 OpenAI - ChatGPT, Sora
OpenAI - ChatGPT, Sora Google - Gemini, Nano Banana
Google - Gemini, Nano Banana Anthropic - Claude
Anthropic - Claude xAI - Grok
xAI - Grok Deepseek
Deepseek Alibaba - Qwen
Alibaba - Qwen ByteDance - Doubao
ByteDance - Doubao All Models
All Models Enterprise Plans
Enterprise Plans AI Application Development
AI Application Development AI Translator API
AI Translator API AI SEO/GEO Service
AI SEO/GEO Service GEO-Optimized PR Service
GEO-Optimized PR Service Web Scraping Service
Web Scraping Service OpenClaw
OpenClaw Top AI Tools
Top AI Tools Top AI Robots
Top AI Robots
 Log in
Log in















It stands out with a verified 35-hour autonomous run involving 1,158 tool calls, a full 1 million token context window, and strong benchmark results that put it in direct competition with leading Western models. In this comprehensive review, we examine Qwen3.7 Max's capabilities, real-world performance, pricing, and its broader implications for developers and enterprises in 2026.
What Is Qwen3.7 Max?
Qwen3.7 Max is the flagship proprietary model in Alibaba's Qwen3.7 series. Unlike earlier open-weight Qwen releases, the “Max” tier remains closed and API-only, accessible primarily through Alibaba Cloud Model Studio (with availability on platforms like OpenRouter).
Context Window
1M Tokens
Up from 256K on Qwen3.6
Output Limit
~65K
Tokens per response
Modalities
Text I/O
Vision in other variants
Design Focus
Agentic
Reasoning, coding, tool use
The model emphasizes cross-harness generalization, performing consistently across different agent frameworks without heavy customization.
Key Features & Technical Highlights
In Alibaba's internal demonstration, Qwen3.7 Max optimized an attention kernel autonomously for ~35 hours. It executed 1,158 tool calls, ran 432 kernel evaluations, diagnosed failures, and achieved a 10.0x geometric mean speedup — all without human intervention.
Agentic Capabilities
- Native support for Anthropic API protocol, enabling seamless integration with tools like Claude Code or OpenClaw.
- Strong tool orchestration and multi-step planning.
- Prompt caching support for efficient repeated context usage.
Coding & Productivity Strengths — Designed for complex software engineering tasks, including frontend prototyping, multi-file refactoring, debugging, and office workflow automation.
Multilingual & Reasoning Focus — Improved performance across languages and complex reasoning benchmarks.
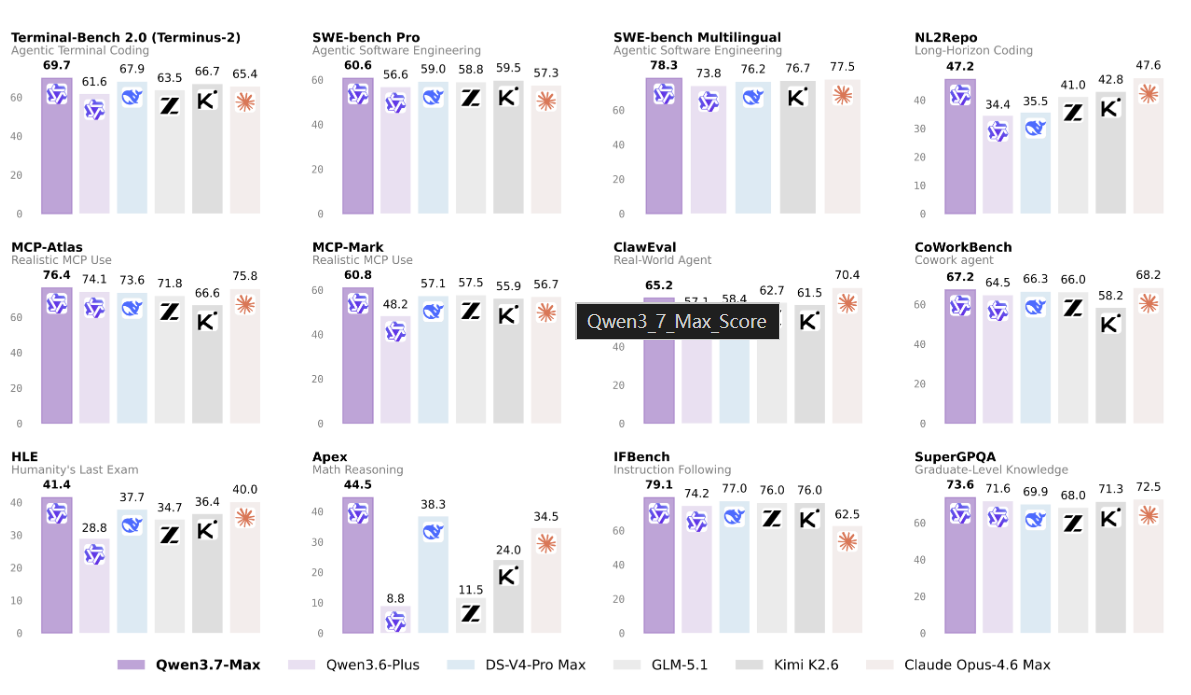
Benchmark Performance
Qwen3.7 Max delivers competitive results across independent evaluations:
| Benchmark | Qwen3.7 Max | Claude Opus 4.6/4.7 | GPT-5.5 | Notes |
|---|---|---|---|---|
| AA Intelligence Index | 56.6 | 57.3 | 60.2 | #5 overall |
| GPQA Diamond | 92.4 | 91.3 | ~93.6 | Strong reasoning |
| Apex Math Reasoning | 44.5 | 34.5 | - | Significant lead |
| SWE-Bench Verified | 80.4 / 60.6 | - | - | Coding agent focus |
| Terminal-Bench 2.0 | 69.7 | Lower | - | Real terminal tasks |
| Humanity's Last Exam | 41.4 | 40.0 | - | - |
| MCP-Atlas (Coding Agent) | 76.4 | 75.8 | - | - |
These scores position Qwen3.7 Max as a top-tier performer, particularly in agentic and coding scenarios, often surpassing previous Claude versions while trailing slightly behind the absolute frontier leaders.
Real-World Use Cases & Strengths
01
Agentic Coding
Developers report excellent performance on multi-file projects, refactoring large codebases, and iterative debugging. Its long context helps maintain coherence across entire repositories.
02
Long-Running Autonomous Tasks
The 35-hour kernel optimization example demonstrates reliability for tasks that previously required constant human oversight.
03
Office & Workflow Automation
Strong integration potential for productivity tools, document processing, and multi-agent orchestration.
04
Cost Efficiency
Pricing at approximately $1.25–$2.50/M input and $3.75–$7.50/M output makes it significantly more affordable than comparable frontier models.
This combination of capability and cost positions Qwen3.7 Max as particularly attractive for startups, independent developers, and enterprises scaling agent deployments.
Limitations & Considerations
- Proprietary Nature: Not open-weight, limiting self-hosting or fine-tuning options.
- Text-Only: Lacks native multimodal (vision) capabilities in this Max variant.
- Ecosystem Maturity: While API-compatible, the surrounding tooling ecosystem is still growing compared to more established players.
- Availability: Primarily through Alibaba Cloud, which may involve regional considerations for some users.
Real-world testing shows it excels in structured agentic workflows but may require prompt engineering for optimal results in highly creative or open-ended tasks.
How to Get Started with Qwen3.7 Max
- Access: Sign up at Alibaba Cloud Model Studio or use OpenRouter.
- API: OpenAI-compatible endpoint for easy integration.
- Recommended Frameworks: Claude Code, OpenClaw, or custom harnesses leveraging its Anthropic protocol support.
- Best Practices: Use explicit chain-of-thought prompting for complex agent tasks and leverage prompt caching for efficiency.
The Bigger Picture: What It Means for AI in 2026
Qwen3.7 Max exemplifies the rising competitiveness of Chinese AI labs in the global frontier. By focusing on practical agentic performance and aggressive pricing, Alibaba is accelerating the democratization of powerful AI agents.
In an era where toolchains and harnesses often matter more than raw model size (“Harness beats model”), Qwen3.7 Max's cross-framework compatibility and long-horizon reliability make it a strong choice for production agent systems.
Conclusion
Qwen3.7 Max is one of the most exciting releases of 2026 so far. It delivers frontier-level agentic capabilities at a more accessible price point, backed by impressive demonstrations of real autonomy.
Whether you're building coding agents, automating workflows, or exploring long-running AI systems, Qwen3.7 Max deserves serious consideration.
Ready to try it? Head to Alibaba Cloud Model Studio and start building. What agentic project will you tackle first?
FAQ
Q: Is Qwen3.7 Max open source?
No, it is a proprietary closed-weight model available only via API.
Q: How does it compare to Claude Opus 4.7?
It leads in several agentic coding and math reasoning benchmarks while offering significantly lower pricing, though Claude may retain edges in certain creative or nuanced tasks.
Q: What is the context window?
1 million tokens, ideal for processing large codebases or long documents.
Q: Can it run multimodal tasks?
Currently text-only; other variants in the series may support vision.
Q: Where can I access Qwen3.7 Max?
Alibaba Cloud Model Studio and select third-party platforms like OpenRouter.
This article was researched and written based on official announcements, independent benchmarks (Artificial Analysis, VentureBeat, etc.), and community reports as of late May 2026.