundo trimestre de 2026: un modelo Mixture-of-Experts disperso de 310 mil millones con comprensión multimodal nativa, una ventana de contexto de 1 millón de tokens y cifras de referencia que lo colocan codo a codo con Claude Opus y Gemini 3 Pro mientras que quema Entre un 40% y un 60% menos de fichasAquí tienes el desglose completo: arquitectura, pruebas de rendimiento, tareas del mundo real, precios y cómo se compara con la vanguardia del software de código cerrado.

¿Qué es Xiaomi MiMo V2.5?
MiMo V2.5 es la última familia de modelos de El equipo MiMo de Xiaomi, lanzado a finales de abril de 2026 y lanzado directamente a Cara de abrazo como pesos abiertos. En realidad, hay dos modelos insignia en el lanzamiento, además de un conjunto TTS y un modelo ASR, y esa distinción importa porque la mayor parte de la publicidad en línea los confunde.
La línea se divide así:
- MiMo-V2.5 — El generalista multimodal "omni".
310B parámetros totales,15 mil millones activosArquitectura MoE dispersa, entrenada con tokens 48T. Comprensión nativa de visión y audio. Todo en uno. - MiMo-V2.5-Pro — El especialista en "Agentes".
1,02T parámetros totales,42B activo. La misma estructura de atención híbrida, pero ajustada específicamente para la codificación a largo plazo y trayectorias con miles de llamadas a herramientas. - MiMo-V2.5-TTS — Un conjunto de tres modelos de voz (TTS, VoiceDesign, VoiceClone) para la generación de voz en producción, con control de estilo mediante instrucciones sobre velocidad, emoción y tono.
- MiMo-V2.5-ASR — Reconocimiento de voz de extremo a extremo que admite dialectos chinos (Wu, cantonés, hokkien, sichuanés), habla con alternancia de códigos, letras de canciones y entornos acústicos ruidosos.
Ambos modelos insignia comparten una tecnología propia. atención híbrida de ventana deslizante Arquitectura heredada de MiMo-V2-Flash, con codificadores visuales y de audio dedicados conectados a través de proyectores ligeros. Ambos se envían con un nativo Ventana de contexto de 1.048.576 tokensNinguno de los dos cobra un multiplicador de longitud de contexto; Xiaomi lo eliminó el día del lanzamiento.
MiMo V2.5 vs Claude Opus, Gemini 3 Pro, GPT-5.4
El principal referente —y con el que Xiaomi lideró el lanzamiento— es Evaluación de garras, un conjunto de tareas agenciales de múltiples turnos donde el modelo tiene que planificar, llamar a herramientas e iterar en horizontes largos. Esto es el Se trata de un punto de referencia que se corresponde con las cargas de trabajo reales de los agentes en producción, y es ahí donde MiMo V2.5 parece mostrar su mayor potencial.
| Modelo | Pase ClawEval³ | Tokens / Trayectoria | Clasificación ajustada al costo |
|---|---|---|---|
| MiMo V2.5-Pro | 63,8 – 64,0% | ~70 mil | #1 (Frontera de Pareto) |
| MiMo V2.5 (base) | 62,3% | ~75 mil | frontera atada |
| Claude Opus 4.6 | ~65,4% | ~120–175 mil | Mayor costo |
| Gemini 3.1 Pro | ~63% | ~115 mil | Mayor costo |
| GPT-5.4 | ~62% | ~110 mil | Mayor costo |
La conclusión: Claude Opus 4.6 aún tiene una ligera ventaja en cuanto a capacidad bruta., pero MiMo V2.5-Pro llega al mismo vecindario gastando aproximadamente entre un 40 y un 60 % menos de tokens para llegar allí. En términos de precios por trayectoria, esto es no un error de redondeo. Como VentureBeat señalóEn un mundo donde GitHub Copilot y la mayoría de las plataformas de agentes están adoptando la facturación basada en el uso, esta eficiencia del token se traduce directamente en dinero real para cualquier equipo que gestione agentes a gran escala.
En otros aspectos, la imagen muestra a un especialista en codificación como prioridad:
- SWE-bench Pro:
57,2%— a medio punto de Claude Opus 4.6 y GPT-5.4. - Terminal-Bench 2.0: Supera con creces a Opus 4.6 y Gemini 3.1 Pro.
- Vídeo-MME:
87.7— a la par con Gemini 3 Pro en comprensión de vídeo. - GDPVal-AA (Elo):
1581— supera a Kimi K2.6 y GLM 5.1. - Recuerdo de contexto extenso (1M):
0,37 BFS / 0,62 Padres— donde la mayoría de los competidores se desploman hasta casi cero después de los 512.000.
En qué falla: HLE (El último examen de la humanidad) y Razonamiento amplio de GDPVal-AA Ambos modelos priorizan la amplitud de conocimientos generales sobre la profundidad de los especialistas en programación. Si necesitas un tutor o un experto en diversas áreas, este no es el modelo adecuado. Si necesitas un agente que implemente código, sin duda lo es.
¿Qué puede hacer realmente el MiMo V2.5-Pro?
Los benchmarks son una cosa. Xiaomi fue más allá y publicó cuatro ejecuciones de tareas autónomas de varias horas — el tipo de trabajo en el que no se puede guiar al agente paso a paso. Estas son las demostraciones que merecen ser tomadas en serio, porque incluyen el registro completo de llamadas a la herramienta.
La ejecución del compilador de Rust es la que hay que comprender a fondo. No es un juguete. Es un proyecto real de un curso de la PKU con un conjunto de pruebas oculto y real, y un modelo de código cerrado de vanguardia habría tenido dificultades para hacerlo de una sola vez con ese presupuesto mínimo. Así es como se ve en la práctica la frase "coherencia a largo plazo".
Precios de MiMo V2.5 y por qué es la verdadera historia
Aquí es donde el posicionamiento de código abierto se vuelve interesante. MiMo V2.5 se distribuye bajo Pesas abiertas en Hugging Face Xiaomi ofrece soluciones de autoalojamiento, pero también gestiona una API alojada con precios competitivos y un modelo de suscripción "Token Plan" que imita las ofertas de tarifa plana de Claude Code y OpenAI.
Dos cosas a tener en cuenta: los aciertos de caché reducen el costo de entrada a un nivel tan bajo como $0.20–0.40 por millón de tokens, y Xiaomi hizo escritura en caché gratis para una ventana de lanzamiento limitada. El multiplicador de 1M contexto también ha desaparecido. Si está ejecutando agentes de largo horizonte, la brecha de costos real en comparación con los modelos de frontera de código cerrado es más cercana a 10× que 5×.
Para los equipos que prefieren una tarifa plana, el sistema de cuatro niveles Plan de tokens va desde $63.36/año (Lite, 720M créditos) a $1.056/año (Máximo, 19.200 millones de créditos) — y es compatible con Claude Code, OpenCode y Kilo como estructuras predefinidas.
¿Deberías usar MiMo V2.5? Ventajas, desventajas y a quién va dirigido.
Fortalezas
- La mejor eficiencia de tokens de su clase en tareas con agentes (entre un 40 % y un 60 % menos de tokens que Claude Opus 4.6).
- Contexto utilizable genuino de 1 millón de tokens: no se desploma más allá de 512.000 como la mayoría de sus competidores.
- Multimodal nativo en un solo modelo (imagen, vídeo, audio, texto).
- Pesos abiertos en Hugging Face: autoalojados y ajustables.
- "Aprovechar la conciencia situacional": gestiona activamente su propio contexto a través de miles de llamadas a herramientas.
- Compatible directamente con Claude Code, OpenCode y Kilo.
Debilidades
- Pruebas basadas en criterios de razonamiento amplio (HLE, GDPVal-AA): diseño que prioriza la codificación.
- Las cifras autodeclaradas sobre la eficiencia de los tokens necesitan ser replicadas de forma independiente.
- La infraestructura alojada fuera de China aún está en desarrollo; la latencia varía.
- El ecosistema de llamadas a herramientas y las integraciones de arneses están menos probados en combate que Claude o GPT.
- La documentación y el apoyo de la comunidad aún están por debajo de los de los proveedores occidentales.
¿Quién debería usar MiMo V2.5?
Si estás construyendo flujos de trabajo de codificación agencial — Si su economía unitaria depende del costo del token, MiMo V2.5-Pro está ahora en la lista de opciones. Lo mismo ocurre con cualquier equipo que utilice agentes multimodales con un alto nivel de comprensión de vídeo o documentos.
¿Quién debería quedarse con Claude o con GPT?
Si su carga de trabajo principal es Conversación de razonamiento amplio, síntesis de investigación o trabajo de conocimiento generalClaude Opus 4.7 y GPT-5.5 siguen siendo superiores. Los modelos occidentales también cuentan con ecosistemas de herramientas más maduros, un historial más extenso de estabilidad bajo cargas de producción y mayores garantías en el manejo de datos empresariales.
Preguntas frecuentes
¿Es MiMo V2.5 realmente de código abierto?
¿Es MiMo V2.5 mejor que Claude Opus 4.7?
¿Cuánto cuesta MiMo V2.5 a través de API?
¿Puedo usar MiMo V2.5 con Claude Code u OpenCode?
¿Qué hardware necesito para alojar MiMo V2.5 en mi propio servidor?
¿Qué es "aprovechar la conciencia" y por qué es importante?
La frontera del código abierto acaba de cambiar.
MiMo V2.5 no reemplaza a Claude Opus para todas las cargas de trabajo, pero para la codificación automatizada a gran escala, es el nuevo líder en relación calidad-precio, y la brecha con la frontera del software de código cerrado está oficialmente al alcance de la mano. Haremos un seguimiento de la replicación en entornos reales, las comparativas de terceros y la adopción por parte del ecosistema a medida que evolucione.