 OpenAI - ChatGPT, Sora
OpenAI - ChatGPT, Sora Google - Gemini, Nano Banane
Google - Gemini, Nano Banane Anthropic - Claude
Anthropic - Claude xAI - Grok
xAI - Grok Deepseek
Deepseek Alibaba - Qwen
Alibaba - Qwen ByteDance – Das Beste von ByteDance
ByteDance – Das Beste von ByteDance Alle Modelle
Alle Modelle Unternehmenspläne
Unternehmenspläne KI-Anwendungsentwicklung
KI-Anwendungsentwicklung KI-Übersetzer-API
KI-Übersetzer-API KI-SEO/GEO-Dienst
KI-SEO/GEO-Dienst Geooptimierter PR-Service
Geooptimierter PR-Service Web-Scraping-Dienst
Web-Scraping-Dienst OpenClaw
OpenClaw Die besten KI-Tools
Die besten KI-Tools Top-KI-Roboter
Top-KI-Roboter
 Einloggen
Einloggen














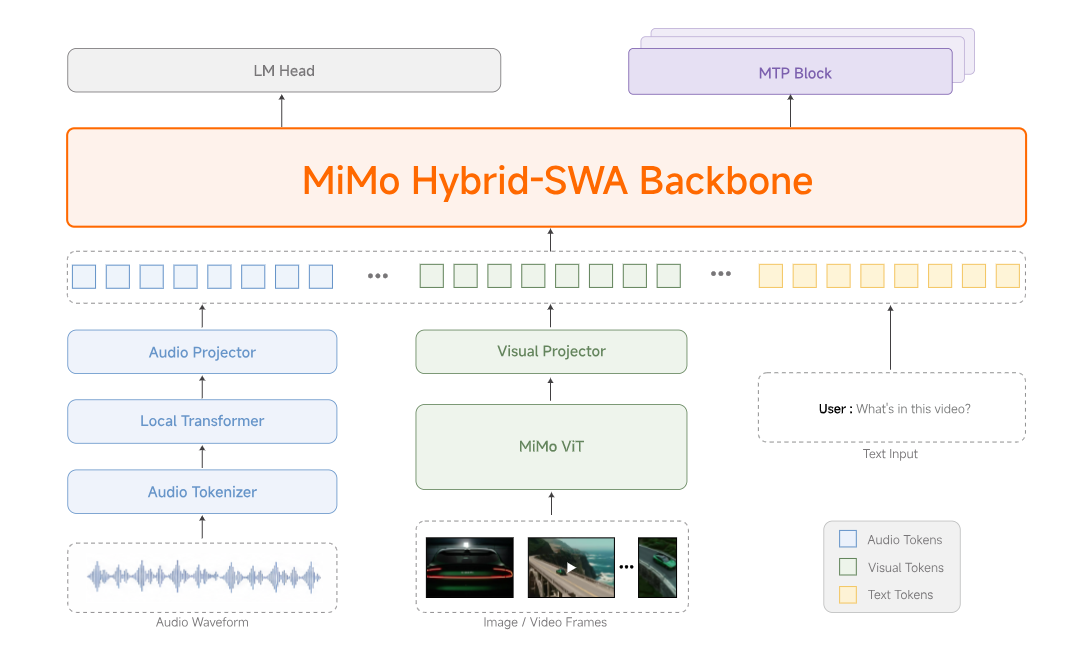
Xiaomi MiMo V2.5:
Das Modell 310B, das gerade aufgeholt aß Claude Opus auf Token-Effizienz.
Xiaomis MiMo V2.5 ist die bedeutendste Open-Wight-Veröffentlichung des zweiten Quartals 2026 – ein 310 Milliarden Token umfassendes Sparse-Mixture-of-Experts-Modell mit nativem multimodalen Verständnis, einem Kontextfenster von 1 Million Token und Benchmark-Ergebnissen, die es auf Augenhöhe mit Claude Opus und Gemini 3 Pro bringen, während es gleichzeitig … 40–60 % weniger TokenHier die vollständige Aufschlüsselung: Architektur, Benchmarks, reale Aufgaben, Preisgestaltung und wie es sich im Vergleich zu proprietären Produkten schlägt.

Was ist Xiaomi MiMo V2.5?
MiMo V2.5 ist die neueste Modellfamilie von Xiaomis MiMo-Team, veröffentlicht Ende April 2026 und direkt auf Umarmendes Gesicht als offene Gewichte. Tatsächlich gibt es zwei Flaggschiffmodelle im Angebot, dazu eine TTS-Suite und ein ASR-Modell – und diese Unterscheidung ist wichtig, da sie im Online-Hype meist verwechselt werden.
Die Linie teilt sich folgendermaßen auf:
- MiMo-V2.5 — Der multimodale Generalist „Omni“.
310B Gesamtparameter,15B aktivSparse MoE-Architektur, trainiert mit 48T Tokens. Native Bild- und Audioerkennung. Ein Alleskönner. - MiMo-V2.5-Pro — Der "Agent"-Spezialist.
1,02T Gesamtparameter,42B aktiv. Gleiches hybrides Aufmerksamkeits-Backbone, aber speziell für langfristiges Codieren und Trajektorien mit Tausenden von Toolaufrufen optimiert. - MiMo-V2.5-TTS — Eine dreiteilige Sprachsuite (TTS, VoiceDesign, VoiceClone) zur Erzeugung von Produktionssprachsignalen mit Stilvorgaben zur Steuerung von Geschwindigkeit, Emotion und Tonfall.
- MiMo-V2.5-ASR — End-to-End-Spracherkennung, die chinesische Dialekte (Wu, Kantonesisch, Hokkien, Sichuanisch), Code-Switching-Sprache, Liedtexte und laute akustische Umgebungen verarbeitet.
Beide Flaggschiffmodelle verfügen über eine hauseigene hybride Sliding-Window-Aufmerksamkeit Die Architektur wurde von MiMo-V2-Flash übernommen, mit dedizierten visuellen und Audio-Encodern, die über leichte Projektoren verbunden sind. Beide werden mit einer nativen Kontextfenster mit 1.048.576 TokenBeide erheben keinen Kontextlängenmultiplikator – Xiaomi hat dies zum Verkaufsstart entfernt.
MiMo V2.5 vs Claude Opus, Gemini 3 Pro, GPT-5.4
Der wichtigste Benchmark – und derjenige, mit dem Xiaomi die Markteinführung eröffnete – ist ClawEval, eine mehrstufige, agentenbasierte Aufgabensuite, in der das Modell planen, Werkzeuge aufrufen und über lange Zeiträume iterativ vorgehen muss. Dies ist Die Benchmark, der realen Produktions-Agenten-Workloads entspricht, und genau da zeigt MiMo V2.5 seine Stärken.
| Modell | ClawEval Pass³ | Tokens / Trajektorie | Kostenbereinigter Rang |
|---|---|---|---|
| MiMo V2.5-Pro | 63,8 – 64,0 % | ~70.000 | #1 (Pareto-Front) |
| MiMo V2.5 (Basis) | 62,3 % | ~75.000 | Gebundene Grenze |
| Claude Opus 4.6 | ~65,4 % | ~120–175K | Höhere Kosten |
| Gemini 3.1 Pro | ~63% | ~115K | Höhere Kosten |
| GPT-5.4 | ~62% | ~110K | Höhere Kosten |
Fazit: Claude Opus 4.6 hat in puncto Rohkapazität immer noch einen leichten Vorteil.MiMo V2.5-Pro erreicht ähnliche Werte, benötigt dafür aber etwa 40–60 % weniger Token. Betrachtet man den Preis pro Flugbahn, so ist dies nicht ein Rundungsfehler. VentureBeat stellte fest:In einer Welt, in der GitHub Copilot und die meisten Agentenplattformen auf nutzungsbasierte Abrechnung umstellen, lässt sich diese Token-Effizienz direkt in echtes Geld für jedes Team umsetzen, das Agenten in großem Umfang einsetzt.
In anderen Bereichen zeichnet sich das Bild eines Spezialisten ab, der sich auf das Programmieren konzentriert:
- SWE-bench Pro:
57,2 %— innerhalb eines halben Punktes von Claude Opus 4.6 und GPT-5.4. - Terminal-Bench 2.0: Fügt Opus 4.6 und Gemini 3.1 Pro komplett an.
- Video-MME:
87,7— gleichwertig mit dem Gemini 3 Pro in Bezug auf Videoverständnis. - GDPVal-AA (Elo):
1581— übertrifft Kimi K2.6 und GLM 5.1. - Langzeitkontext-Erinnerung (1M):
0,37 BFS / 0,62 Eltern— wo die meisten Konkurrenten jenseits der 512.000er-Marke auf nahezu Null einbrechen.
Wo es Mängel aufweist: HLE (Die letzte Prüfung der Menschheit) Und GDPVal-AA breite Argumentation Beide Modelle belohnen allgemeines Wissen gegenüber spezialisierten Programmierkenntnissen. Wenn Sie einen Tutor oder ein Universalgenie benötigen, ist dies nicht das richtige Modell für Sie. Wenn Sie jedoch einen Agenten brauchen, der Code liefert, ist es genau das Richtige.
Was kann MiMo V2.5-Pro eigentlich leisten?
Benchmarks sind das eine. Xiaomi ging noch einen Schritt weiter und veröffentlichte vier. mehrstündige autonome Aufgabenläufe — also Aufgaben, bei denen der Agent nicht an die Hand genommen werden kann. Diese Demos sollte man ernst nehmen, da sie die vollständige Ablaufverfolgung der Toolaufrufe beinhalten.
Der Rust-Compilerlauf ist derjenige, den man verinnerlichen muss. Er ist kein Spielzeug. Es handelt sich um ein echtes PKU-Kursprojekt mit einer echten, versteckten Testsuite, und ein zukunftsweisendes Closed-Source-Modell hätte mit diesem Budget Schwierigkeiten gehabt, dies auf einmal zu schaffen. So sieht der Begriff „langfristige Kohärenz“ in der Praxis aus.
Preisgestaltung des MiMo V2.5 – und warum das die eigentliche Geschichte ist
Hier wird die Positionierung als Open-Source-Projekt interessant. MiMo V2.5 wird unter folgender Bezeichnung ausgeliefert: Offene Gewichte auf Hugging Face Für das Selbsthosting bietet Xiaomi eine gehostete API mit aggressiver Preisgestaltung an – sowie ein „Token Plan“-Abonnementmodell, das den Pauschalpreisangeboten von Claude Code und OpenAI ähnelt.
Zwei Dinge sind zu beachten: Cache-Treffer senken die Eingabekosten auf bis zu 0,20–0,40 $ pro Million Tokens, und Xiaomi hat das Cache-Schreiben durchgeführt kostenlos für ein begrenztes Einführungsfenster. Der 1-Millionen-Kontext-Multiplikator ist ebenfalls weggefallen. Wenn Sie Agenten mit langem Zeithorizont einsetzen, liegt die tatsächliche Kostendifferenz gegenüber proprietären Frontier-Modellen näher bei 10× als 5×Die
Für Teams, die eine Pauschalgebühr bevorzugen, gibt es das vierstufige Modell. Token-Plan geht von 63,36 $/Jahr (Lite, 720 Millionen Credits) bis 1.056 $/Jahr (Max, 19,2 Milliarden Credits) — und ist kompatibel mit Claude Code, OpenCode und Kilo als Drop-in-Gerüste.
Sollten Sie MiMo V2.5 verwenden? Vorteile, Nachteile und für wen es geeignet ist.
Stärken
- Erstklassige Token-Effizienz bei agentenbasierten Aufgaben (40–60 % weniger Token als Claude Opus 4.6).
- Echter nutzbarer Kontext für 1 Million Token – bricht nicht wie bei den meisten Konkurrenten bei 512.000 zusammen.
- Native Multimodalität in einem einzigen Modell (Bild, Video, Audio, Text).
- Offene Gewichte auf Hugging Face — selbst hostbar, feinabstimmbar.
- „Harness awareness“ – verwaltet aktiv seinen eigenen Kontext über Tausende von Toolaufrufen hinweg.
- Direkt kompatibel mit Claude Code, OpenCode, Kilo.
Schwächen
- Tests zu Benchmarks für breites logisches Denken (HLE, GDPVal-AA) — von Grund auf codierungsorientiert.
- Die selbstberichteten Daten zur Token-Effizienz müssen unabhängig repliziert werden.
- Die außerhalb Chinas gehostete Infrastruktur ist noch im Aufbau – die Latenz variiert.
- Das Tool-Call-Ökosystem und die Harness-Integrationen sind weniger praxiserprobt als bei Claude oder GPT.
- Dokumentation und Community-Unterstützung hinken westlichen Anbietern noch hinterher.
Wer sollte MiMo V2.5 verwenden?
Wenn Sie bauen agentenbasierte Codierungs-Workflows – Langfristig orientiert, vielseitig einsetzbar, skalierbar für Repositories – und Ihre Stückkosten hängen von den Tokenkosten ab: MiMo V2.5-Pro gehört nun zu den Top-Lösungen. Gleiches gilt für jedes Team, das multimodale Agenten mit umfassender Video- oder Dokumentenanalyse einsetzt.
Wer sollte bei Claude oder GPT bleiben?
Wenn Ihre Hauptarbeitsbelastung Diskussion über allgemeines Denken, Forschungssynthese oder allgemeine WissensarbeitClaude Opus 4.7 und GPT-5.5 sind weiterhin führend. Die westlichen Modelle verfügen zudem über ausgereiftere Tool-Ökosysteme, eine längere Stabilitätshistorie unter Produktionslast und stärkere Garantien für die Verarbeitung von Unternehmensdaten.
Häufig gestellte Fragen
Ist MiMo V2.5 tatsächlich Open Source?
Ist MiMo V2.5 besser als Claude Opus 4.7?
Wie viel kostet MiMo V2.5 über die API?
Kann ich MiMo V2.5 mit Claude Code oder OpenCode verwenden?
Welche Hardware benötige ich, um MiMo V2.5 selbst zu hosten?
Was ist „Gefahrenbewusstsein“ und warum ist es wichtig?
Die Open-Source-Grenze hat sich verschoben.
MiMo V2.5 ist zwar kein vollwertiger Ersatz für Claude Opus, aber für agentenbasierte Programmierung im großen Maßstab ist es der neue, kostengünstige Marktführer, und der Abstand zu proprietären Lösungen ist praktisch aufgeholt. Wir werden die praktische Anwendung, Benchmarks von Drittanbietern und die Akzeptanz im Ökosystem weiter beobachten.